4.1:简单python爬虫
简单python爬虫
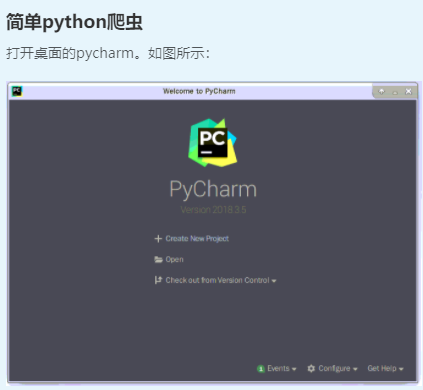
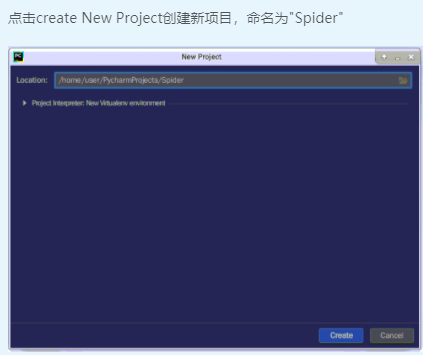
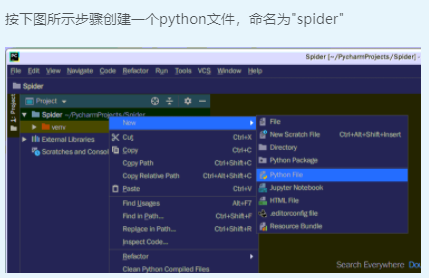
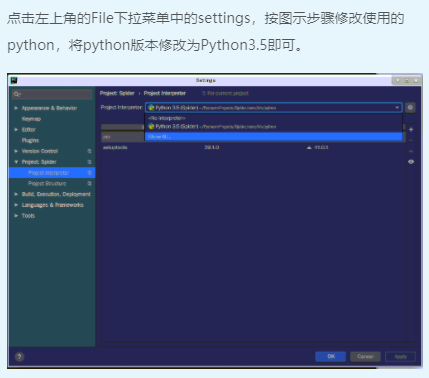
在创建的python文件中输入下列代码:
# coding:utf-8
import requests
from bs4 import BeautifulSoup def spider(url,headers):
with open('renming.txt', 'w', encoding='utf-8') as fp:
r = requests.get(url, headers=headers)
r.encoding = 'gb2312'
# test=re.findall('<li>< a href= >(.*?)</ a></li>',r.text)
# print(test)
soup = BeautifulSoup(r.text, "html.parser")
for news_list in soup.find_all(class_="list14"):
content = news_list.text.strip()
fp.write(content)
fp.close() if __name__=="__main__":
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/55.0.2883.87 Safari/537.36'} url = 'http://www.people.com.cn/'
spider(url, headers)
如果代码中存在报错,请在PyCharm最下边找到Terminal,点击Terminal后Pycharm底部控制台处会出现其自带的命令行窗口,输入下面两条命令即可解决报错:pip install requestspip install bs4解决完报错之后,在代码文件的任意处右击,点击Run,之后就会发现在代码文件目录中出现了renmin.txt,里面是爬取的人民网的数据。

4.1:简单python爬虫的更多相关文章
- 一个简单python爬虫的实现——爬取电影信息
最近在学习网络爬虫,完成了一个比较简单的python网络爬虫.首先为什么要用爬虫爬取信息呢,当然是因为要比人去收集更高效. 网络爬虫,可以理解为自动帮你在网络上收集数据的机器人. 网络爬虫简单可以大致 ...
- 简单python爬虫实例
先放上url,https://music.douban.com/chart 这是豆瓣的一个音乐排行榜,这里爬取了左边部分的歌曲排行榜部分,爬虫很简单,就用到了beautifulsoup和request ...
- 简单python爬虫编写,Python采集妹子图!
疫情期间在家闲来无事,每天打游戏荒废了一段时间.我觉得自己不能在这么颓废下去,就立马起身写了一点python代码(本人只是python新手). 很多人学习python,不知道从何学起.很多人学习pyt ...
- 简单python爬虫案例(爬取慕课网全部实战课程信息)
技术选型 下载器是Requests 解析使用的是正则表达式 效果图: 准备好各个包 # -*- coding: utf-8 -*- import requests #第三方下载器 import re ...
- Selenium + PhantomJS + python 简单实现爬虫的功能
Selenium 一.简介 selenium是一个用于Web应用自动化程序测试的工具,测试直接运行在浏览器中,就像真正的用户在操作一样 selenium2支持通过驱动真实浏览器(FirfoxDrive ...
- python (1)一个简单的爬虫: python 在windows下 创建文件夹并写入文件
1.一个简单的爬虫:爬取豆瓣的热门电影的信息 写在前面:如何创建本来存在的文件夹并写入 t_path = "d:/py/inn" #本来不存在inn,先定义路径,然后如果不存在,则 ...
- 一个简单的多线程Python爬虫(一)
一个简单的多线程Python爬虫 最近想要抓取拉勾网的数据,最开始是使用Scrapy的,但是遇到了下面两个问题: 前端页面是用JS模板引擎生成的 接口主要是用POST提交参数的 目前不会处理使用JS模 ...
- 纯手工打造简单分布式爬虫(Python)
前言 这次分享的文章是我<Python爬虫开发与项目实战>基础篇 第七章的内容,关于如何手工打造简单分布式爬虫 (如果大家对这本书感兴趣的话,可以看一下 试读样章),下面是文章的具体内容. ...
- python爬虫——写出最简单的网页爬虫
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材.我们可以通过python 来实现这样一个简单的爬虫功能,把我们想要的 ...
- 一个简单的python爬虫程序
python|网络爬虫 概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web ...
随机推荐
- 【全网最全】springboot整合JSR303参数校验与全局异常处理
一.前言 我们在日常开发中,避不开的就是参数校验,有人说前端不是会在表单中进行校验的吗?在后端中,我们可以直接不管前端怎么样判断过滤,我们后端都需要进行再次判断,为了安全.因为前端很容易拜托,当测试使 ...
- 记录一下对jdk8后的接口的一些理解
对于jdk8后的接口,接口中加入了可以定义默认方法和静态方法. 为什么要这样设计呢? 是为了在给接口扩展方法的时候,不会影响已经实现了该接口的类 加入默认方法可以解决:在添加方法的同时,不影响现有的实 ...
- windows系统下使用bat脚本文件设置 JDK 系统环境变量
号开头的行不要写在bat文件中 # java_init.bat # 注意文件换行符是windows系统下的(CR LF),文件编码是ANSI # path变量追加这个可以拓展到tomcat,mysql ...
- 论文解读(FedGAT)《Federated Graph Attention Network for Rumor Detection》
论文信息 论文标题:Federated Graph Attention Network for Rumor Detection论文作者:Huidong Wang, Chuanzheng Bai, Ji ...
- 密码学奇妙之旅、03 HMAC单向散列消息认证码、Golang代码
HMAC 单向散列消息认证码 消息认证码MAC是用于确认完整性并进行认证的技术,消息认证码的输入包括任意长度的消息和一个发送者和接收者之间共享的密钥(可能还需要共享盐值). HMAC是使用单向散列函数 ...
- python的注释、变量
注释 注释是代码的解释型语言,不会影响代码执行,就是专门给程序员看的. 注释是很重要的代码组成部分! # 单行注释 ''' 多行注释 连续输入三个单引号 ''' """ ...
- flutter系列之:把box布局用出花来
目录 简介 LimitedBox SizedBox FittedBox 总结 简介 flutter中的layout有很多,基本上看layout的名字就知道这个layout到底是做什么用的.比如说这些l ...
- 【C++】GoogleTest进阶之gMock
gMock是什么 当我们去写测试时,有些测试对象很单纯简单,例如一个函数完全不依赖于其他的对象,那么就只需要验证其输入输出是否符合预期即可. 但是如果测试对象很复杂或者依赖于其他的对象呢?例如一个函数 ...
- GO编译时不避免引入外部动态库的解决方法
简介 最近碰到一个问题,有一个流量采集的组件中使用到了github.com/google/gopacket 这个库,这个库使用一切正常,但是唯独有一个缺点,编译后的二进制文件依赖于libpcap.so ...
- AI之强化学习、无监督学习、半监督学习和对抗学习
1.强化学习 @ 目录 1.强化学习 1.1 强化学习原理 1.2 强化学习与监督学习 2.无监督学习 3.半监督学习 4.对抗学习 强化学习(英语:Reinforcement Learning,简称 ...