scrapy爬虫docker部署
spider_docker
接我上篇博客,为爬虫引用创建container,包括的模块:scrapy, mongo, celery, rabbitmq,连接https://github.com/LiuRoy/spider_docker
创建image
进入spider_docker目录,执行命令:
docker build --rm -t zhihu_spider src/
运行完成后,执行docker iamges就可以看到生成的image

生成container
在另一个项目zhihu_spider中有一个docker-compose.yml文件,可以参考配置:
dev:
image: zhihu_spider
volumes:
- ./:/zhihu_spider
- ../data:/data/db
ports:
- "20000:27017"
- "20001:15672"
privileged: true
tty: true
stdin_open: true
restart: always
以zhihu_spider为例,进入最上层目录后,执行docker-compose up命令。

zhihu_spider目录映射为docker中的/zhihu_spider,zhihu_spider统计目录data映射为/data/db用作mongo的数据存储。container中的mongo范文端口映射到本机的20000,rabbitmq映射为本地的20001端口。
执行爬虫
执行命令docker exec -it zhihuspider_dev_1 /bin/bash即可进入bash。
启动mongo
编辑/etc/mongod.conf文件,将绑定ip地址从127.0.0.0改为0.0.0.0,并重启mongod进程。k执行下面命令重启mongo服务
mongod --shutdown
mongod --config /etc/mongod.config
如果要在本机访问container中的数据,连接配置如下:
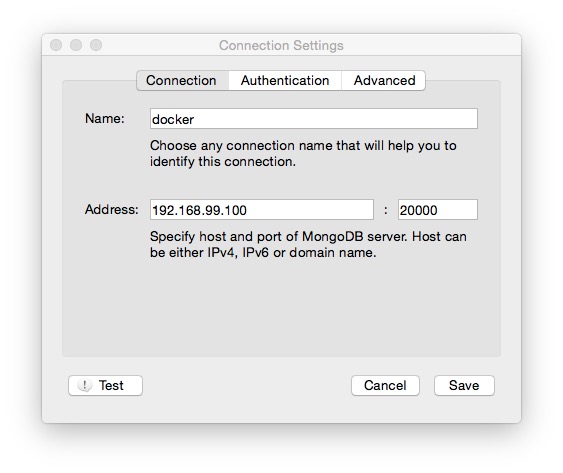
ip和port为映射后的ip和port。
启动rabbitmq
启动命令如下,访问方式同mongo
rabbitmq-plugins enable rabbitmq_management
rabbitmq-server &
启动爬虫
- 进入zhihu_spider/zhihu目录,启动异步任务
celery -A zhihu.tools.async worker --loglevel=info - 启动爬虫
python main.py
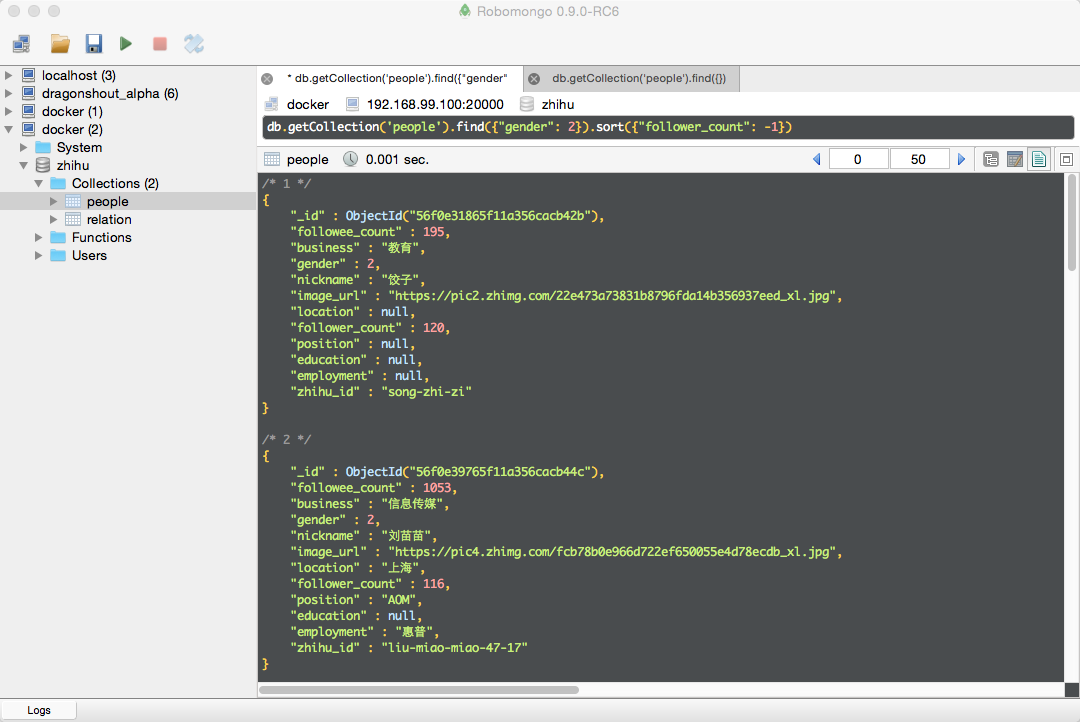
结果显示
筛选出女性,并按关注的人丝数降序排列
scrapy爬虫docker部署的更多相关文章
- scrapy爬虫学习系列三:scrapy部署到scrapyhub上
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- Scrapyd+Gerapy部署Scrapy爬虫进行可视化管理
Scrapy是一个流行的爬虫框架,利用Scrapyd,可以将其部署在远程服务端运行,并通过命令对爬虫进行管理,而Gerapy为我们提供了精美的UI,可以在web页面上直接点击操作,管理部署在scrap ...
- scrapy抓取拉勾网职位信息(八)——使用scrapyd对爬虫进行部署
上篇我们实现了分布式爬取,本篇来说下爬虫的部署. 分析:我们上节实现的分布式爬虫,需要把爬虫打包,上传到每个远程主机,然后解压后执行爬虫程序.这样做运行爬虫也可以,只不过如果以后爬虫有修改,需要重新修 ...
- Scrapy 爬虫
Scrapy 爬虫 使用指南 完全教程 scrapy note command 全局命令: startproject :在 project_name 文件夹下创建一个名为 project_name ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- scrapy爬虫学习系列五:图片的抓取和下载
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列四:portia的学习入门
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列一:scrapy爬虫环境的准备
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
随机推荐
- Python编码记录
字节流和字符串 当使用Python定义一个字符串时,实际会存储一个字节串: "abc"--[97][98][99] python2.x默认会把所有的字符串当做ASCII码来对待,但 ...
- Tcp/ip 报文解析
在编写网络程序时,常使用TCP协议.那么一个tcp包到底由哪些东西构成的呢?其实一个TCP包,首先需要通过IP协议承载,而IP报文,又需要通过以太网传送.下面我们来看看几种协议头的构成 一 .Ethe ...
- UITextView 输入字数限制
本文介绍了UITextView对中英文还有iOS自带表情输入的字数限制,由于中文输入会有联想导致字数限制不准确所以苦恼好久,所以参考一些大神的博客终于搞定,欢迎大家参考和指正. 对于限制UITextV ...
- 关于全局ID,雪花(snowflake)算法的说明
上次简单的说一下:http://www.cnblogs.com/dunitian/p/6041745.html#uid C#版本的国外朋友已经封装了,大家可以去看看:https://github.co ...
- Canvas坐标系转换
默认坐标系与当前坐标系 canvas中的坐标是从左上角开始的,x轴沿着水平方向(按像素)向右延伸,y轴沿垂直方向向下延伸.左上角坐标为x=0,y=0的点称作原点.在默认坐标系中,每一个点的坐标都是直接 ...
- 缓存工厂之Redis缓存
这几天没有按照计划分享技术博文,主要是去医院了,这里一想到在医院经历的种种,我真的有话要说:医院里的医务人员曾经被吹捧为美丽+和蔼+可亲的天使,在经受5天左右相互接触后不得不让感慨:遇见的有些人员在挂 ...
- ASP.NET Core project.json imports 是什么意思?
示例代码: "frameworks": { "netcoreapp1.0.0": { "imports" : "portable- ...
- C#创建dll类库
类库让我们的代码可复用,我们只需要在类库中声明变量一次,就能在接下来的过程中无数次地使用,而无需在每次使用前都要声明它.这样一来,就节省了我们的内存空间.而想要在类库添加什么类,还需取决于类库要实现哪 ...
- AI人工智能系列随笔
初探 AI人工智能系列随笔:syntaxnet 初探(1)
- JQuery的基础和应用
<参考文档> 1.什么是? DOM的作用:提供了一种动态的操作HTML元素的方法. jQuery是一个优秀的js库.用来操作HTML元素的工具. jQuery和DOM ...