spark graphX作图计算
一、使用graph做好友推荐

import org.apache.spark.graphx.{Edge, Graph, VertexId}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//求共同好友
object CommendFriend {
def main(args: Array[String]): Unit = {
//创建入口
val conf: SparkConf = new SparkConf().setAppName("CommendFriend").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
//点的集合
//点
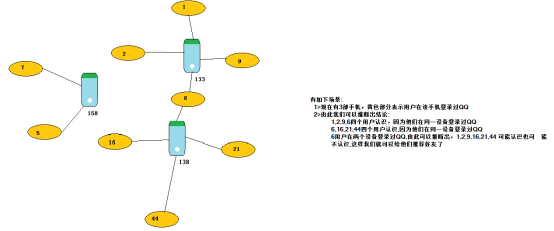
val uv: RDD[(VertexId,(String,Int))] = sc.parallelize(Seq(
(133, ("毕东旭", 58)),
(1, ("贺咪咪", 18)),
(2, ("范闯", 19)),
(9, ("贾璐燕", 24)),
(6, ("马彪", 23)),
(138, ("刘国建", 40)),
(16, ("李亚茹", 18)),
(21, ("任伟", 25)),
(44, ("张冲霄", 22)),
(158, ("郭佳瑞", 22)),
(5, ("申志宇", 22)),
(7, ("卫国强", 22))
))
//边的集合
//边Edge
val ue: RDD[Edge[Int]] = sc.parallelize(Seq(
Edge(1, 133,0),
Edge(2, 133,0),
Edge(9, 133,0),
Edge(6, 133,0),
Edge(6, 138,0),
Edge(16, 138,0),
Edge(44, 138,0),
Edge(21, 138,0),
Edge(5, 158,0),
Edge(7, 158,0)
))
//构建图(连通图)
val graph: Graph[(String, Int), Int] = Graph(uv,ue)
//调用连通图算法
graph
.connectedComponents()
.vertices
.join(uv)
.map{
case (uid,(minid,(name,age)))=>(minid,(uid,name,age))
}.groupByKey()
.foreach(println(_))
//关闭
}
}
二、用户标签数据合并Demo
测试数据
|
陌上花开 旧事酒浓 多情汉子 APP爱奇艺:10 BS龙德广场:8 多情汉子 满心闯 K韩剧:20 满心闯 喜欢不是爱 不是唯一 APP爱奇艺:10 装逼卖萌无所不能 K欧莱雅面膜:5 |
计算结果数据
|
(-397860375,(List(喜欢不是爱, 不是唯一, 多情汉子, 多情汉子, 满心闯, 满心闯, 旧事酒浓, 陌上花开),List((APP爱奇艺,20), (K韩剧,20), (BS龙德广场,8)))) (553023549,(List(装逼卖萌无所不能),List((K欧莱雅面膜,5)))) |
import org.apache.spark.graphx.{Edge, Graph, VertexId}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object UserRelationDemo {
def main(args: Array[String]): Unit = {
//创建入口
val conf: SparkConf = new SparkConf().setAppName("CommendFriend").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
//读取数据
val rdd: RDD[String] = sc.textFile("F:\\dmp\\graph")
//点的集合
val uv: RDD[(VertexId, (String, List[(String, Int)]))] = rdd.flatMap(line => {
val arr: Array[String] = line.split(" ")
val tags: List[(String, Int)] = arr.filter(_.contains(":")).map(tagstr => {
val arr: Array[String] = tagstr.split(":")
(arr(0), arr(1).toInt)
}).toList
val filterd: Array[String] = arr.filter(!_.contains(":"))
filterd.map(nickname => {
if(nickname.equals(filterd(0))) {
(nickname.hashCode.toLong, (nickname, tags))
}else{
(nickname.hashCode.toLong, (nickname, List.empty))
}
})
})
//边的集合
val ue: RDD[Edge[Int]] = rdd.flatMap(line => {
val arr: Array[String] = line.split(" ")
val filterd: Array[String] = arr.filter(!_.contains(":"))
filterd.map(nickname => Edge(filterd(0).hashCode.toLong, nickname.hashCode.toLong, 0))
})
//构建图
val graph: Graph[(String, List[(String, Int)]), Int] = Graph(uv,ue)
//连通图算法找关系
graph
.connectedComponents()
.vertices
.join(uv)
.map{
case (uid,(minid,(nickname,list))) => (minid,(List(uid),List(nickname),list))
}
.reduceByKey{
case (t1,t2) =>
(
t1._1++t2._1 distinct ,
t1._2++t2._2 distinct,
t1._3++t2._3.groupBy(_._1).mapValues(_.map(_._2).reduce(_+_))
//.groupBy(_._1).mapValues(_.map(_._2).sum)
// list.groupBy(_._1).mapValues(_.map(_._2).foldLeft(0)(_+_))
)
}
.foreach(println(_))
//关闭
sc.stop()
}
}
三、用户标签数据合并
|
package cn.bw.mock.tags import cn.bw.mock.utils.TagsUtil |
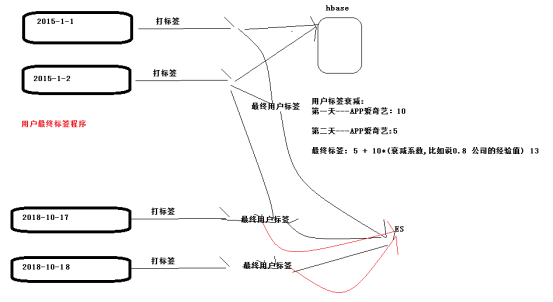
四、用户最终标签和衰减系数
spark graphX作图计算的更多相关文章
- Spark GraphX图计算核心源码分析【图构建器、顶点、边】
一.图构建器 GraphX提供了几种从RDD或磁盘上的顶点和边的集合构建图形的方法.默认情况下,没有图构建器会重新划分图的边:相反,边保留在默认分区中.Graph.groupEdges要求对图进行重新 ...
- Spark GraphX图计算核心算子实战【AggreagteMessage】
一.简介 参考博客:https://www.cnblogs.com/yszd/p/10186556.html 二.代码实现 package graphx import org.apache.log4j ...
- Spark GraphX图计算简单案例【代码实现,源码分析】
一.简介 参考:https://www.cnblogs.com/yszd/p/10186556.html 二.代码实现 package big.data.analyse.graphx import o ...
- Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈与熟练的掌握Scala语言【大数据Spark实战高手之路】
Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈 大数据的概念与应用,正随着智能手机.平板电脑的快速流行而日渐普及,大数据中图的并行化处理一直是一个非常热门的话题.图计算正在被广泛地应用于社交 ...
- 明风:分布式图计算的平台Spark GraphX 在淘宝的实践
快刀初试:Spark GraphX在淘宝的实践 作者:明风 (本文由团队中梧苇和我一起撰写,并由团队中的林岳,岩岫,世仪等多人Review,发表于程序员的8月刊,由于篇幅原因,略作删减,本文为完整版) ...
- 大数据技术之_19_Spark学习_05_Spark GraphX 应用解析 + Spark GraphX 概述、解析 + 计算模式 + Pregel API + 图算法参考代码 + PageRank 实例
第1章 Spark GraphX 概述1.1 什么是 Spark GraphX1.2 弹性分布式属性图1.3 运行图计算程序第2章 Spark GraphX 解析2.1 存储模式2.1.1 图存储模式 ...
- 基于Spark GraphX计算二度关系
关系计算问题描述 二度关系是指用户与用户通过关注者为桥梁发现到的关注者之间的关系.目前微博通过二度关系实现了潜在用户的推荐.用户的一度关系包含了关注.好友两种类型,二度关系则得到关注的关注.关注的好友 ...
- 转载:四两拨千斤:借助Spark GraphX将QQ千亿关系链计算提速20倍
四两拨千斤:借助Spark GraphX将QQ千亿关系链计算提速20倍 时间 2016-07-22 16:57:00 炼数成金 相似文章 (5) 原文 http://www.dataguru.cn/ ...
- Spark GraphX学习资料
<Spark GraphX 大规模图计算和图挖掘> http://book.51cto.com/art/201408/450049.htm http://www.csdn.net/arti ...
随机推荐
- jquery复习
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 品优购(IDEA版)-第一天
# 品优购(IDEA版)-第一天 品优购IDEA版应该是2019年的新项目.目前只有视频.资料其他都还是旧的. ## 1.学习目标 1:了解电商行业特点以及理解电商的模式 2:了解整体品优购的架构特点 ...
- Java基础系列1:Java面向对象
该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架. 概述: Java是面 ...
- 使用promise封装ajax
直接上代码: function Ajax(method, headers, url, data, progress = null) { return new Promise(function (res ...
- Codeforces Round #595 (Div. 3)B2 简单的dfs
原题 https://codeforces.com/contest/1249/problem/B2 这道题一开始给的数组相当于地图的路标,我们只需对每个没走过的点进行dfs即可 #include &l ...
- hydra的使用
hydra参数详解 -R 继续从上一次进度接着破解 -S 大写,采用SSL链接 -s 小写,可通过这个参数指定非默认端口 -l 指定破解的用户,对特定用户破解 -L 指定用户名字典 -p 小写,指定密 ...
- Pandas 转换连接
# 导入相关库 import numpy as np import pandas as pd 拼接 有两个 DataFrame,都存储了用户的一些信息,现在要拼接起来,组成一个 DataFrame. ...
- Spring Boot2 系列教程(二十一)整合 MyBatis
前面两篇文章和读者聊了 Spring Boot 中最简单的数据持久化方案 JdbcTemplate,JdbcTemplate 虽然简单,但是用的并不多,因为它没有 MyBatis 方便,在 Sprin ...
- 【vue】在VS Code中调试Jest单元测试
在VS Code中调试Jest单元测试 添加调试任务 打开 vscode launch.json 文件,在 configurations 内加入下面代码 "configurations&qu ...
- 你知道MySQL中的主从延迟吗?
前言 在一个MySQL主备关系中,每个备库接受主库的binlog并执行. 正常情况下,只要主库执行更新生成所有的binlog,都可以传到备库并被正常的执行,这样备库就能够达到跟主库一样的状态,这就是最 ...