spark集群搭建(三台虚拟机)——spark集群搭建(5)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下:
virtualBox5.2、Ubuntu14.04、securecrt7.3.6_x64英文版(连接虚拟机)
jdk1.7.0、hadoop2.6.5、zookeeper3.4.5、Scala2.12.6、kafka_2.9.2-0.8.1、spark1.3.1-bin-hadoop2.6
本文在前面基础上搭建spark
一、spark1
下面操作在spark1上:
1、spark(spark1.3.1-bin-hadoop2.6)下载解压重命名
2、配置环境变量
export SPARK_HOME=/usr/local/bigdata/spark
export PATH=$PATH:$SPARK_HOME/bin
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
修改配置文件
1、spark-env.sh
$ cd ./spark/conf #进入spark的conf目录下
$ mv spark-env.sh.template spark-env.sh
$ vim spark-env.sh
添加如下配置
export JAVA_HOME=/usr/local/bigdata/jdk
export SCALA_HOME=/usr/local/bigdata/scala
export SPARK_MASTER_IP=192.168.43.XXX
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/local/bigdata/hadoop/etc/hadoop
2、slaves
$ mv slaves.template slaves
$ vim slaves
添加三台主机名
spark1
spark2
spark3
二、spark2和spark3
1、拷贝spark到另外两台机器上
root@spark1:/usr/local/bigdata# scp -r spark root@spark2://usr/local/bigdata/
root@spark1:/usr/local/bigdata# scp -r spark root@spark3://usr/local/bigdata/
2、同理配置spark2和spark3的环境变量,或者直接把环境变量文件拷贝过去
三、启动spark
进入spark的sbin目录下,执行:
$ ./start-all.sh
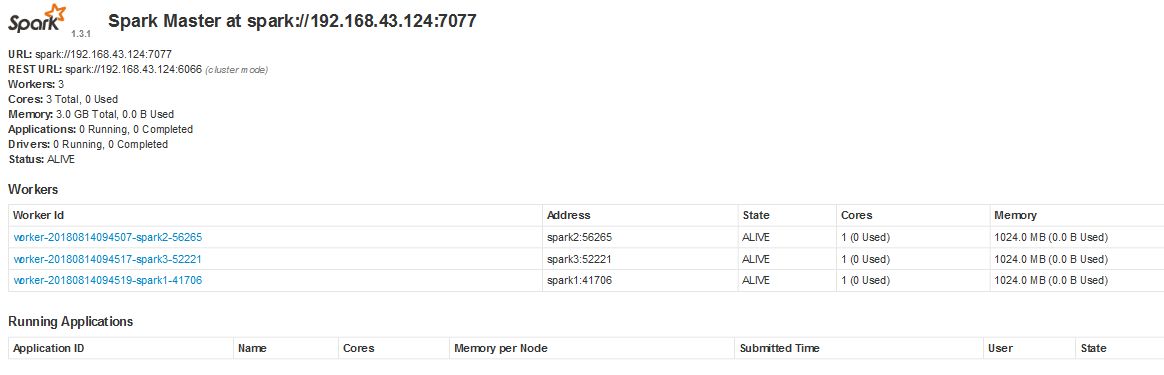
此时查看jps,spark1上有Master
root@spark1:/usr/local/bigdata/spark/sbin# jps
Worker
NodeManager
SecondaryNameNode
Jps
NameNode
Master
ResourceManager
DataNode
spark2
root@spark2:/usr/local/bigdata# jps
Jps
NodeManager
Worker
DataNode
spark3
root@spark3:/usr/local/bigdata# jps
Jps
NodeManager
Worker
DataNode
浏览器输入http://spark1:8080/
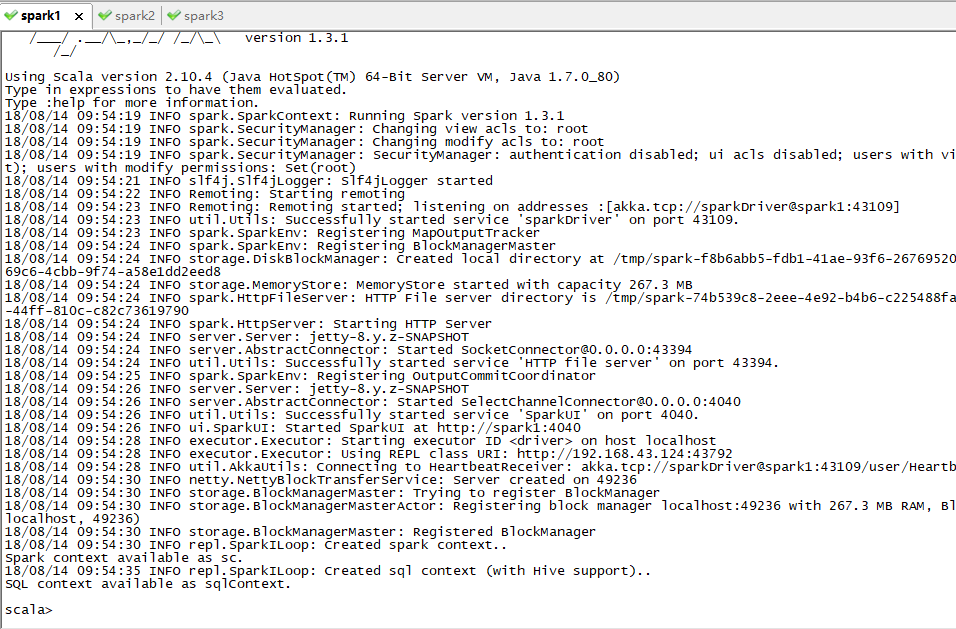
$ spark-shell #进入shell
spark集群搭建(三台虚拟机)——spark集群搭建(5)的更多相关文章
- Centos 7下VMware三台虚拟机Hadoop集群初体验
一.下载并安装Centos 7 传送门:https://www.centos.org/download/ 注:下载DVD ISO镜像 这里详解一下VMware安装中的两个过程 网卡配置 是Add ...
- spark集群搭建(三台虚拟机)——kafka集群搭建(4)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
- spark集群搭建(三台虚拟机)——zookeeper集群搭建(3)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
- spark集群搭建(三台虚拟机)——hadoop集群搭建(2)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
- spark集群搭建(三台虚拟机)——系统环境搭建(1)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
- AWS EC2 搭建 Hadoop 和 Spark 集群
前言 本篇演示如何使用 AWS EC2 云服务搭建集群.当然在只有一台计算机的情况下搭建完全分布式集群,还有另外几种方法:一种是本地搭建多台虚拟机,好处是免费易操控,坏处是虚拟机对宿主机配置要求较高, ...
- Spark学习之路(七)—— 基于ZooKeeper搭建Spark高可用集群
一.集群规划 这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop00 ...
- 用三台虚拟机搭建Hadoop全分布集群
用三台虚拟机搭建Hadoop全分布集群 所有的软件都装在/home/software下 虚拟机系统:centos6.5 jdk版本:1.8.0_181 zookeeper版本:3.4.7 hadoop ...
- 一台虚拟机,基于docker搭建大数据HDP集群
前言 好多人问我,这种基于大数据平台的xxxx的毕业设计要怎么做.这个可以参考之前写得关于我大数据毕业设计的文章.这篇文章是将对之前的毕设进行优化. 个人觉得可以分为两个部分.第一个部分就是基础的平台 ...
随机推荐
- windows下bower init 报错: bower ENOINT Register requires an interactive shell
windows下bower初始化时不应该在git bash中,而应该在cmd下打开的dos窗口中进行
- 后门免杀工具-Backdoor-factory
水一水最近玩的工具 弄dll注入的时候用到的 介绍这款老工具 免杀效果一般..但是简单实用 目录: 0x01 backdoor-factory简介 0x02 特点功能 0x03 具体参数使用 PS: ...
- [JZOJ100047] 【NOIP2017提高A组模拟7.14】基因变异
Description 21 世纪是生物学的世纪,以遗传与进化为代表的现代生物理论越来越多的 进入了我们的视野. 如同大家所熟知的,基因是遗传因子,它记录了生命的基本构造和性能. 因此生物进化与基因的 ...
- Linux::mysql-connector-c++
.安装好boost. .从官网下载mysql connector c++版本. .解压,复制 include/jdbc/cppconn 文件夹复制,到/usr/local/include/cppcon ...
- RIDE的External Resources
External Resources(外部资源):主要指不在project管辖范围内的资源文件. 通俗来说,如果是目录的project,只要不在自己目录范围内的资源文件都算外部资源:如果是文件的pro ...
- 浅谈微服务架构与.Net Core
微服务(microservice)这个概念是2012年出现的,2014年3月Martin Fowler在他的个人网站(https://martinfowler.com/articles/microse ...
- java读取存在src目录下和存在同级目录下的配置文件
如果我有个文件存在src下一级的地方和存在src同级的目录应该怎么用相对路径去获取如图: 一.如果存在src同级的地方应该是InputStream in = new BufferedInputStre ...
- Github带来的不止是开源,还有折叠的认知
如果第二次看到我的文章,欢迎右侧扫码订阅我哟~
- 《利用Python进行数据分析·第2版》第四章 Numpy基础:数组和矢量计算
<利用Python进行数据分析·第2版>第四章 Numpy基础:数组和矢量计算 numpy高效处理大数组的数据原因: numpy是在一个连续的内存块中存储数据,独立于其他python内置对 ...
- 推荐一款优秀的WPF开源项目
项目介绍 此项目应用了Prism MVVM框架,项目展示数据来源于其他服务程序,使用的WebAPI通信,如果要正常运行此程序,需要您自己做一个WebAPI程序,由API接口提供数据驱动,其实直接查看代 ...