scrapy 知乎用户信息爬虫
zhihu_spider
此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据存储使用mongo,下载这些数据感觉也没什么用,就当为大家学习scrapy提供一个例子吧。代码地址:https://github.com/LiuRoy/zhihu_spider,欢迎各位大神指出问题,另外知乎也欢迎大家关注哈 ^_^.
流程图
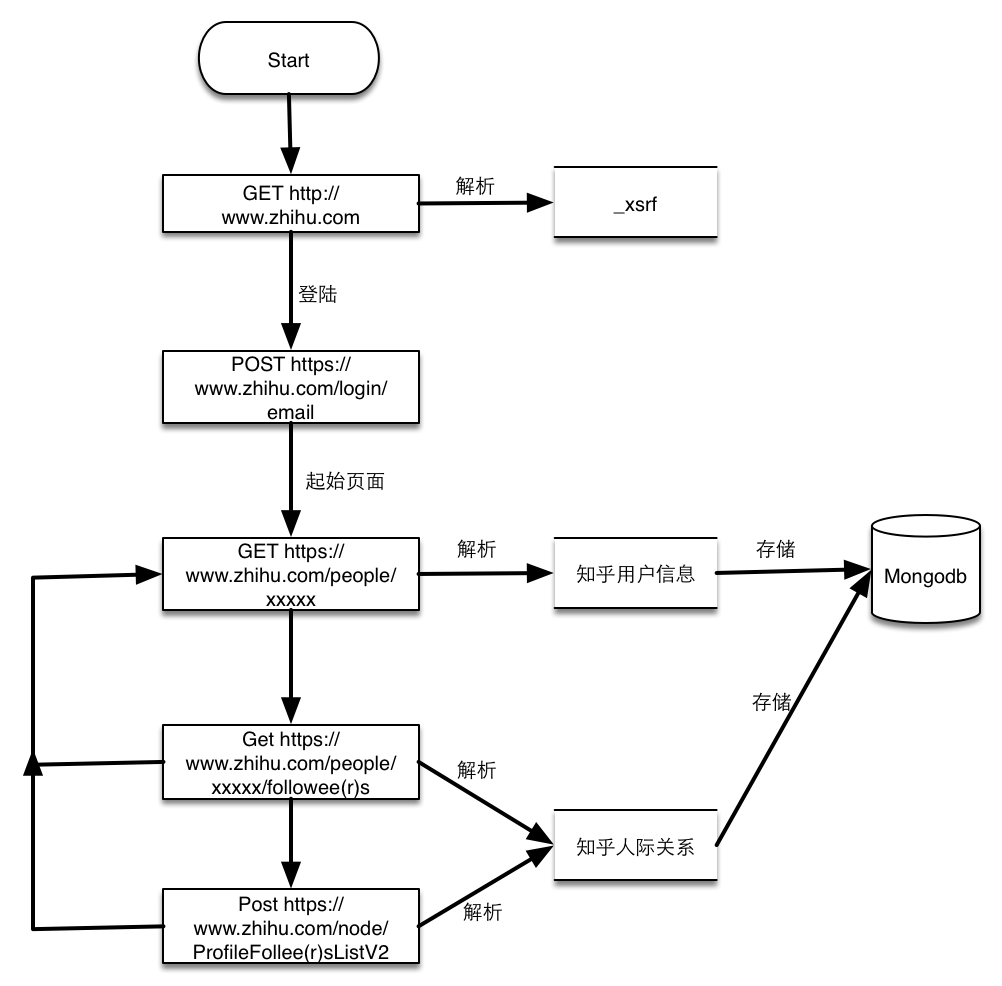
- 请求https://www.zhihu.com获取页面中的_xsrf数据,知乎开启了跨站请求伪造功能,所有的POST请求都必须带上此参数。
- 提交用户名,密码已经第一步解析的_xsrf参数到https://www.zhihu.com/login/email,登陆获取cookies
- 访问用户主页,以我的主页为例https://www.zhihu.com/people/weizhi-xiazhi, 如下图:
- 解析的用户信息包括昵称,头像链接,个人基本信息还有关注人的数量和粉丝的数量。这个页面还能获取关注人页面和粉丝页面。
- 由上一步获取的分页列表页面和关注人页面获取用户人际关系,这两个页面类似,唯一麻烦的是得到的静态页面最多只有二十个,获取全部的人员必须通过POST请求,解析到的个人主页再由上一步来解析。
代码解释
scrapy文档非常详细,在此我就不详细讲解,你所能碰到的任何疑问都可以在文档中找到解答。
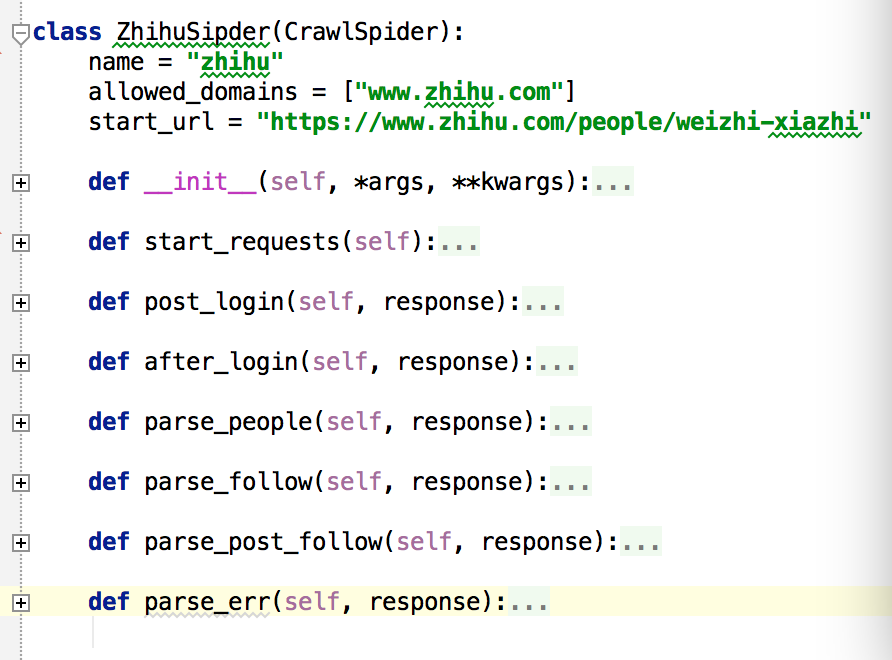
- 爬虫框架从start_requests开始执行,此部分会提交知乎主页的访问请求给引擎,并设置回调函数为post_login.
- post_login解析主页获取_xsrf保存为成员变量中,并提交登陆的POST请求,设置回调函数为after_login.
- after_login拿到登陆后的cookie,提交一个start_url的GET请求给爬虫引擎,设置回调函数parse_people.
- parse_people解析个人主页,一次提交关注人和粉丝列表页面到爬虫引擎,回调函数是parse_follow, 并把解析好的个人数据提交爬虫引擎写入mongo。
- parse_follow会解析用户列表,同时把动态的人员列表POST请求发送只引擎,回调函数是parse_post_follow,把解析好的用户主页链接请求也发送到引擎,人员关系写入mongo。
- parse_post_follow单纯解析用户列表,提交用户主页请求至引擎。
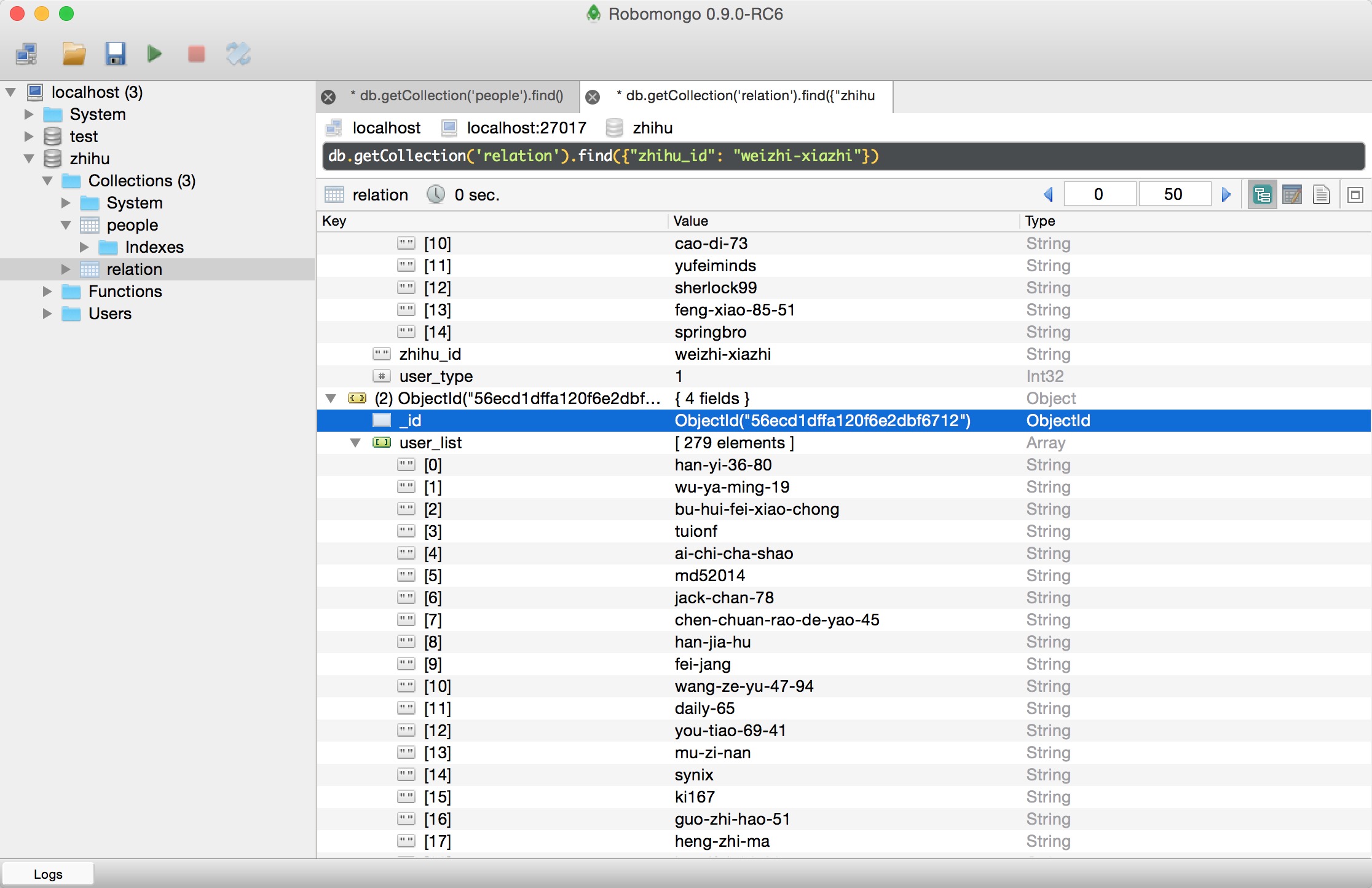
效果图
scrapy 知乎用户信息爬虫的更多相关文章
- 基于webmagic的爬虫小应用--爬取知乎用户信息
听到“爬虫”,是不是第一时间想到Python/php ? 多少想玩爬虫的Java学习者就因为语言不通而止步.Java是真的不能做爬虫吗? 当然不是. 只不过python的3行代码能解决的问题,而Jav ...
- scrapy爬取全部知乎用户信息
# -*- coding: utf-8 -*- # scrapy爬取全部知乎用户信息 # 1:是否遵守robbots_txt协议改为False # 2: 加入爬取所需的headers: user-ag ...
- python3编写网络爬虫22-爬取知乎用户信息
思路 选定起始人 选一个关注数或者粉丝数多的大V作为爬虫起始点 获取粉丝和关注列表 通过知乎接口获得该大V的粉丝列表和关注列表 获取列表用户信息 获取列表每个用户的详细信息 获取每个用户的粉丝和关注 ...
- Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- Scrapy爬虫框架第八讲【项目实战篇:知乎用户信息抓取】--本文参考静觅博主所写
思路分析: (1)选定起始人(即选择关注数和粉丝数较多的人--大V) (2)获取该大V的个人信息 (3)获取关注列表用户信息 (4)获取粉丝列表用户信息 (5)重复(2)(3)(4)步实现全知乎用户爬 ...
- 爬虫(十六):scrapy爬取知乎用户信息
一:爬取思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账 ...
- Python之爬虫(二十) Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- Python之爬虫(二十一) Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
随机推荐
- word-wrap ,word-break 和white-space 的联系
在工作中我遇到一个问题,其实功能也不复杂,就是上面有个textarea标签 ,里面输入内容,下面有个显示效果 ,有个条件就是 上面输入的什么格式(比如换行等等),下面显示的也是 什么格式.如下图: 这 ...
- javascript中的this与函数讲解
前言 javascript中没有块级作用域(es6以前),javascript中作用域分为函数作用域和全局作用域.并且,大家可以认为全局作用域其实就是Window函数的函数作用域,我们编写的js代码, ...
- iOS开发系列--打造自己的“美图秀秀”
--绘图与滤镜全面解析 概述 在iOS中可以很容易的开发出绚丽的界面效果,一方面得益于成功系统的设计,另一方面得益于它强大的开发框架.今天我们将围绕iOS中两大图形.图像绘图框架进行介绍:Quartz ...
- Electron使用与学习--(页面间的通信)
目录结构: index.js是主进程js. const electron = require('electron') const app = electron.app const BrowserWin ...
- 【开源】.net 分布式架构之监控平台
开源地址:http://git.oschina.net/chejiangyi/Dyd.BaseService.Monitor .net 简单监控平台,用于集群的性能监控,应用耗时监控管理,统一日志管理 ...
- 用scikit-learn学习谱聚类
在谱聚类(spectral clustering)原理总结中,我们对谱聚类的原理做了总结.这里我们就对scikit-learn中谱聚类的使用做一个总结. 1. scikit-learn谱聚类概述 在s ...
- [.NET] 利用 async & await 的异步编程
利用 async & await 的异步编程 [博主]反骨仔 [出处]http://www.cnblogs.com/liqingwen/p/5922573.html 目录 异步编程的简介 异 ...
- AFNetworking 3.0 源码解读(六)之 AFHTTPSessionManager
AFHTTPSessionManager相对来说比较好理解,代码也比较短.但却是我们平时可能使用最多的类. AFNetworking 3.0 源码解读(一)之 AFNetworkReachabilit ...
- C++ 11 多线程--线程管理
说到多线程编程,那么就不得不提并行和并发,多线程是实现并发(并行)的一种手段.并行是指两个或多个独立的操作同时进行.注意这里是同时进行,区别于并发,在一个时间段内执行多个操作.在单核时代,多个线程是并 ...
- CSS知识总结(九)
CSS常用样式 10.自定义动画 1)关键帧(keyframes) 被称为关键帧,其类似于Flash中的关键帧. 在CSS3中其主要以“@keyframes”开头,后面紧跟着是动画名称加上一对花括号“ ...