Python之爬虫(二十) Scrapy爬取所有知乎用户信息(上)
爬取的思路
首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号信息和被关注信息的关注列表,爬取这些用户的信息,通过这种递归的方式从而爬取整个知乎的所有的账户信息。整个过程通过下面两个图表示:

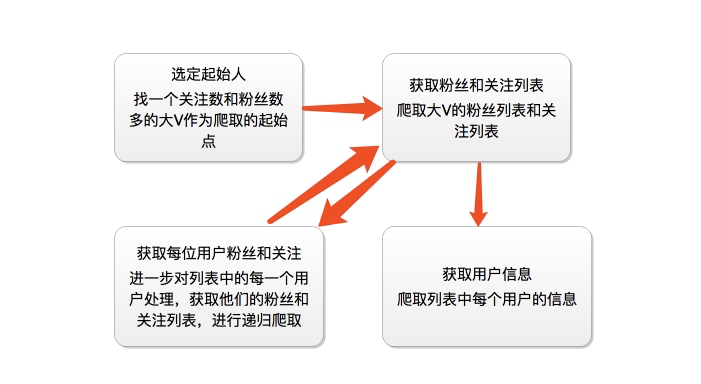
爬虫分析过程
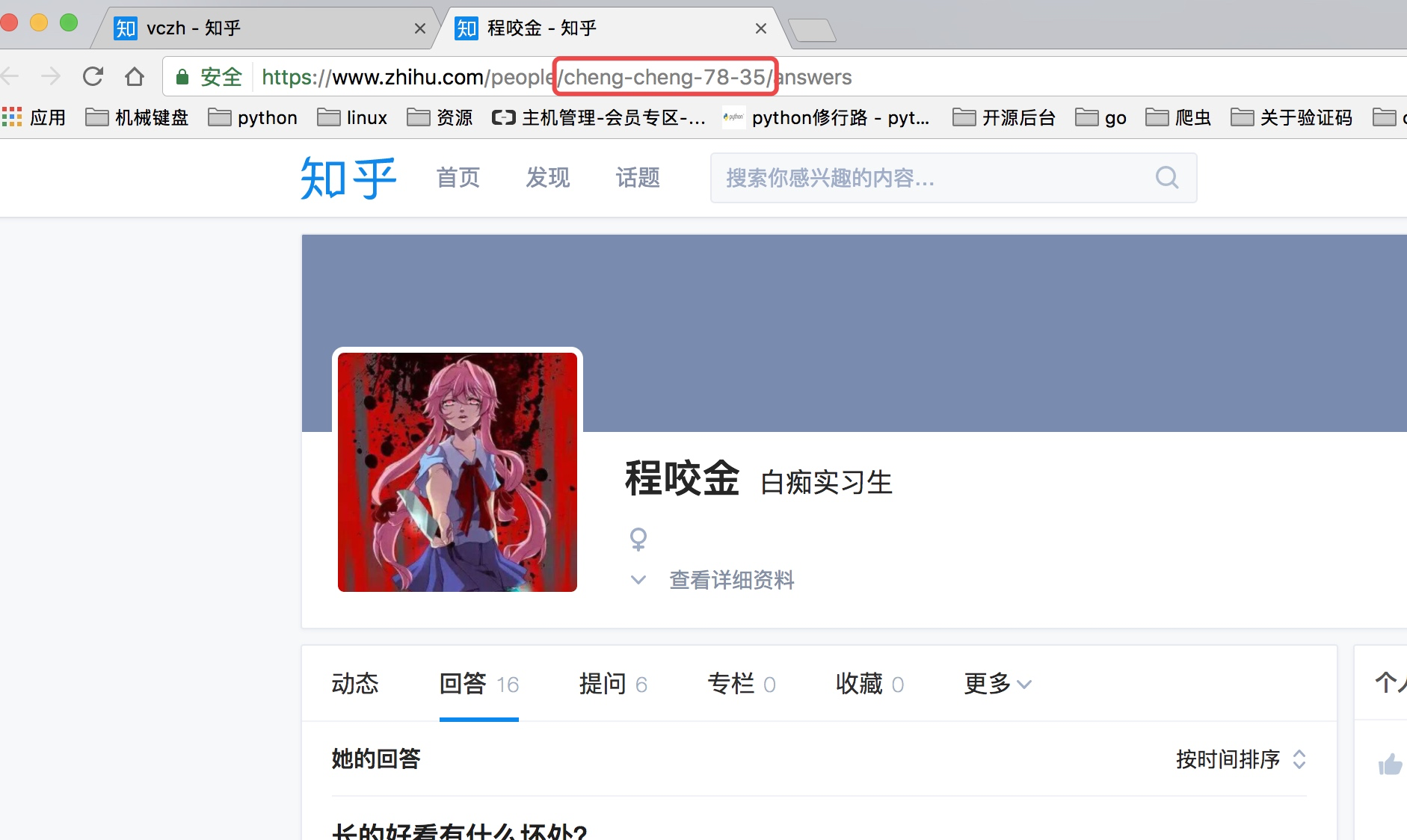
这里我们找的账号地址是:https://www.zhihu.com/people/excited-vczh/answers
我们抓取的大V账号的主要信息是:

其次我们要获取这个账号的关注列表和被关注列表
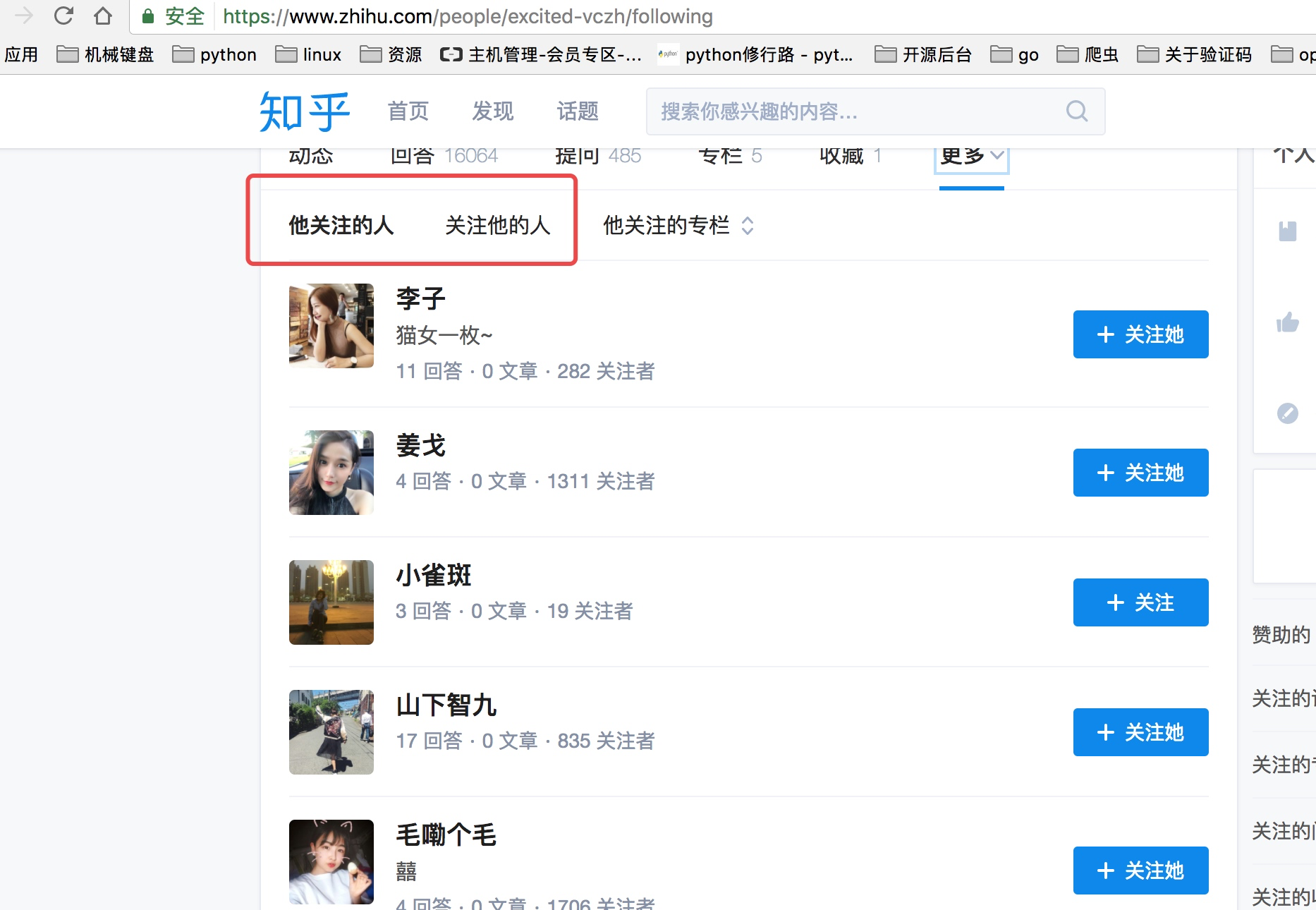
这里我们需要通过抓包分析如果获取这些列表的信息以及用户的个人信息内容
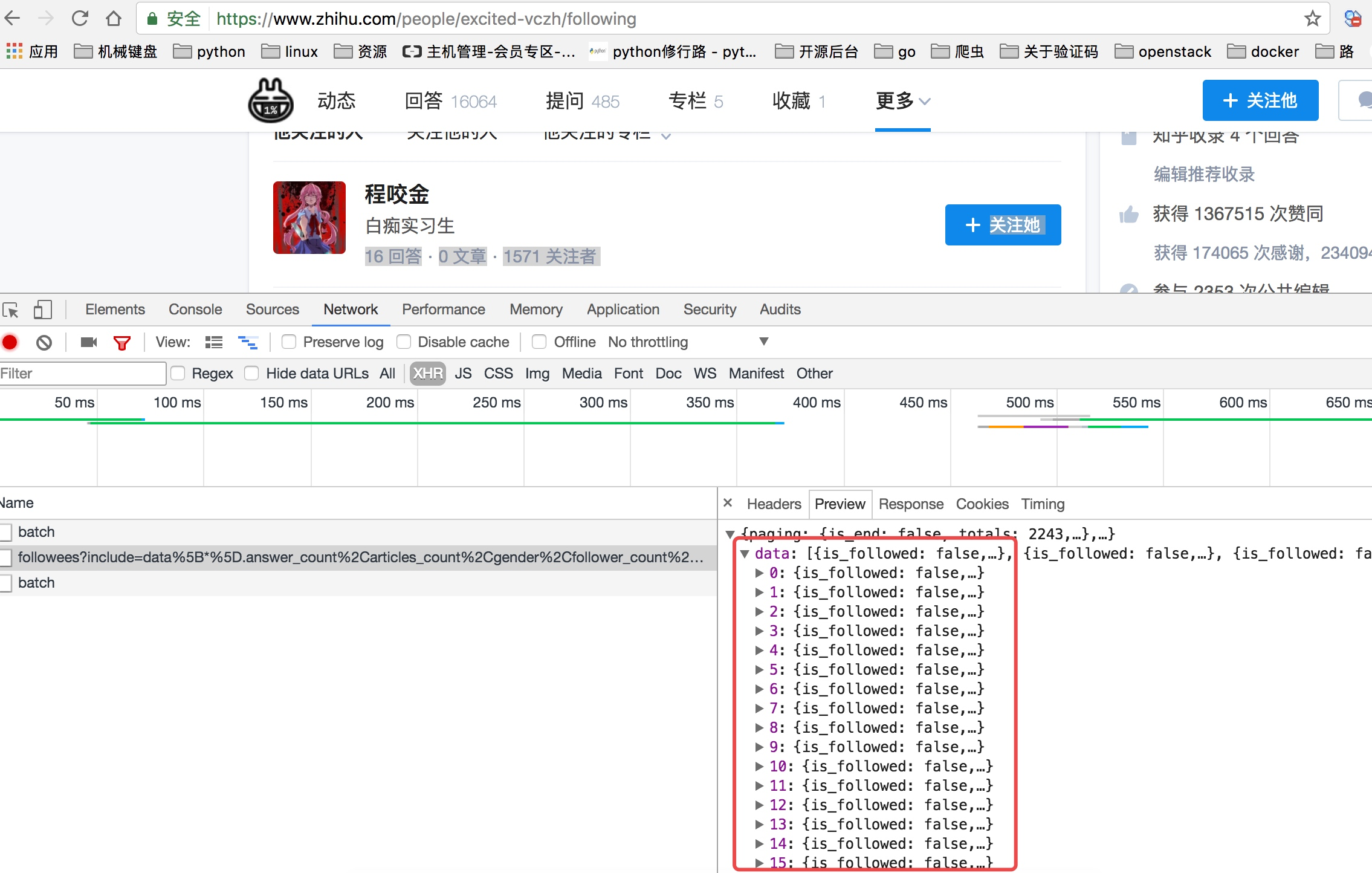
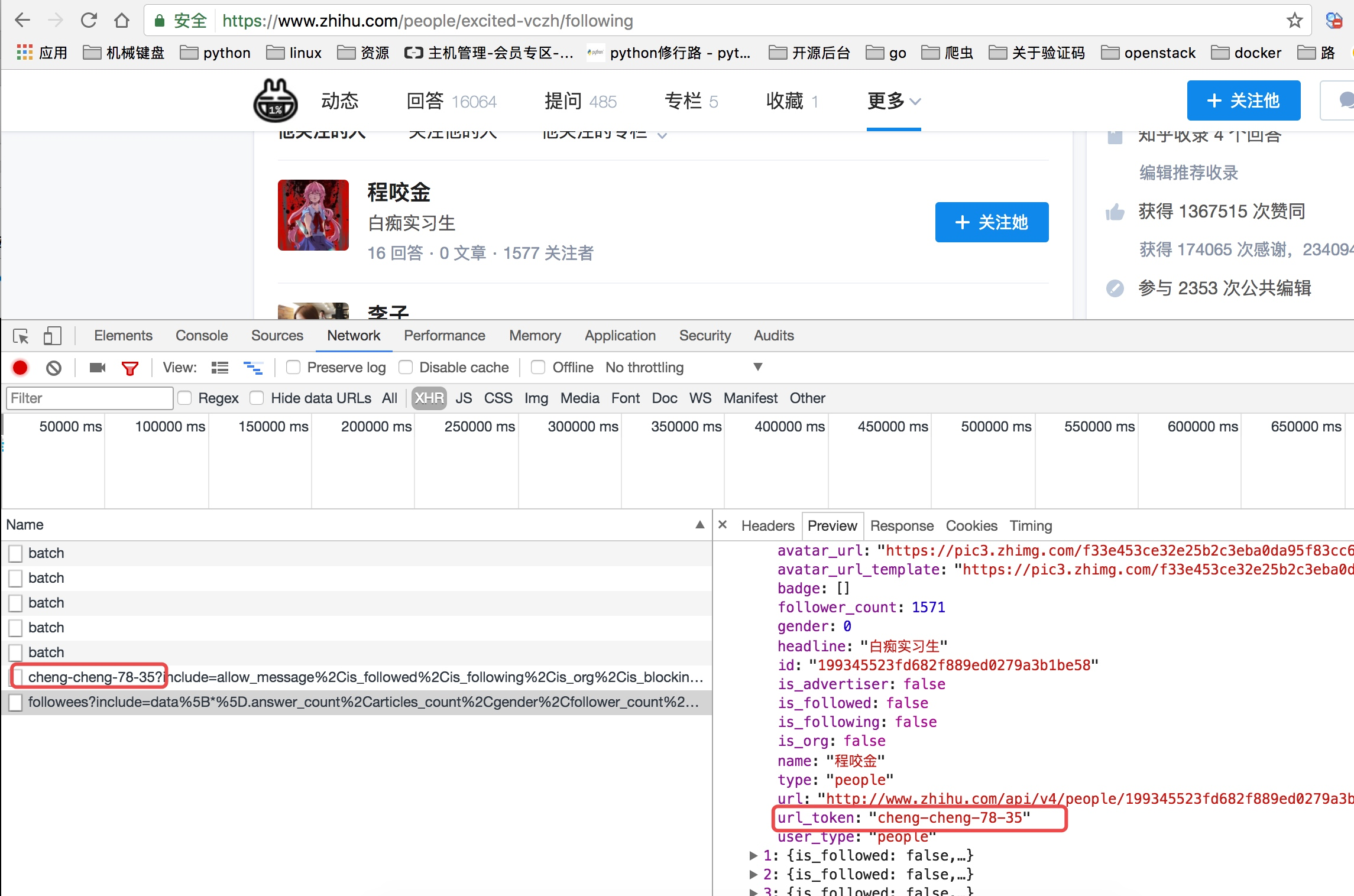
当我们查看他关注人的列表的时候我们可以看到他请求了如下图中的地址,并且我们可以看到返回去的结果是一个json数据,而这里就存着一页关乎的用户信息。


上面虽然可以获取单个用户的个人信息,但是不是特别完整,这个时候我们获取一个人的完整信息地址是当我们将鼠标放到用户名字上面的时候,可以看到发送了一个请求:
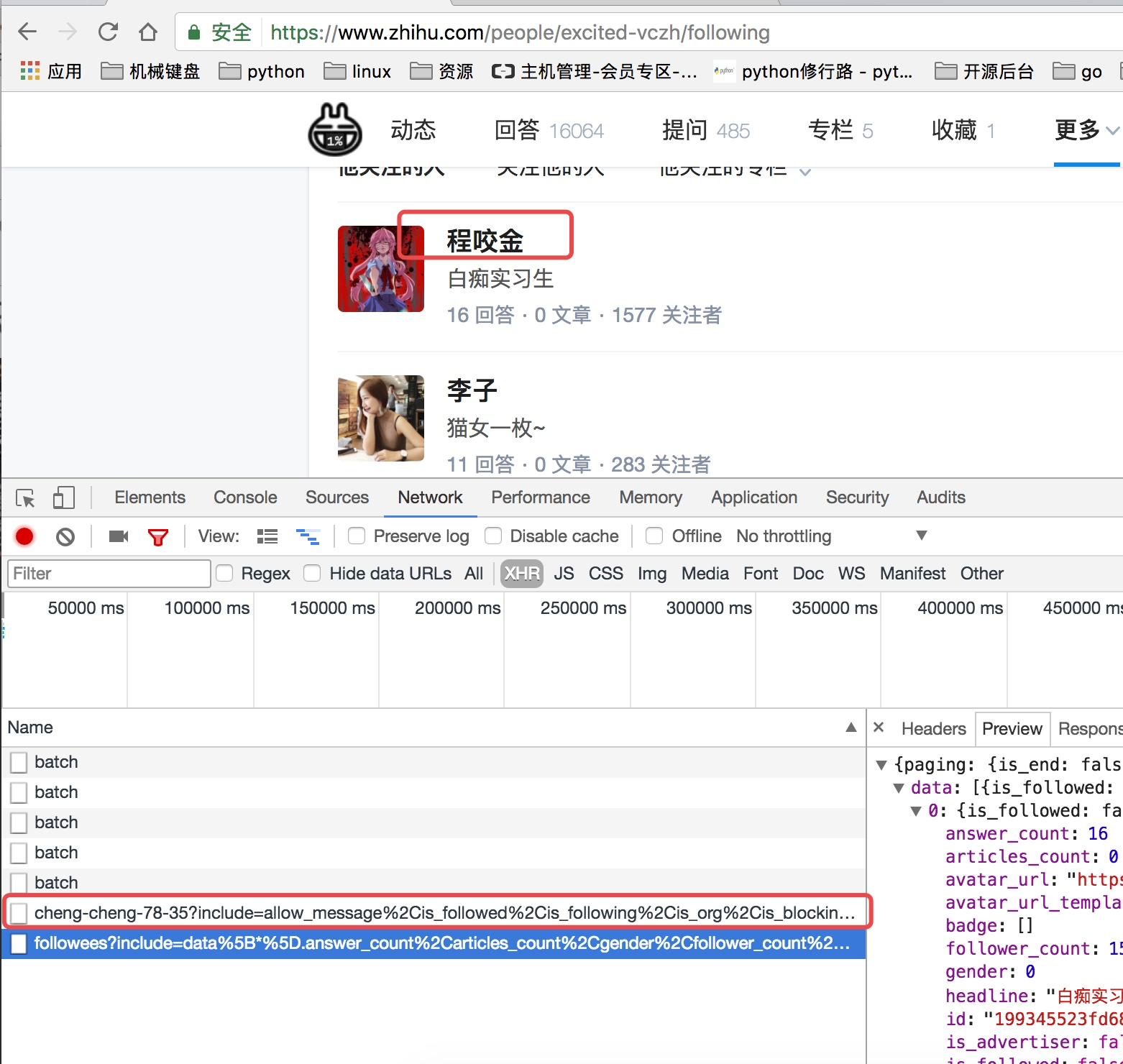
我们可以看这个地址的返回结果可以知道,这个地址请求获取的是用户的详细信息:

通过上面的分析我们知道了以下两个地址:
获取用户关注列表的地址:https://www.zhihu.com/api/v4/members/excited-vczh/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=0&limit=20
获取单个用户详细信息的地址:https://www.zhihu.com/api/v4/members/excited-vczh?include=locations%2Cemployments%2Cgender%2Ceducations%2Cbusiness%2Cvoteup_count%2Cthanked_Count%2Cfollower_count%2Cfollowing_count%2Ccover_url%2Cfollowing_topic_count%2Cfollowing_question_count%2Cfollowing_favlists_count%2Cfollowing_columns_count%2Cavatar_hue%2Canswer_count%2Carticles_count%2Cpins_count%2Cquestion_count%2Ccolumns_count%2Ccommercial_question_count%2Cfavorite_count%2Cfavorited_count%2Clogs_count%2Cmarked_answers_count%2Cmarked_answers_text%2Cmessage_thread_token%2Caccount_status%2Cis_active%2Cis_bind_phone%2Cis_force_renamed%2Cis_bind_sina%2Cis_privacy_protected%2Csina_weibo_url%2Csina_weibo_name%2Cshow_sina_weibo%2Cis_blocking%2Cis_blocked%2Cis_following%2Cis_followed%2Cmutual_followees_count%2Cvote_to_count%2Cvote_from_count%2Cthank_to_count%2Cthank_from_count%2Cthanked_count%2Cdescription%2Chosted_live_count%2Cparticipated_live_count%2Callow_message%2Cindustry_category%2Corg_name%2Corg_homepage%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics
这里我们可以从请求的这两个地址里发现一个问题,关于用户信息里的url_token其实就是获取单个用户详细信息的一个凭证也是请求的一个重要参数,并且当我们点开关注人的的链接时发现请求的地址的唯一标识也是这个url_token
创建项目进行再次分析
通过命令创建项目
scrapy startproject zhihu_user
cd zhihu_user
scrapy genspider zhihu www.zhihu.com
直接通过scrapy crawl zhihu启动爬虫会看到如下错误:

这个问题其实是爬取网站的时候经常碰到的问题,大家以后见多了就知道是怎么回事了,是请求头的问题,应该在请求头中加User-Agent,在settings配置文件中有关于请求头的配置默认是被注释的,我们可以打开,并且加上User-Agent,如下:
关于如何获取User-Agent,可以在抓包的请求头中看到也可以在谷歌浏览里输入:chrome://version/ 查看
这样我们就可以正常通过代码访问到知乎了
然后我们可以改写第一次的请求,这个我们前面的scrapy文章关于spiders的时候已经说过如何改写start_request,我们让第一次请求分别请求获取用户列表以及获取用户信息

这个时候我们再次启动爬虫

我们会看到是一个401错误,而解决的方法其实还是请求头的问题,从这里我们也可以看出请求头中包含的很多信息都会影响我们爬取这个网站的信息,所以当我们很多时候直接请求网站都无法访问的时候就可以去看看请求头,看看是不是请求头的哪些信息导致了请求的结果,而这里则是因为如下图所示的参数:
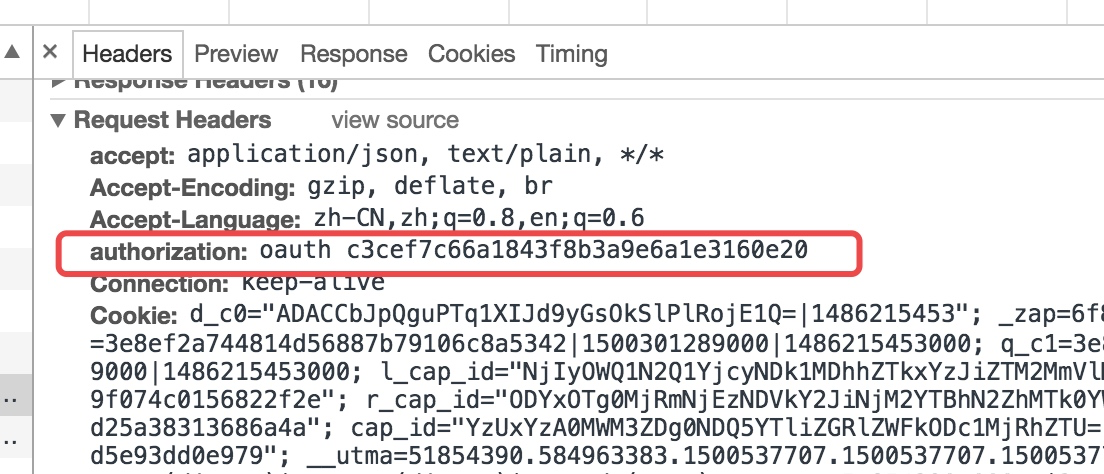
所以我们需要把这个参数同样添加到请求头中:

然后重新启动爬虫,这个时候我们已经可以获取到正常的内容
到此基本的分析可以说是都分析好了,剩下的就是具体代码的实现,在下一篇文张中写具体的实现代码内容!
Python之爬虫(二十) Scrapy爬取所有知乎用户信息(上)的更多相关文章
- Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- scrapy爬取全部知乎用户信息
# -*- coding: utf-8 -*- # scrapy爬取全部知乎用户信息 # 1:是否遵守robbots_txt协议改为False # 2: 加入爬取所需的headers: user-ag ...
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- Python之爬虫(二十一) Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- 利用Scrapy爬取所有知乎用户详细信息并存至MongoDB
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~ 作者 :崔庆才 本节分享一下爬取知乎用户所有用户信息的 Scrapy 爬虫实战. 本节目标 本节要实现的内容有 ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- Python网络爬虫——Appuim+夜神模拟器爬取得到APP课程数据
一.背景介绍 随着生产力和经济社会的发展,温饱问题基本解决,人们开始追求更高层次的精神文明,开始愿意为知识和内容付费.从2016年开始,内容付费渐渐成为时尚. 罗辑思维创始人罗振宇全力打造" ...
- python爬虫29 | 使用scrapy爬取糗事百科的例子,告诉你它有多厉害!
是时候给你说说 爬虫框架了 使用框架来爬取数据 会节省我们更多时间 很快就能抓取到我们想要抓取的内容 框架集合了许多操作 比如请求,数据解析,存储等等 都可以由框架完成 有些小伙伴就要问了 你他妈的 ...
- python网络爬虫第三弹(<爬取get请求的页面数据>)
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是通过代码模拟浏览器发送请求,其常被用到的子模块在 python3中的为urllib.request 和 urllib ...
随机推荐
- pyqt5 主界面打开新主界面的实现
import sys from PyQt5.QtWidgets import * from PyQt5.QtCore import * from PyQt5.QtGui import * ###### ...
- acm对拍程序 以及sublime text3的文件自动更新插件auto refresh
acm等算法比赛常用---对拍 以及sublime text3的文件自动更新插件auto refresh 对拍 对拍即程序自动对比正确程序的运行结果和错误程序的运行结果之间的差异 废话少说, 直接上操 ...
- 03 . Jenkins构建之代码扫描
Sonar简介 Sonar 是一个用于代码质量管理的开放平台.通过插件机制,Sonar可以集成不同的测试工具,代码分析工具,以及持续集成工具.与持续集成工具(例如 Hudson/Jenkins 等)不 ...
- 代码规范与计划(Beta阶段)
这个作业属于哪个课程 软件工程 (福州大学至诚学院 - 计算机工程系) 团队名称 WeChair 这个作业要求在哪里 Beta冲刺 这个作业的目标 代码规范与计划 作业正文 如下 其他参考文献 代码规 ...
- koa2 的使用方法:(一)
1. koa2 使用方法: 安装指令是: npm install koa2 使用koa2 创建项目工程: 1. koa2 (项目工程) 2. 进入项目工程: cd 进入您所创建的项目工程 3. npm ...
- 微信小程序for循环遍历
wxml: <block wx:for="{{data}}" wx:for-item="data"> & ...
- InnoDB 中 B+ 树索引的分裂
数据库中B+树索引的分裂并不总是从页的中间记录开始,这样可能会导致空间的浪费,例如下面的记录: 1, 2, 3, 4, 5, 6, 7, 8, 9 插入式根据自增顺序进行的,若这时插入10这条记录后需 ...
- MQ消息队列(2)—— Java消息服务接口(JMS)
一.理解JMS 1.什么是JMS? JMS即Java消息服务(Java Message Service)应用程序接口,API是一个消息服务的标准或者说是规范,允许应用程序组件基于J ...
- java关于传值与传引用
关于java传值还是传引用的问题经常出现在一些烦人的面试题中,主要考察个人对java基础的掌握情况. 首先明确一下:本地方法中,java的参数传递都是传值.但是如果是远程调用方法时,会将对象本身传递过 ...
- 暑假集训Day1 整数划分
题目大意: 如何把一个正整数N(N长度<20)划分为M(M>=1)个部分,使这M个部分的乘积最大.N.M从键盘输入,输出最大值及一种划分方式. 输入格式: 第一行一个正整数T(T<= ...