大数据处理框架之Strom:认识storm
Storm是分布式实时计算系统,用于数据的实时分析、持续计算,分布式RPC等。
(备注:5种常见的大数据处理框架:· 仅批处理框架:Apache Hadoop;· 仅流处理框架:Apache Storm 和 Apache Samza;· 混合框架:Apache Spark 和 Apache Flink)
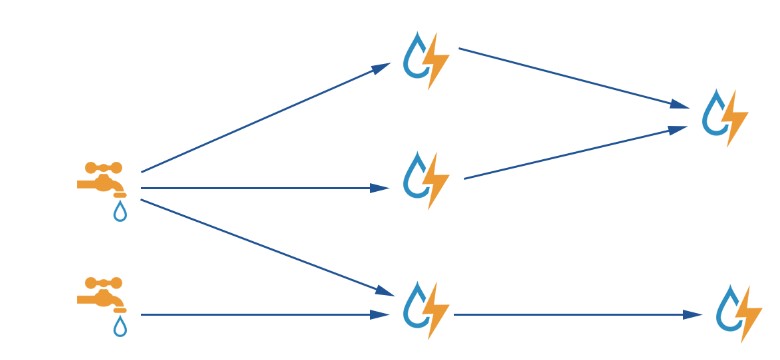
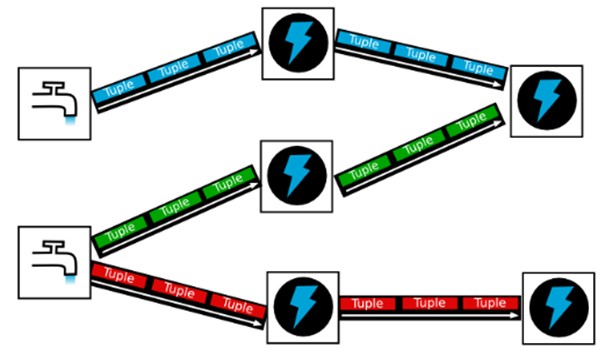
水龙头出来的是水滴 不是水流柱说明单个数据量小,但是连续不断的,后面水滴加闪电 表示处理迅速。
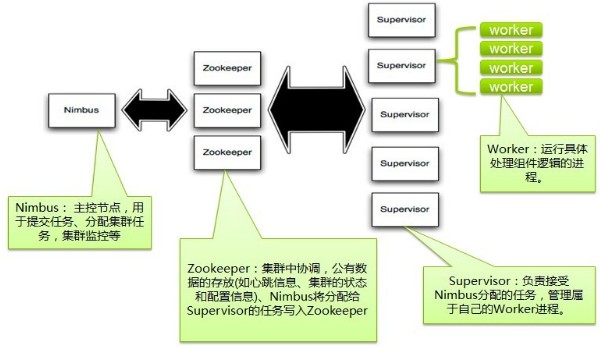
一、storm架构结构
二、Strom和Hadoop 分类对比
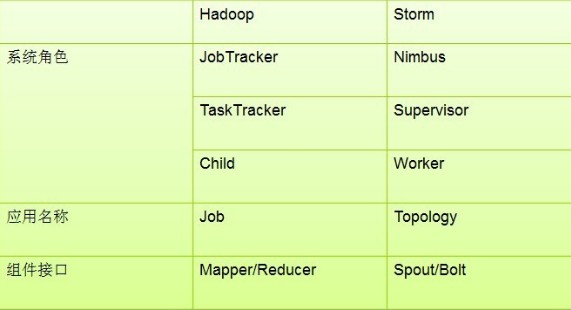

两者应用场景不同:
Storm:进程、线程常驻内存运行,数据不进入磁盘,数据通过网络传递,因此处理的单个数据大小不能过大。
MapReduce:为TB、PB级别数据设计的批处理计算框架。
三、Storm和Spark Streaming
Storm:纯流式处理,专门为流式处理设计,数据传输模式更为简单,很多地方也更为高效,并不是不能做批处理,它也可以来做微批处理,来提高吞吐;
Spark Streaming:微批处理,将RDD做的很小来用小的批处理来接近流式处理,基于内存和DAG可以把处理任务做的很快;
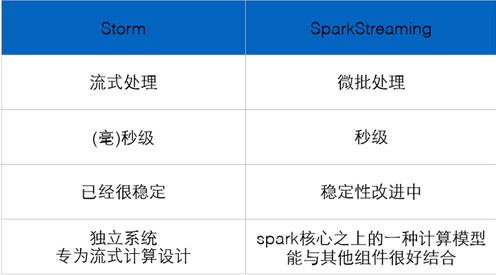
storm是一个独立的框架,sparkstreaming是spark家族中一员,在大多数大数据应用场景下 使用sparkstreaming用的多一些;在独立的应用场景下 使用strom即可
四、Storm计算模型
系统角色组件
Nimbus:即Storm的Master,负责资源分配和任务调度。一个Storm集群只有一个Nimbus。
Supervisor:即Storm的Slave,负责接收Nimbus分配的任务,管理所有Worker,一个Supervisor节点中包含多个Worker进程。
Worker:工作进程,每个工作进程中都有多个Task。
Task:任务,在 Storm 集群中每个 Spout 和 Bolt 都由若干个任务(tasks)来执行。每个任务都与一个执行线程相对应。
应用名称组件
Topology:计算拓扑,有向的工作流程图(DAG),Storm 的拓扑是对实时计算应用逻辑的封装,它的作用与 MapReduce 的任务(Job)很相似,区别在于 MapReduce 的一个 Job 在得到结果之后总会结束,而拓扑会一直在集群中运行,直到你手动去终止它。拓扑还可以理解成由一系列通过数据流(Stream Grouping)相互关联的 Spout 和 Bolt 组成的的拓扑结构。
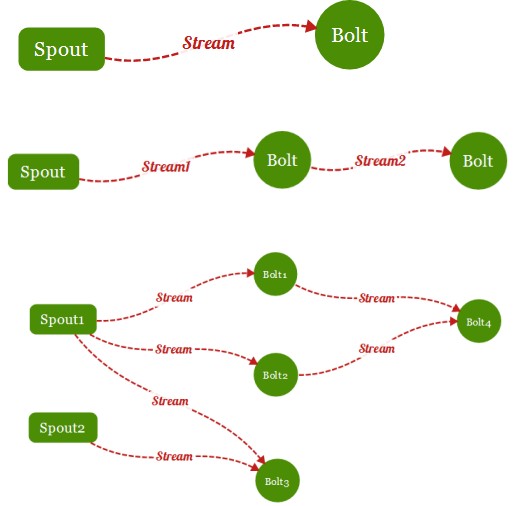
组件接口
(1)Spout-数据源:
拓扑中数据流的来源。一般会从指定外部的数据源读取元组(Tuple)发送到拓扑(Topology)中;
一个Spout可以发送多个数据流(Stream);
可先通过OutputFieldsDeclarer中的declare方法声明定义的不同数据流,发送数据时通过SpoutOutputCollector中的emit方法指定数据流Id(streamId)参数将数据发送出去
Spout中最核心的方法是nextTuple,该方法会被Storm线程不断调用、主动从数据源拉取数据,再通过emit方法将数据生成元组(Tuple)发送给之后的Bolt计算;
(2)Bolt-数据流处理组件:
拓扑中数据处理均有Bolt完成。对于简单的任务或者数据流转换,单个Bolt可以简单实现;更加复杂场景往往需要多个Bolt分多个步骤完成
一个Bolt可以发送多个数据流(Stream)
可先通过OutputFieldsDeclarer中的declare方法声明定义的不同数据流,发送数据时通过SpoutOutputCollector中的emit方法指定数据流Id(streamId)参数将数据发送出去
Bolt中最核心的方法是execute方法,该方法负责接收到一个元组(Tuple)数据、真正实现核心的业务逻辑
(3)tuple-元组:
storm使用tuple来作为它的数据模型。每个tuple是一堆值,每个值有一个名字,并且每个值可以是任何类型, 在我的理解里面一个tuple可以看作一个没有方法的java对象。总体来看,storm支持所有的基本类型、字符串以及字节数组作为tuple的值类 型。你也可以使用你自己定义的类型来作为值类型, 只要你实现对应的序列化器(serializer)。

(4)Stream:
数据流(Streams)是 Storm 中最核心的抽象概念。一个数据流指的是在分布式环境中并行创建、处理的一组元组(tuple)的无界序列。数据流可以由一种能够表述数据流中元组的域(fields)的模式来定义。一个没有边界的、源源不断的、连续的Tuple序列就组成了Stream。

(5)Stream grouping-数据分发策略:
为拓扑中的每个 Bolt 的确定输入数据流是定义一个拓扑的重要环节。数据流分组定义了在 Bolt 的不同任务(tasks)中划分数据流的方式。在 Storm 中有八种内置的数据流分组方式。
(5.1)Shuffle Grouping
随机分组,随机派发stream里面的tuple,保证每个bolt task接收到的tuple数目大致相同。
轮询,平均分配
(5.2)Fields Grouping
按字段分组,比如,按"user-id"这个字段来分组,那么具有同样"user-id"的 tuple 会被分到相同的Bolt里的一个task, 而不同的"user-id"则可能会被分配到不同的task。
(5.3)All Grouping
广播发送,对于每一个tuple,所有的bolts都会收到
(5.4)Global Grouping
全局分组,把tuple分配给task id最低的task 。
(5.5)None Grouping
不分组,这个分组的意思是说stream不关心到底怎样分组。目前这种分组和Shuffle grouping是一样的效果。 有一点不同的是storm会把使用none grouping的这个bolt放到这个bolt的订阅者同一个线程里面去执行(未来Storm如果可能的话会这样设计)。
(5.6)Direct Grouping
指向型分组, 这是一种比较特别的分组方法,用这种分组意味着消息(tuple)的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为 Direct Stream 的消息流可以声明这种分组方法。而且这种消息tuple必须使用 emitDirect 方法来发射。消息处理者可以通过 TopologyContext 来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)
(5.7)Local or shuffle grouping
本地或随机分组。如果目标bolt有一个或者多个task与源bolt的task在同一个工作进程中,tuple将会被随机发送给这些同进程中的tasks。否则,和普通的Shuffle Grouping行为一致
(5.8)customGrouping
自定义,相当于mapreduce那里自己去实现一个partition一样。
(6)Reliability:可靠性。Storm 可以通过拓扑来确保每个发送的元组都能得到正确处理。通过跟踪由 Spout 发出的每个元组构成的元组树可以确定元组是否已经完成处理。每个拓扑都有一个“消息延时”参数,如果 Storm 在延时时间内没有检测到元组是否处理完成,就会将该元组标记为处理失败,并会在稍后重新发送该元组。
备注:在0.90版本以前默认使用zeroMQ做底层通信,之后的版本默认适用Netty。
五、storm应用场景
1、异步处理
客户端提交数据进行结算,并不会等待数据计算结果,比如逐条处理(ETL)、统计分析(计算PV、UV、访问热点 以及 某些数据的聚合、加和、平均等,客户端提交数据之后,计算完成结果存储到Redis、HBase、MySQL或者其他MQ当中,客户端并不关心最终结果是多少)

2、同步处理
客户端提交数据请求之后,立刻取得计算结果并返回给客户端,比如DRPC

大数据处理框架之Strom:认识storm的更多相关文章
- 大数据处理框架之Strom: Storm----helloword
大数据处理框架之Strom: Storm----helloword Storm按照设计好的拓扑流程运转,所以写代码之前要先设计好拓扑图.这里写一个简单的拓扑: 第一步:创建一个拓扑类含有main方法的 ...
- 大数据处理框架之Strom:Flume+Kafka+Storm整合
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 storm-0.9 apache-flume-1.6.0 ...
- 大数据处理框架之Strom: Storm拓扑的并行机制和通信机制
一.并行机制 Storm的并行度 ,通过提高并行度可以提高storm程序的计算能力. 1.组件关系:Supervisor node物理节点,可以运行1到多个worker,不能超过supervisor. ...
- 大数据处理框架之Strom:Storm集群环境搭建
搭建环境 Red Hat Enterprise Linux Server release 7.3 (Maipo) zookeeper-3.4.11 jdk1.7.0_80 Pyth ...
- 大数据处理框架之Strom:redis storm 整合
storm 引入redis ,主要是使用redis缓存库暂存storm的计算结果,然后redis供其他应用调用取出数据. 新建maven工程 pom.xml <project xmlns=&qu ...
- 大数据处理框架之Strom:kafka storm 整合
storm 使用kafka做数据源,还可以使用文件.redis.jdbc.hive.HDFS.hbase.netty做数据源. 新建一个maven 工程: pom.xml <project xm ...
- 大数据处理框架之Strom:DRPC
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 storm-0.9 一.DRPC DRPC:Distri ...
- 大数据处理框架之Strom:容错机制
1.集群节点宕机Nimbus服务器 单点故障,大部分时间是闲置的,在supervisor挂掉时会影响,所以宕机影响不大,重启即可非Nimbus服务器 故障时,该节点上所有Task任务都会超时,Nimb ...
- 大数据处理框架之Strom:事务
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 storm-0.9 apache-flume-1.6.0 ...
随机推荐
- linux测试环境搭建步骤
一.建用户 1.新建用户root用户登录,执行命令:useradd + 用户名 -m -d + 指定路径如:新建用户liuwq ,指定路径/home/ios命令:useradd liuwq -m -d ...
- openssl编译参数选项
执行Configure是常见参数选项如下: 安装参数: --openssldir=OPENSSLDIR 安装目录,默认是 /usr/local/ssl . --prefix=PREFIX 设置 lib ...
- 洛谷P4247 序列操作 [清华集训] 线段树
正解:线段树 解题报告: 传送门! 通过这题我get了一个神奇的,叫,线段树五问的东西hhhh 听起来有点中二但感觉真正做题的时候还是比较有用的,,,?感觉会让条理清晰很多呢,所以放一下QwQ →每个 ...
- WPF 参数在Page见传递
void goButton_Click(object sender, RoutedEventArgs e) { this.NavigationService.Navigate(new ContentP ...
- gitlab小结
部署Gitlab环境完整记录(我用的是11版本的gitlab,为了后面不出现bug,请选择11) gitlab启用https的配置 gitlab强制修改密码 https://www.cnblogs.c ...
- UIKIT_EXTERN和define定义常量
看过我其他的博客的人都知道,我喜欢用define定义常量,最近看了一个开源的轮子,使用UIKIT_EXTERN这个定义的常量,了解了一下,发现使用宏定义的常量会在内存中临时开辟一份内存空间,而使用UI ...
- 006-docker-安装-nginx
1.搜索镜像 docker search nginx 2.拉取合适镜像 docker pull nginx docker images 3.使用镜像 docker run -p 8080:80 --n ...
- webstorm2018版安装-破解
安装完成后到下面网址下载破解补丁 网址:http://idea.lanyus.com/ 修改路径 修改同目录下的 WebStorm.exe.vmoptions 和WebStorm64.exe.vmop ...
- c 字符数组与字符串
char a[]="abc"; printf( char str[]="abc"; int size = sizeof(str)/sizeof(char); p ...
- DAX/PowerBI系列 - 参数表(Parameter Table) - 大客户分析(Top N)
DAX/PowerBI系列 - 参数表(Parameter Table) - 大客户分析(Top N) 难度: ★☆☆☆☆(1星) 适用范围: ★★★☆☆(3星) 概况:此文为DAX/PowerBI系 ...