简单python爬虫案例(爬取慕课网全部实战课程信息)
技术选型
下载器是Requests
解析使用的是正则表达式
效果图:

准备好各个包
# -*- coding: utf-8 -*-
import requests #第三方下载器
import re #正则表达式
import json #格式化数据用
from requests.exceptions import RequestException #做异常处理
from multiprocessing import Pool #使用多进程
开始编写代码,new一个py文件
1.requests下载页面
response =requests.get(url)
url:当前需要爬取的链接
requests.get()获取页面
这里需要注意编码的问题;
就像下面这样:
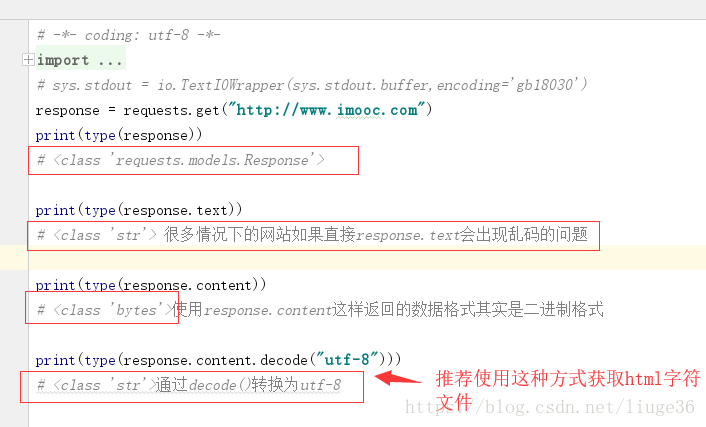
response = requests.get(url)
if response.status_code == 200:
return response.content.decode("utf-8")
return None
这样返回的就是一个string类型的数据
2.except RequestException:捕捉异常
为了代码更加健壮,我们在可能发生异常的地方做异常捕获
try:
response = requests.get(url)
if response.status_code == 200:
return response.content.decode("utf-8")
return None
except RequestException:
return None
更多异常介绍官网
http://www.python-requests.org/en/master/_modules/requests/exceptions/#RequestException
到这里,我们就可以编写main方法进行调用程序了
代码如下:
# -*- coding: utf-8 -*-
import requests
from requests.exceptions import RequestException
def get_one_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.content.decode("utf-8")
return None
except RequestException:
return None
def main():
url = 'https://coding.imooc.com/?page=1'
html = get_one_page(url)
print(html)
if __name__ == '__main__':
main()
这样就可以把页面下载下来了
接着,就是解析页面
3.正则表达式介绍
re.compile()方法:编译正则表达式
通过一个正则表达式字符串 编译生成 一个字符串对象
re.findall(pattern,html)方法:找到所有匹配的内容
参数:
pattern:编译过的正则表达式
html:用response.content.decode("utf-8")得到的页面内容
def parse_one_page(html):
pattern = re.compile('<div class="box">.*?lecturer-info.*?<span>(.*?)</span>.*?shizhan-intro-box.*?title=".*?">'
'(.*?)</p>.*?class="grade">(.*?)</span>.*?imv2-set-sns.*?</i>'
'(.*?)</span>.*?class="big-text">(.*?)</p>.*?shizan-desc.*?>'
'(.*?)</p>.*?</div>',re.S)
items = re.findall(pattern,html)
for item in items:
#格式化每一条数据为字典类型的数据
yield {
'teacher': item[0],
'title': item[1],
'grade': item[2],
'people':item[3],
'score': item[4],
'describe': item[5]
}
完整代码:
# -*- coding: utf-8 -*-
import requests
import re
from requests.exceptions import RequestException
def get_one_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.content.decode("utf-8")
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('<div class="box">.*?lecturer-info.*?<span>(.*?)</span>.*?shizhan-intro-box.*?title=".*?">'
'(.*?)</p>.*?class="grade">(.*?)</span>.*?imv2-set-sns.*?</i>'
'(.*?)</span>.*?class="big-text">(.*?)</p>.*?shizan-desc.*?>'
'(.*?)</p>.*?</div>',re.S)
items = re.findall(pattern,html)
for item in items:
yield {
'teacher': item[0],
'title': item[1],
'grade': item[2],
'people':item[3],
'score': item[4],
'describe': item[5]
}
def main():
url = 'https://coding.imooc.com/?page=1'
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
if __name__ == '__main__':
main()
保存解析后的数据到本地文件
4.保存文件操作
with open('imooctest.txt','a',encoding='utf-8') as f
with as :打开自动闭合的文件并设立对象f进行操作
参数:
imooctest.txt:文件名字
a:追加方式
encoding:编码格式 不这样设置可能保存的数据会乱码
f.write(json.dumps(content,ensure_ascii =False)+'\n')
json.dumps:将刚才被格式化后的字典转为字符串
ensure_ascii =False 不这样设置可能保存的数据会乱码
+'\n' 每条数据为一行
代码如下:
# -*- coding: utf-8 -*-
import requests
import re
import json
from requests.exceptions import RequestException
def get_one_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.content.decode("utf-8")
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('<div class="box">.*?lecturer-info.*?<span>(.*?)</span>.*?shizhan-intro-box.*?title=".*?">'
'(.*?)</p>.*?class="grade">(.*?)</span>.*?imv2-set-sns.*?</i>'
'(.*?)</span>.*?class="big-text">(.*?)</p>.*?shizan-desc.*?>'
'(.*?)</p>.*?</div>',re.S)
items = re.findall(pattern,html)
for item in items:
yield {
'teacher': item[0],
'title': item[1],
'grade': item[2],
'people':item[3],
'score': item[4],
'describe': item[5]
}
def write_to_file(content):
with open('imooctest.txt','a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False)+'\n')
f.close()
def main():
url = 'https://coding.imooc.com/?page=1'
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
main()
5.爬取所有页面并以多进程方式
分析页面,会发现,需要爬取的页面如下
https://coding.imooc.com/?page=1
https://coding.imooc.com/?page=2
https://coding.imooc.com/?page=3
https://coding.imooc.com/?page=4
我们需要构造这种格式的页面
主函数可以类似这样:
for i in range(4):
main(i+1)
完整代码:
# -*- coding: utf-8 -*-
import requests
import re
import json
from requests.exceptions import RequestException
from multiprocessing import Pool
def get_one_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.content.decode("utf-8")
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('<div class="box">.*?lecturer-info.*?<span>(.*?)</span>.*?shizhan-intro-box.*?title=".*?">'
'(.*?)</p>.*?class="grade">(.*?)</span>.*?imv2-set-sns.*?</i>'
'(.*?)</span>.*?class="big-text">(.*?)</p>.*?shizan-desc.*?>'
'(.*?)</p>.*?</div>',re.S)
items = re.findall(pattern,html)
for item in items:
yield {
'teacher': item[0],
'title': item[1],
'grade': item[2],
'people':item[3],
'score': item[4],
'describe': item[5]
}
def write_to_file(content):
with open('imoocAll.txt','a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False)+'\n')
f.close()
def main(page):
url = 'https://coding.imooc.com/?page='+str(page)
html = get_one_page(url)
# parse_one_page(html)
# print(html)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
pool = Pool()
pool.map(main,[i+1 for i in range(4)])
# for i in range(4):
# main(i+1)
到这里,我们就能够把慕课网上面的全部实战课程的信息爬取下来,拿到这些数据,你就可以做自己喜爱的分析了
简单python爬虫案例(爬取慕课网全部实战课程信息)的更多相关文章
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- python 爬虫之爬取大街网(思路)
由于需要,本人需要对大街网招聘信息进行分析,故写了个爬虫进行爬取.这里我将记录一下,本人爬取大街网的思路. 附:爬取得数据仅供自己分析所用,并未用作其它用途. 附:本篇适合有一定 爬虫基础 crawl ...
- Python爬虫项目--爬取自如网房源信息
本次爬取自如网房源信息所用到的知识点: 1. requests get请求 2. lxml解析html 3. Xpath 4. MongoDB存储 正文 1.分析目标站点 1. url: http:/ ...
- Python爬虫,爬取腾讯漫画实战
先上个爬取的结果图 最后的结果为每部漫画按章节保存 运行环境 IDE VS2019 Python3.7 先上代码,代码非常简短,包含空行也才50行,多亏了python强大的库 import os im ...
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- 网络爬虫之定向爬虫:爬取当当网2015年图书销售排行榜信息(Crawler)
做了个爬虫,爬取当当网--2015年图书销售排行榜 TOP500 爬取的基本思想是:通过浏览网页,列出你所想要获取的信息,然后通过浏览网页的源码和检查(这里用的是chrome)来获相关信息的节点,最后 ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
随机推荐
- 设计模式(C#)——07装饰者模式
推荐阅读: 我的CSDN 我的博客园 QQ群:704621321 在一款战斗类的游戏中,随着故事情节的发展,玩家(即游戏中的主角,下文统一为主角)通常会解锁一些新技能.最初主角只有使 ...
- 六.html基础
web前端前几个月学过一段时间,现在在学习一遍,当作复习,最重要的看看web渗透常用的标签! <html></html> 不带任何属性 <body></bo ...
- BZOJ-2743: [HEOI2012]采花 前缀和 树状数组
BZOJ-2743 LUOGU:https://www.luogu.org/problemnew/show/P4113 题意: 给一个n长度的序列,m次询问区间,问区间中出现两次及以上的数字的个数.n ...
- HDU 5324 Boring Class CDQ分治
题目传送门 题目要求一个3维偏序点的最长子序列,并且字典序最小. 题解: 这种题目出现的次数特别多了.如果不需要保证字典序的话直接cdq就好了. 这里需要维护字典序的话,我们从后往前配对就好了,因为越 ...
- lightoj 1036 - A Refining Company(简单dp)
题目链接:http://www.lightoj.com/volume_showproblem.php?problem=1036 题解:设dp[i][j]表示处理到(i,j)点时的最大值然后转移显然是 ...
- hdu 1182 A Bug's Life(简单种类并查集)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1829 题意:就是给你m条关系a与b有性关系,问这些关系中是否有同性恋 这是一道简单的种类并查集,而且也 ...
- 2018湖南多校第二场-20180407 Barareh on Fire
Description The Barareh village is on fire due to the attack of the virtual enemy. Several places ar ...
- CF940A Points on the line 思维
A. Points on the line time limit per test 1 second memory limit per test 256 megabytes input standar ...
- ets查询接口match、select说明
ets:match/2用法:match(Tab, Pattern) -> [Match]返回和模式Pattern匹配的对象.一个匹配模式可能包含:绑定部分.'_'匹配任何Erlang项和匹配变量 ...
- Linux入门基础之一
Linux 入门基础 一.Linux 系统安装 安装方法网上很多,请自行百度 二.Linux 基本操作 2.1.GNOME图形界面基本操作 操作类似于Windows系统操作 打开每一个文件夹都会打开一 ...