HUE配置文件hue.ini 的zookeeper模块详解(图文详解)(分HA集群)
不多说,直接上干货!
我的集群机器情况是 bigdatamaster(192.168.80.10)、bigdataslave1(192.168.80.11)和bigdataslave2(192.168.80.12)
然后,安装目录是在/home/hadoop/app下。
官方建议在master机器上安装Hue,我这里也不例外。安装在bigdatamaster机器上。
Hue版本:hue-3.9.0-cdh5.5.4
需要编译才能使用(联网) 说给大家的话:大家电脑的配置好的话,一定要安装cloudera manager。毕竟是一家人的。
同时,我也亲身经历过,会有部分组件版本出现问题安装起来要个大半天时间去排除,做好心里准备。废话不多说,因为我目前读研,自己笔记本电脑最大8G,只能玩手动来练手。
纯粹是为了给身边没高配且条件有限的学生党看的! 但我已经在实验室机器群里搭建好cloudera manager 以及 ambari都有。
大数据领域两大最主流集群管理工具Ambari和Cloudera Manger
Cloudera安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
Ambari安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
https://www.cloudera.com/documentation/enterprise/latest/topics/cdh_ig_hue_config.html#concept_ezg_b2s_hl
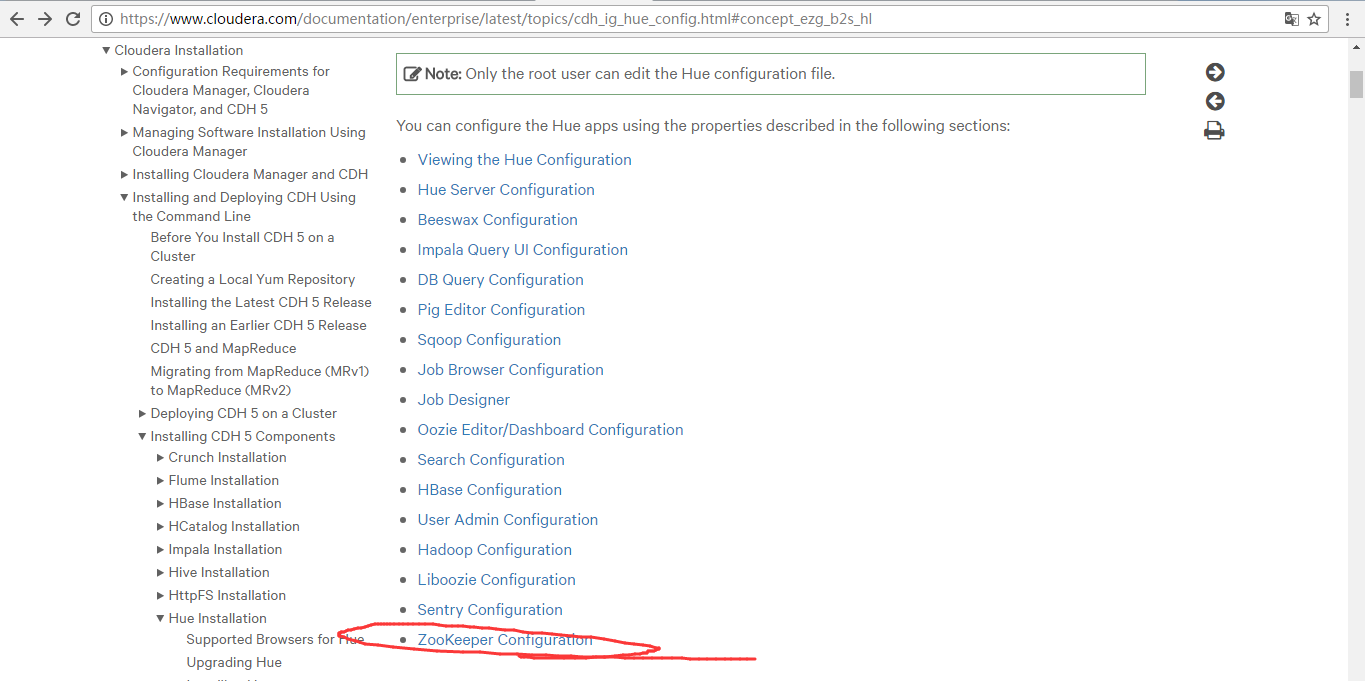
一、以下是默认的配置文件
这里,暂时不说
二、以下是跟我机器集群匹配的配置文件(非HA集群下怎么配置Hue的zookeeper模块)
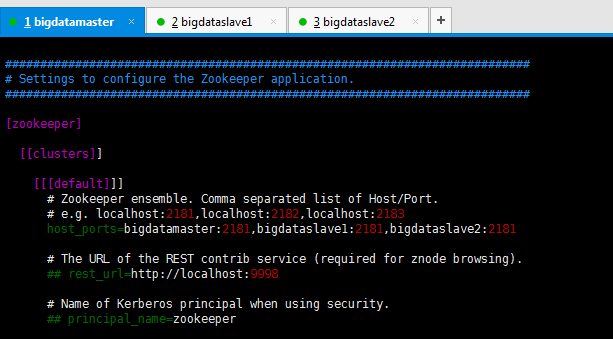

###########################################################################
# Settings to configure the Zookeeper application.
########################################################################### [zookeeper] [[clusters]] [[[default]]]
# Zookeeper ensemble. Comma separated list of Host/Port.
# e.g. localhost:,localhost:,localhost:
host_ports=bigdatamaster:,bigdataslave1:,bigdataslave2: # The URL of the REST contrib service (required for znode browsing).
## rest_url=http://localhost:9998 # Name of Kerberos principal when using security.
## principal_name=zookeeper
三、以下是跟我机器集群匹配的配置文件(非HA集群下怎么配置Hue的zookeeper模块)
hadoop-2.6.0.tar.gz的集群搭建(5节点)
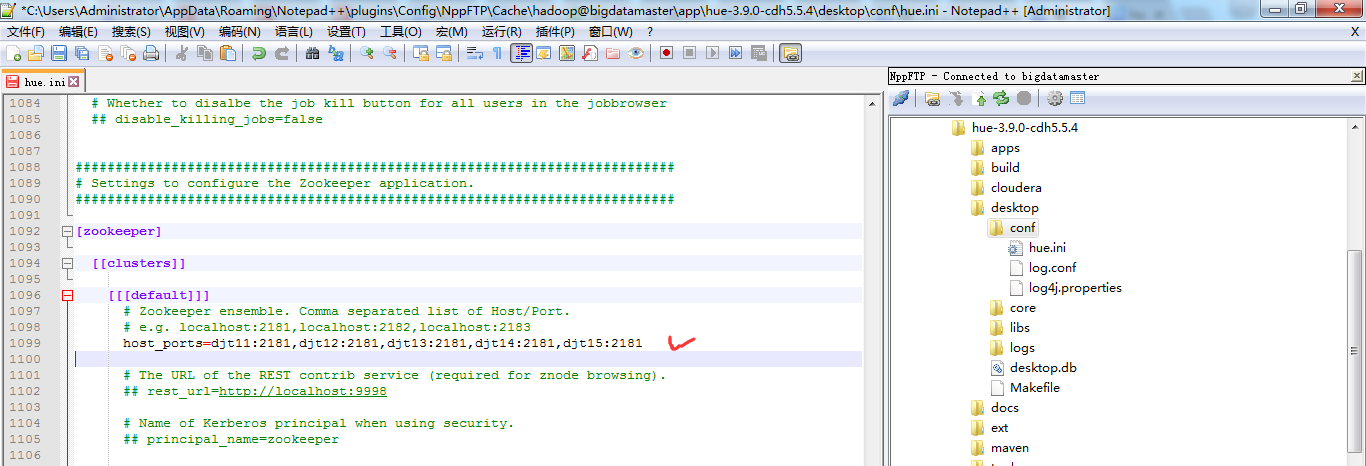
###########################################################################
# Settings to configure the Zookeeper application.
########################################################################### [zookeeper] [[clusters]] [[[default]]]
# Zookeeper ensemble. Comma separated list of Host/Port.
# e.g. localhost:,localhost:,localhost:
host_ports=djt11:,djt12:,djt13:,djt14:,djt15: # The URL of the REST contrib service (required for znode browsing).
## rest_url=http://localhost:9998 # Name of Kerberos principal when using security.
## principal_name=zookeeper
如果,单独只配置上述的话,就算我们的zookeeper集群进程全都正常启动,但是,还是会无法连接,出现错误 无法正确连接到 Zookeeper!!!!timed out (这里,适用非HA和HA集群)
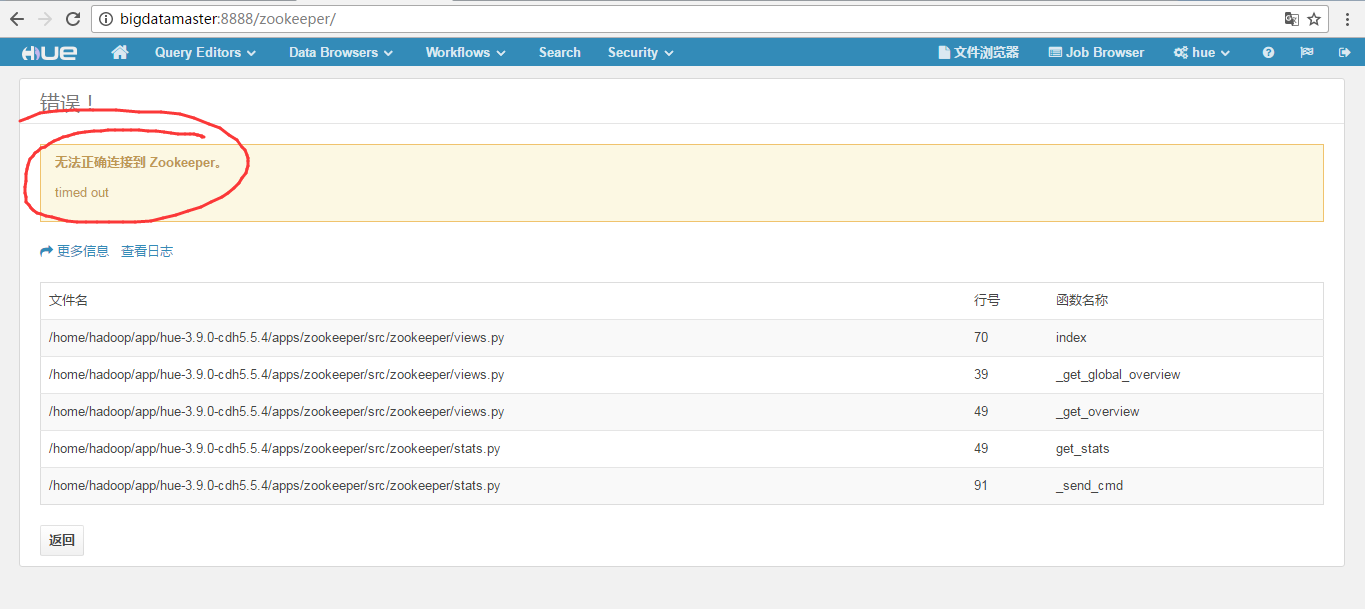
因为,官网给的步骤,很详细(记住,只要三步就好,一切都要看官网,别跟着别人的博客走)
https://www.cloudera.com/documentation/enterprise/latest/topics/cdh_ig_hue_config.html#concept_hhc_hwn_rl
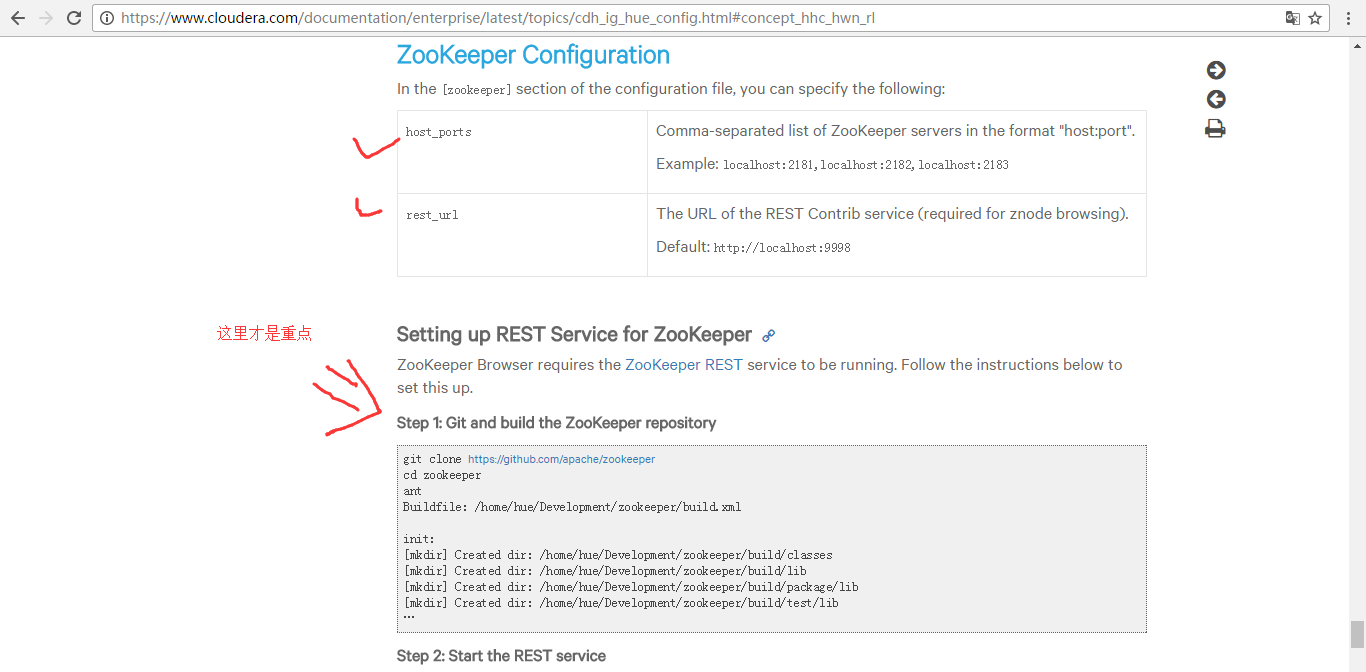
第一步:首先,进入【ZOOKEEPER_HOME】目录下执行编译
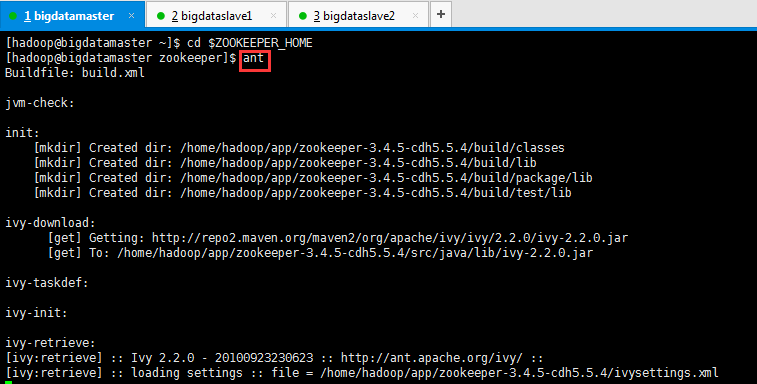
[hadoop@bigdatamaster ~]$ cd $ZOOKEEPER_HOME
[hadoop@bigdatamaster zookeeper]$ ant

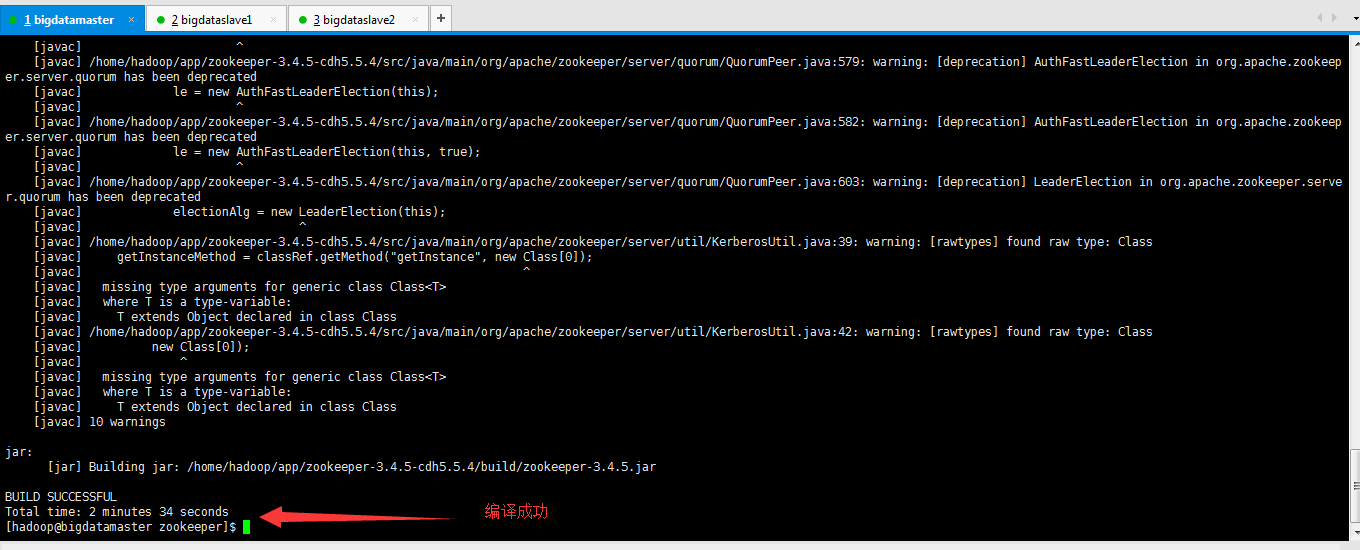
看大家的网速吧。我这里是,需将bigdatamaster、bigdataslave1和bigdataslave2里都安装了zookeeper,所以都要进行ant编译。
然后,如下的目录,都会自动建立好
[mkdir] Created dir: /home/hue/Development/zookeeper/build/classes
[mkdir] Created dir: /home/hue/Development/zookeeper/build/lib
[mkdir] Created dir: /home/hue/Development/zookeeper/build/package/lib
[mkdir] Created dir: /home/hue/Development/zookeeper/build/test/lib
第二步:开启REST服务

cd src/contrib/rest
nohup ant run&
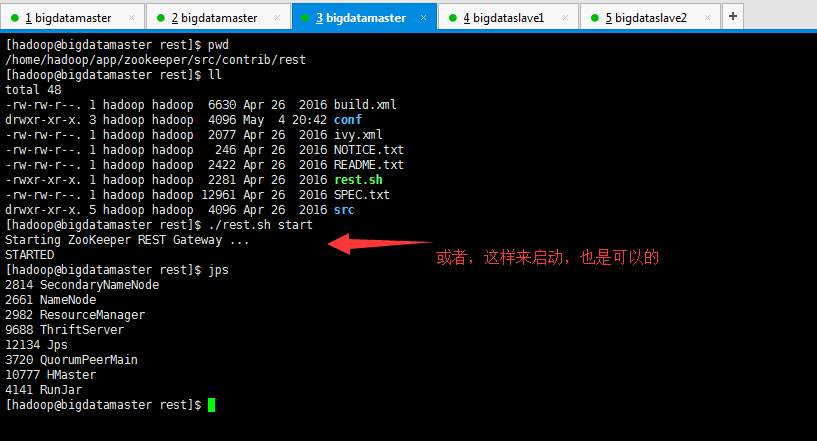
[hadoop@bigdatamaster rest]$ pwd
/home/hadoop/app/zookeeper/src/contrib/rest
[hadoop@bigdatamaster rest]$ ll
total
-rw-rw-r--. hadoop hadoop Apr build.xml
drwxr-xr-x. hadoop hadoop May : conf
-rw-rw-r--. hadoop hadoop Apr ivy.xml
-rw-rw-r--. hadoop hadoop Apr NOTICE.txt
-rw-rw-r--. hadoop hadoop Apr README.txt
-rwxr-xr-x. hadoop hadoop Apr rest.sh
-rw-rw-r--. hadoop hadoop Apr SPEC.txt
drwxr-xr-x. hadoop hadoop Apr src
[hadoop@bigdatamaster rest]$ ./rest.sh start
Starting ZooKeeper REST Gateway ...
STARTED
[hadoop@bigdatamaster rest]$ jps
SecondaryNameNode
NameNode
ResourceManager
ThriftServer
Jps
QuorumPeerMain
HMaster
RunJar
[hadoop@bigdatamaster rest]$
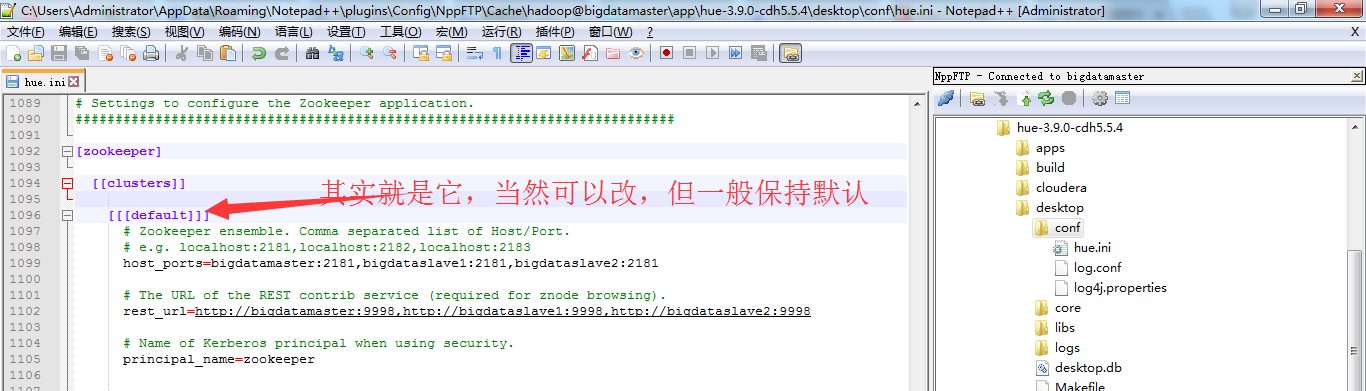
第三步:去Hue配置文件,对应去修改zookeeper模块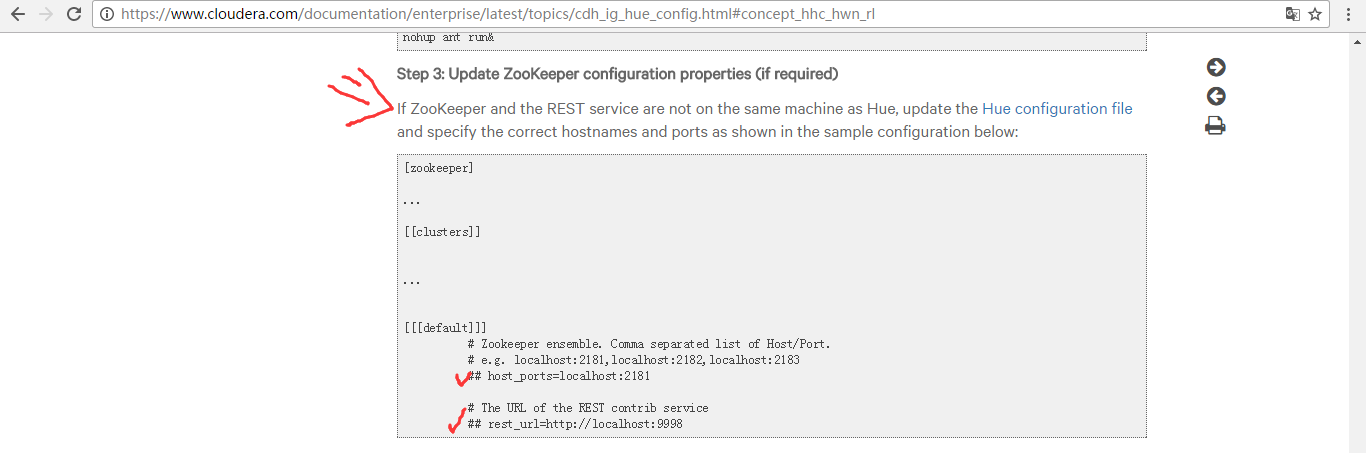
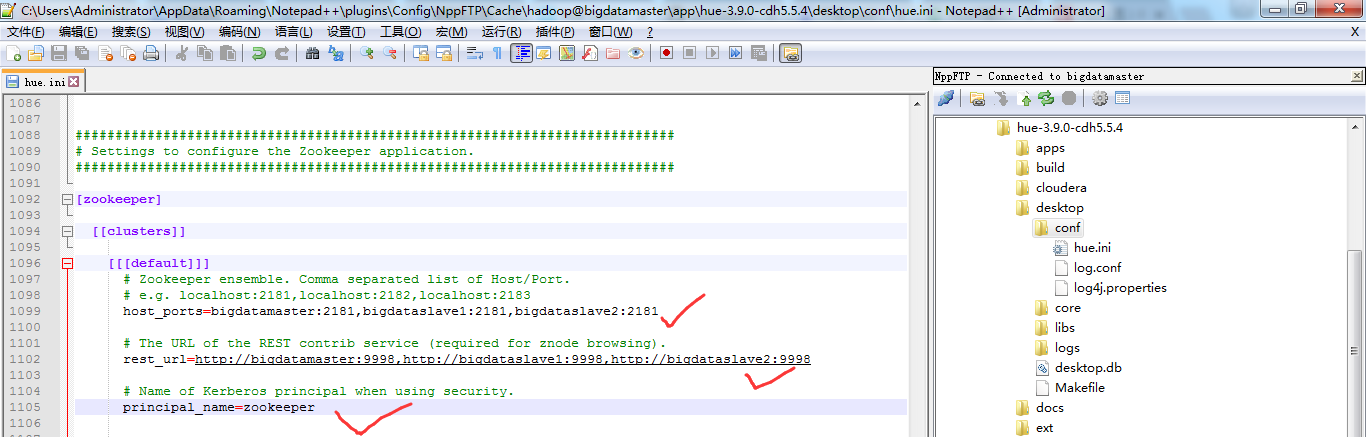
###########################################################################
# Settings to configure the Zookeeper application.
########################################################################### [zookeeper] [[clusters]] [[[default]]]
# Zookeeper ensemble. Comma separated list of Host/Port.
# e.g. localhost:,localhost:,localhost:
host_ports=bigdatamaster:,bigdataslave1:,bigdataslave2: # The URL of the REST contrib service (required for znode browsing).
rest_url=http://bigdatamaster:9998,http://bigdataslave1:9998,http://bigdataslave2:9998 # Name of Kerberos principal when using security.
principal_name=zookeeper
然后,可以看到
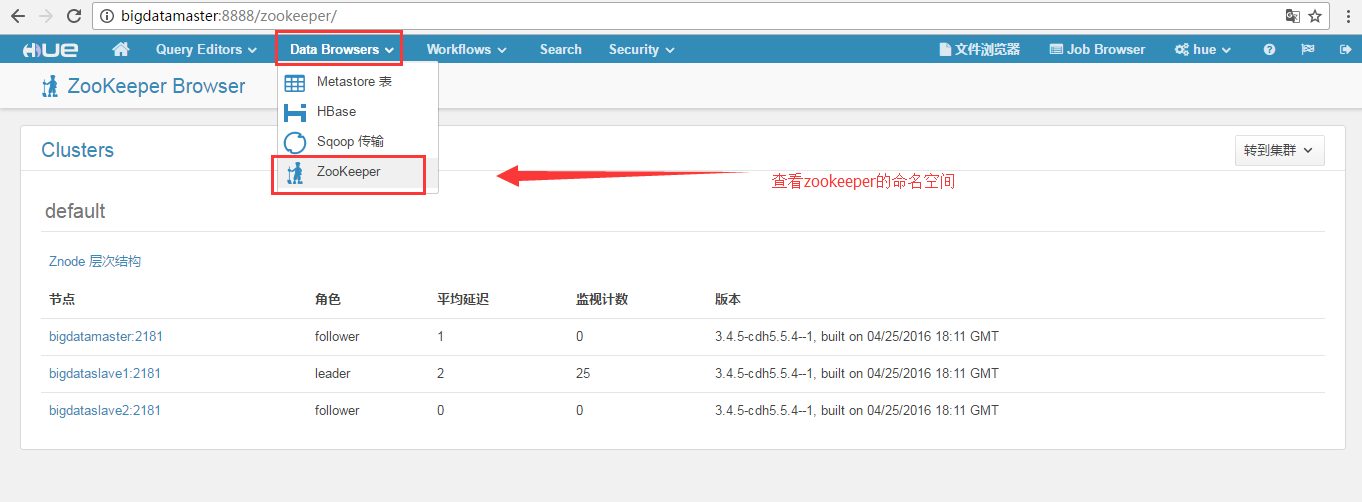
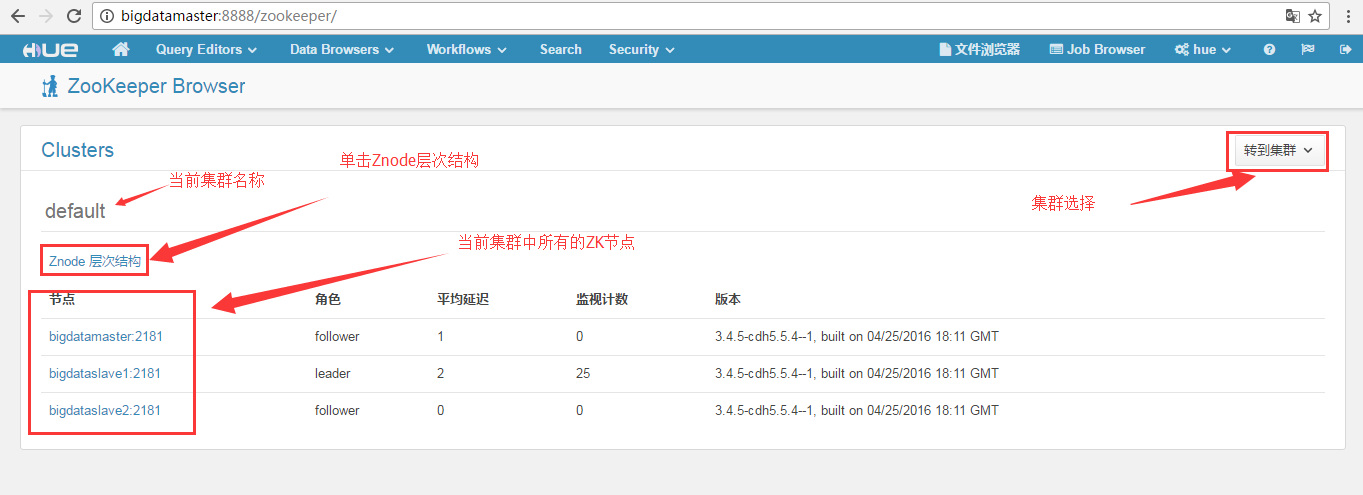
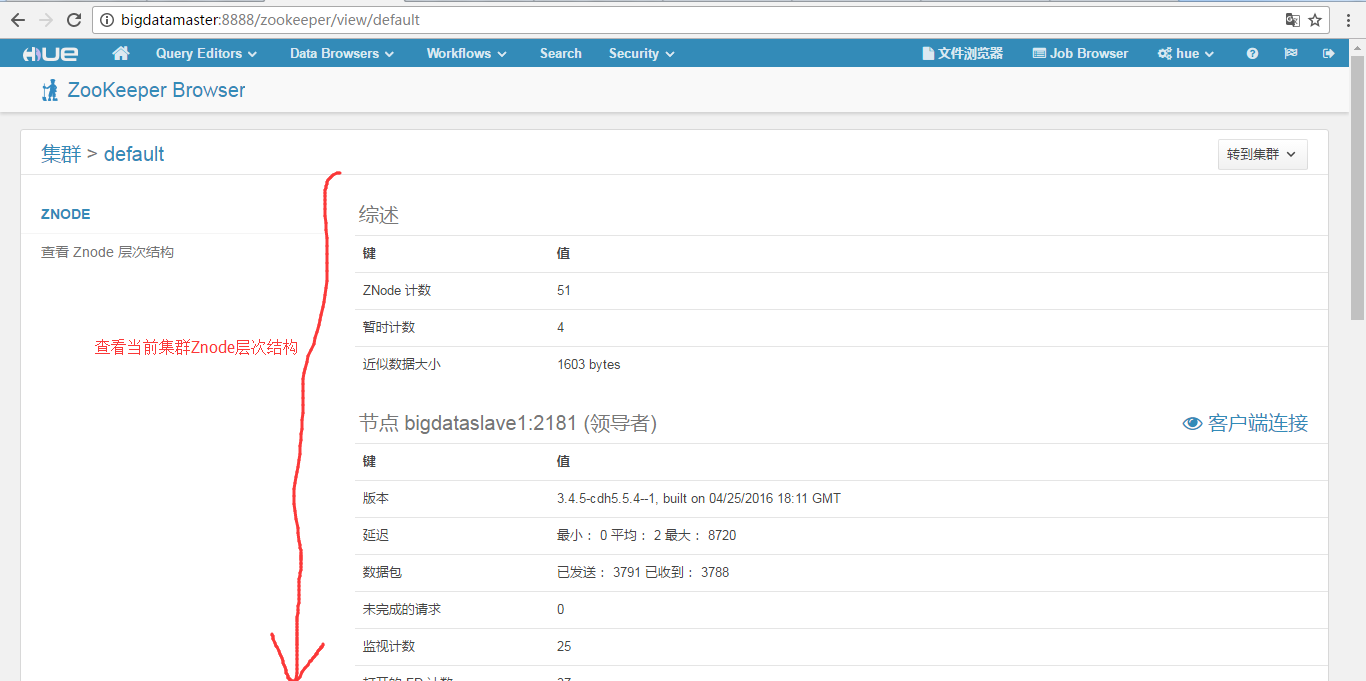
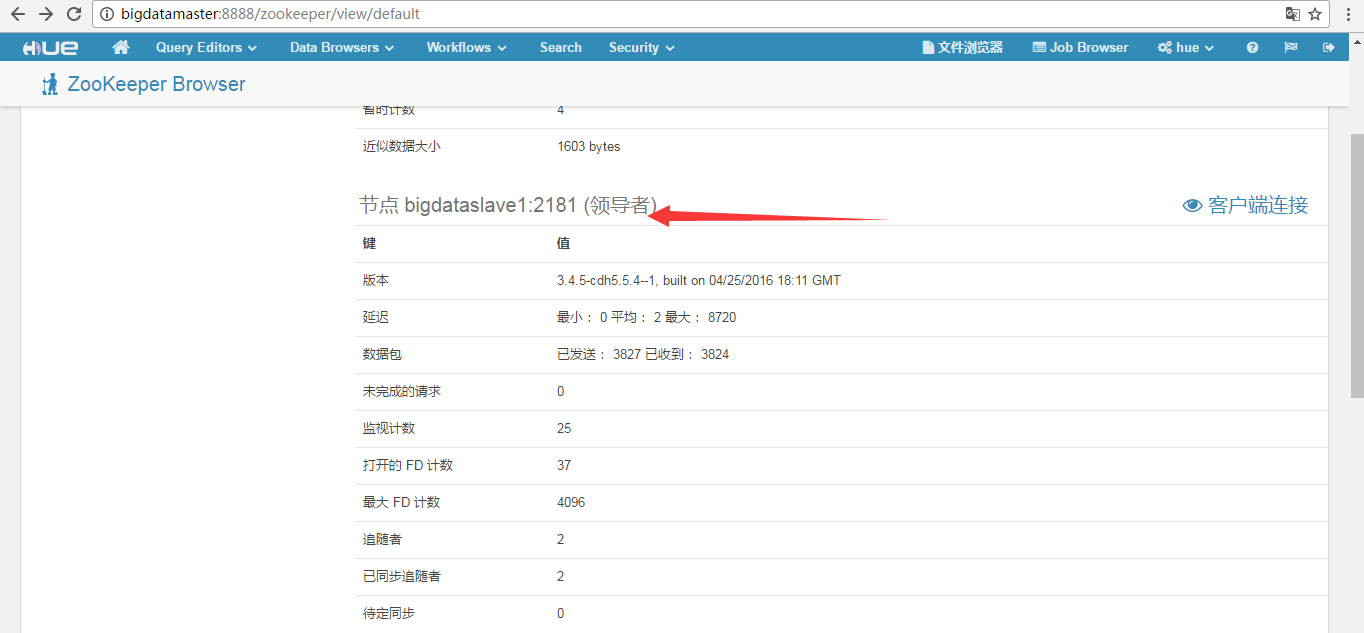
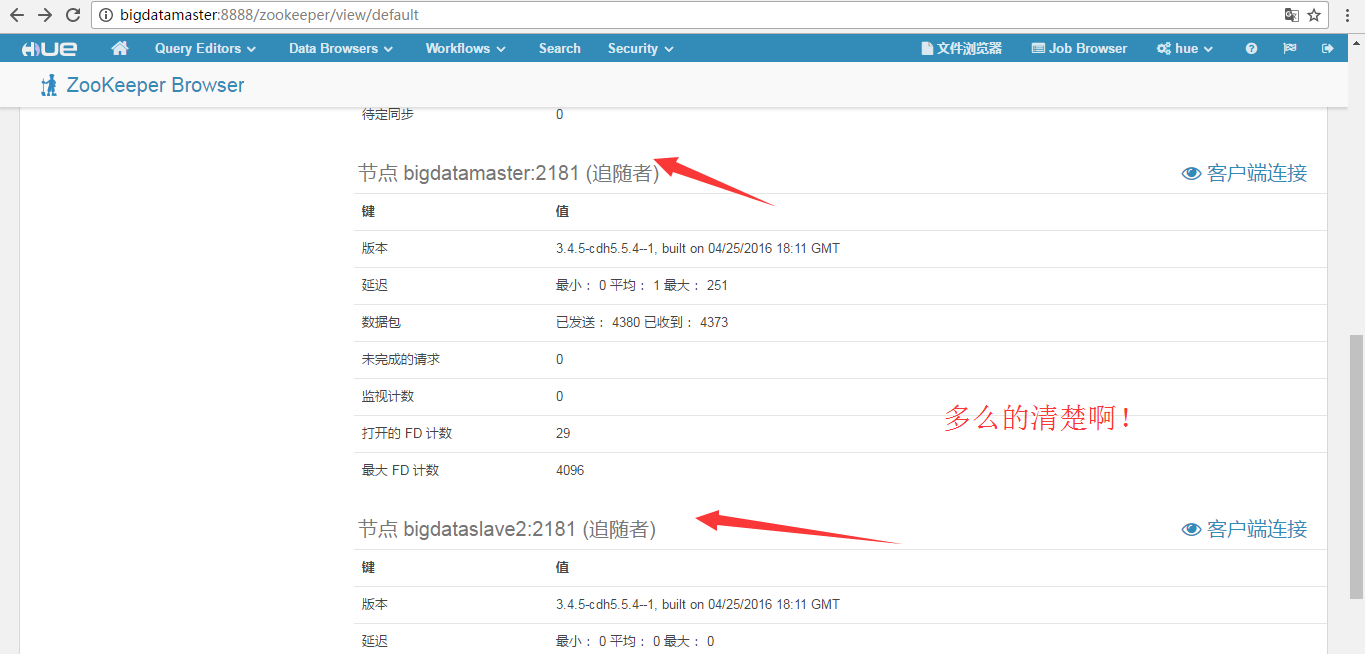
更多的细节,我这里不多赘述,大家自行去自己机器看吧!
成功!
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



HUE配置文件hue.ini 的zookeeper模块详解(图文详解)(分HA集群)的更多相关文章
- HUE配置文件hue.ini 的hbase模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的hdfs_clusters模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的yarn_clusters模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的Spark模块详解(图文详解)(分HA集群和HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的impala模块详解(图文详解)(分HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的filebrowser模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的hive和beeswax模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的database模块详解(包含qlite、mysql、 psql、和oracle)(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! Hue配置文件里,提及到,提供有postgresql_psycopg2, mysql, sqlite3 or oracle. 注意:Hue本身用到的是sqlite3. 在哪里呢, ...
- HUE配置文件hue.ini 的pig模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 一.默认的pig配置文件 ########################################################################### ...
随机推荐
- jquery 获取当前时间加180天
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding= ...
- django restframwork教程之Request和Response
从这一篇文章开始,我们会覆盖整个REST framwork框架的核心,接下来让我们介绍一些基础的构建块 Request 对象 REST framework 引入了一个扩展HttpRequest的请求对 ...
- 我觉得epoll和select最大的区别
最近在用epoll,网速资料很多,大家都说epoll和select的区别比较大,而且select要不停遍历所有的fd,效率要低,而且fd有限制. 但是我认为二者最大的区别在于 先看代码 while ( ...
- Angular基础---->AngularJS的使用(一)
AngularJS主要用于构建单页面的Web应用.它通过增加开发人员和常见Web应用开发任务之间的抽象级别,使构建交互式的现代Web应用变得更加简单.今天,我们就开始Angular环境的搭建和第一个实 ...
- Linux学习——自定义shell终端提示符
转自:here 我使用的Linux发行版是LinuxMint 17.2 Rafaela,默认情况下Terminal中的shell提示包括了用户名.主机名.当前目录(绝对路径)和提示符.这样会导致当进入 ...
- 关于Android图片资源瘦身的奇思妙想
版权声明:本文由况鹰原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/77 来源:腾云阁 https://www.qcloud ...
- Java可视化JVM监控软件
jdk自带.jdk安装目录下 1.JConsole 选择 不安全 可用不多 2.VisualVM
- [USB] Windows USB/DVD Download Tool
此工具为微软官方U盘启动盘制作工具 Windows USB/DVD Download Tool 说明:https://www.microsoft.com/en-us/download/windows- ...
- Pentaho Report Designer 数据大于某值显示红色
在细节栏中的字段的属性, 在样式的text-color,右边的表达式 输入下面表达式即可! =IF( [ALL_VALUE] > 50 ; "black" ; IF([ALL ...
- poj3171 Cleaning Shifts【线段树(单点修改区间查询)】【DP】
Cleaning Shifts Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 4422 Accepted: 1482 D ...