Spark RDD/Core 编程 API入门系列 之rdd实战(rdd基本操作实战及transformation和action流程图)(源码)(三)
本博文的主要内容是:
1、rdd基本操作实战
2、transformation和action流程图
3、典型的transformation和action
RDD有3种操作:
1、 Trandformation 对数据状态的转换,即所谓算子的转换
2、 Action 触发作业,即所谓得结果的
3、 Contoller 对性能、效率和容错方面的支持,如cache、persist、checkpoint
Contoller包括cache、persist、checkpoint。
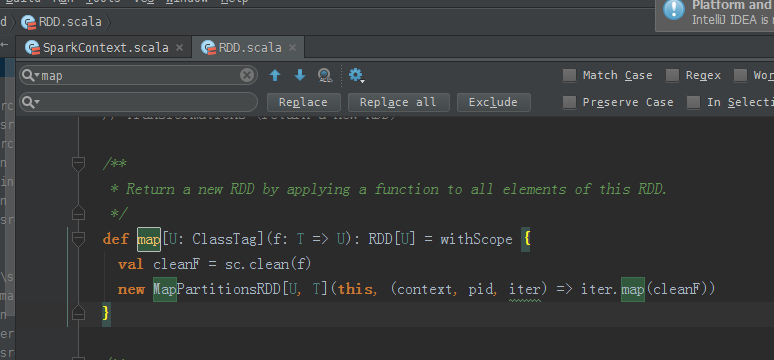
/**
* Return a new RDD by applying a function to all elements of this RDD.
*/
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
传入类型是T,返回类型是U。

元素之间,为什么reduce操作,要符合结合律和交换律?
答:因为,交换律,不知,哪个数据先过来。所以,必须符合交换律。
在交换律基础上,想要reduce操作,必须要符合结合律。 /**
* Reduces the elements of this RDD using the specified commutative and
* associative binary operator.
*/
def reduce(f: (T, T) => T): T = withScope {
val cleanF = sc.clean(f)
val reducePartition: Iterator[T] => Option[T] = iter => {
if (iter.hasNext) {
Some(iter.reduceLeft(cleanF))
} else {
None
}
}
var jobResult: Option[T] = None
val mergeResult = (index: Int, taskResult: Option[T]) => {
if (taskResult.isDefined) {
jobResult = jobResult match {
case Some(value) => Some(f(value, taskResult.get))
case None => taskResult
}
}
}
sc.runJob(this, reducePartition, mergeResult)
// Get the final result out of our Option, or throw an exception if the RDD was empty
jobResult.getOrElse(throw new UnsupportedOperationException("empty collection"))
}
RDD.scala(源码)
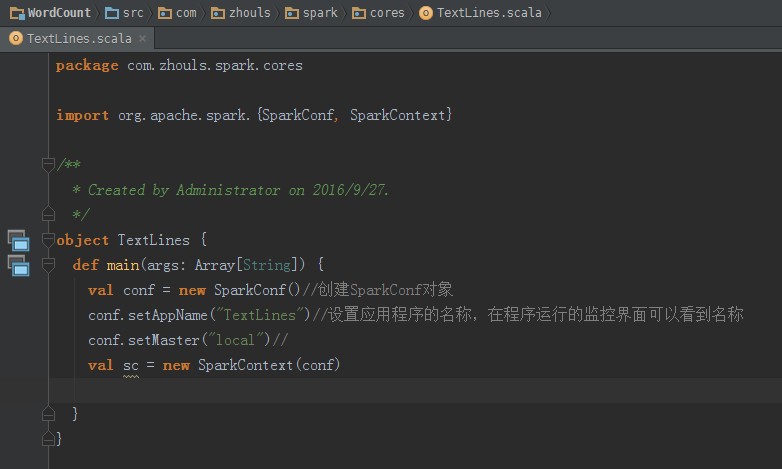
这里,新建包com.zhouls.spark.cores


package com.zhouls.spark.cores /**
* Created by Administrator on 2016/9/27.
*/
object TextLines { } 下面,开始编代码
本地模式
自动 ,会写好
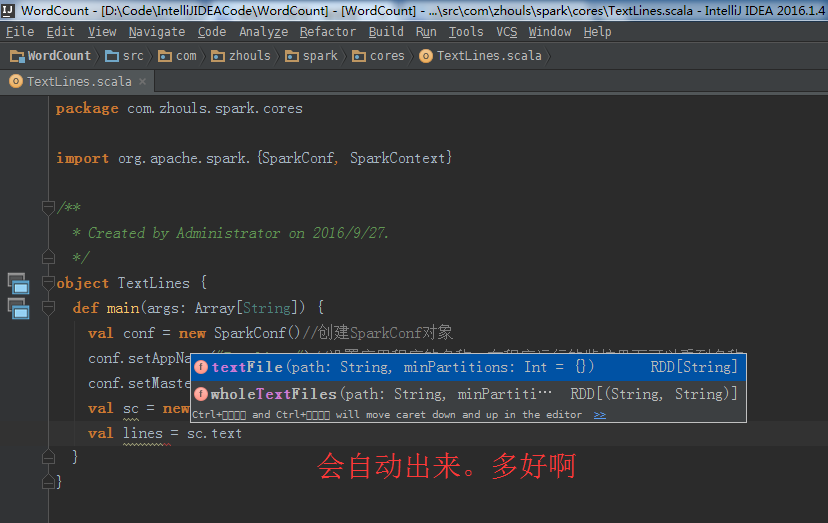

源码来看,



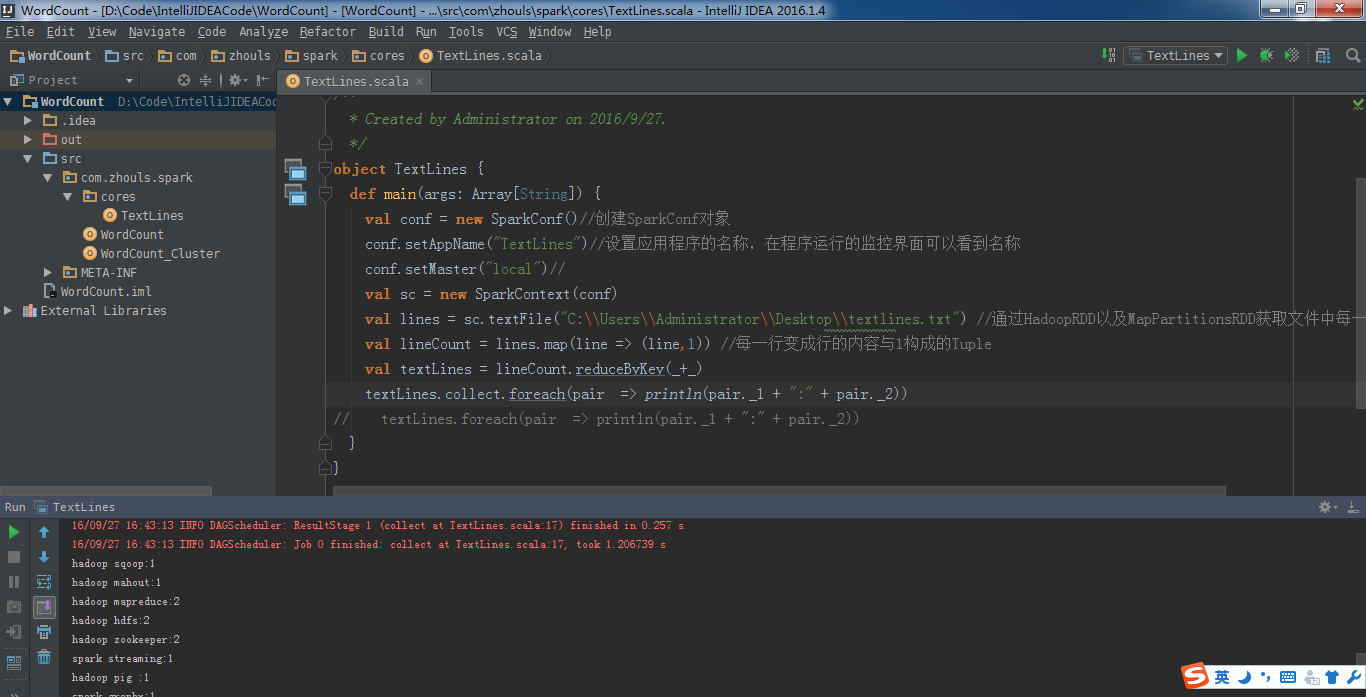
所以, val lines = sc.textFile("C:\\Users\\Administrator\\Desktop\\textlines.txt") //通过HadoopRDD以及MapPartitionsRDD获取文件中每一行的内容本身
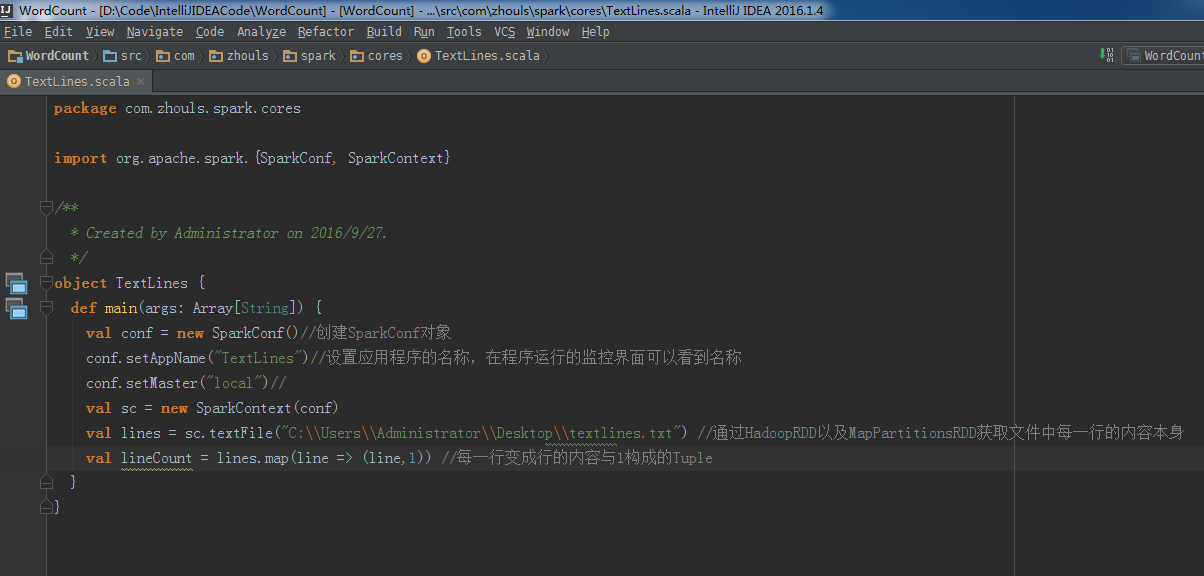
val lineCount = lines.map(line => (line,1)) //每一行变成行的内容与1构成的Tuple

val textLines = lineCount.reduceByKey(_+_)
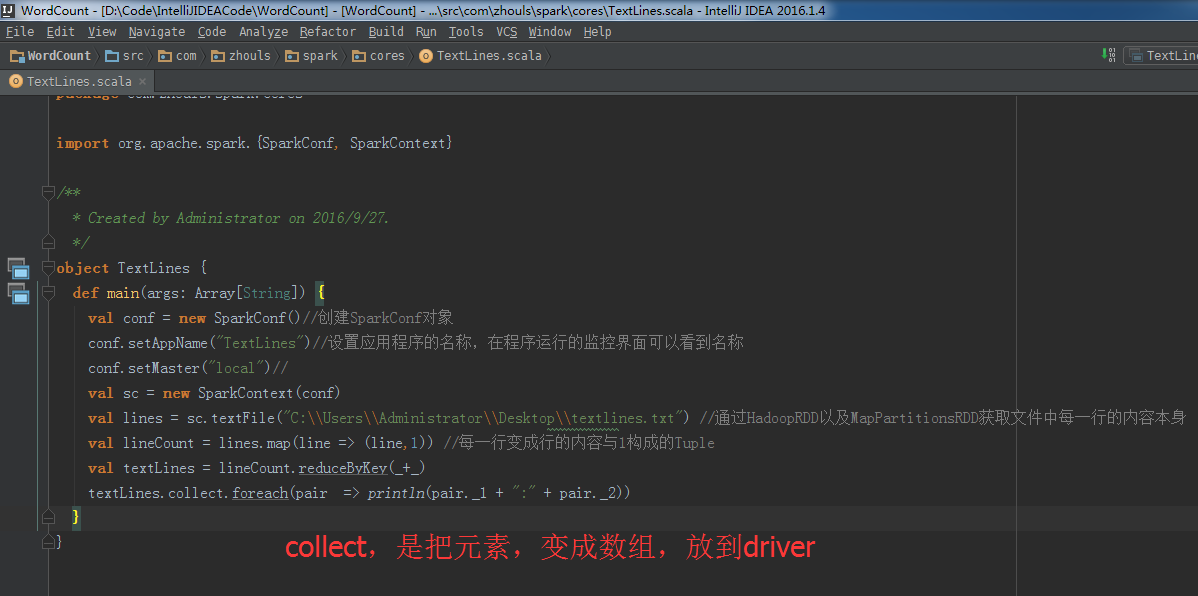
textLines.collect.foreach(pair => println(pair._1 + ":" + pair._2))

成功!
现在,将此行代码,
textLines.collect.foreach(pair => println(pair._1 + ":" + pair._2))
改一改
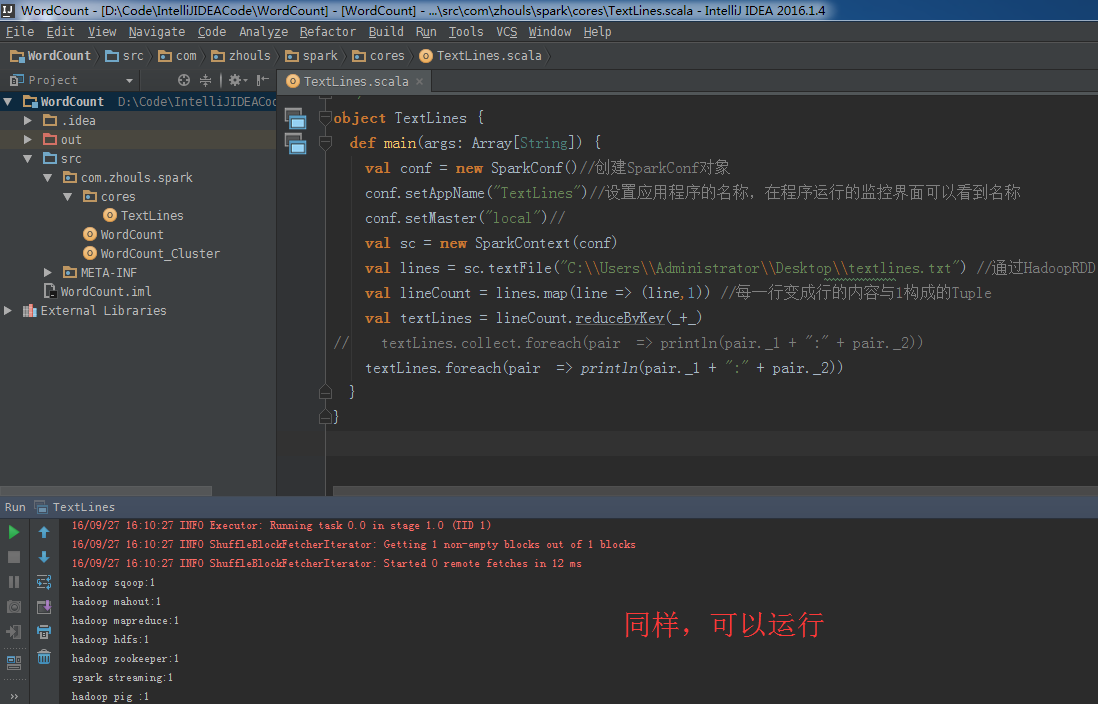
textLines.foreach(pair => println(pair._1 + ":" + pair._2))
总结:
本地模式里,
textLines.collect.foreach(pair => println(pair._1 + ":" + pair._2))
改一改
textLines.foreach(pair => println(pair._1 + ":" + pair._2))
运行正常,因为在本地模式下,是jvm,但这样书写,是不正规的。
集群模式里,
textLines.collect.foreach(pair => println(pair._1 + ":" + pair._2))
改一改
textLines.foreach(pair => println(pair._1 + ":" + pair._2))
运行无法通过,因为结果是分布在各个节点上。
collect源码:
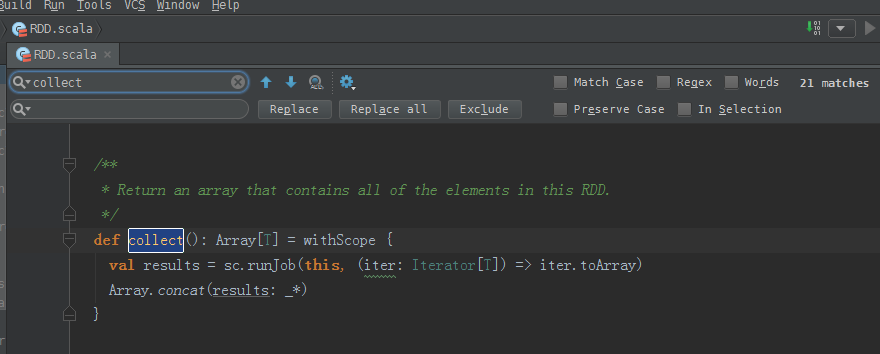
/**
* Return an array that contains all of the elements in this RDD.
*/
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
} 得出,collect后array中就是一个元素,只不过这个元素是一个Tuple。
Tuple是元组。通过concat合并!
foreach源码:
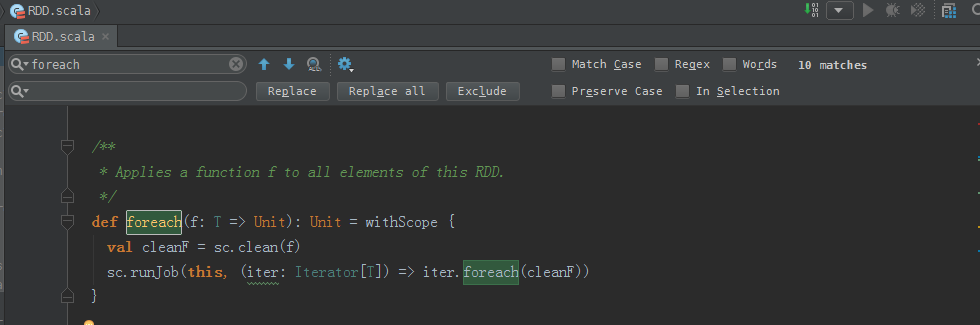
/**
* Applies a function f to all elements of this RDD.
*/
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}

rdd实战(rdd基本操作实战)至此!
rdd实战(transformation流程图)
拿wordcount为例!
启动hdfs集群
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ sbin/start-dfs.sh

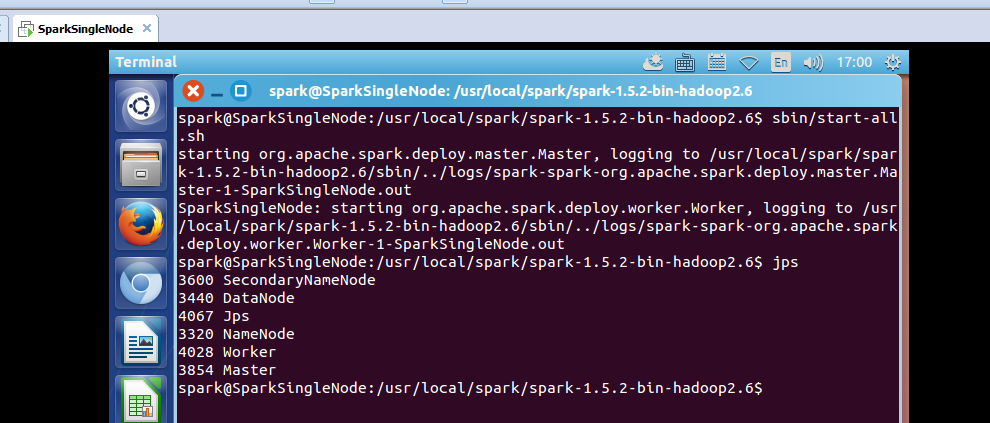
启动spark集群
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ sbin/start-all.sh
启动spark-shell
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/bin$ ./spark-shell --master spark://SparkSingleNode:7077 --executor-memory 1g
scala> val partitionsReadmeRdd = sc.textFile("hdfs://SparkSingleNode:9000/README.md").flatMap(_.split(" ")).map(word =>(word,1)).reduceByKey(_+_,1).saveAsTextFile("~/partition1README.txt")
或者
scala> val readmeRdd = sc.textFile("hdfs://SparkSingleNode:9000/README.md")
scala> val partitionsReadmeRdd = readmeRdd.flatMap(_.split(" ")).map(word => (word,1)).reduceByKey(_+_,1)
.saveAsTextFile("~/partition1README.txt")


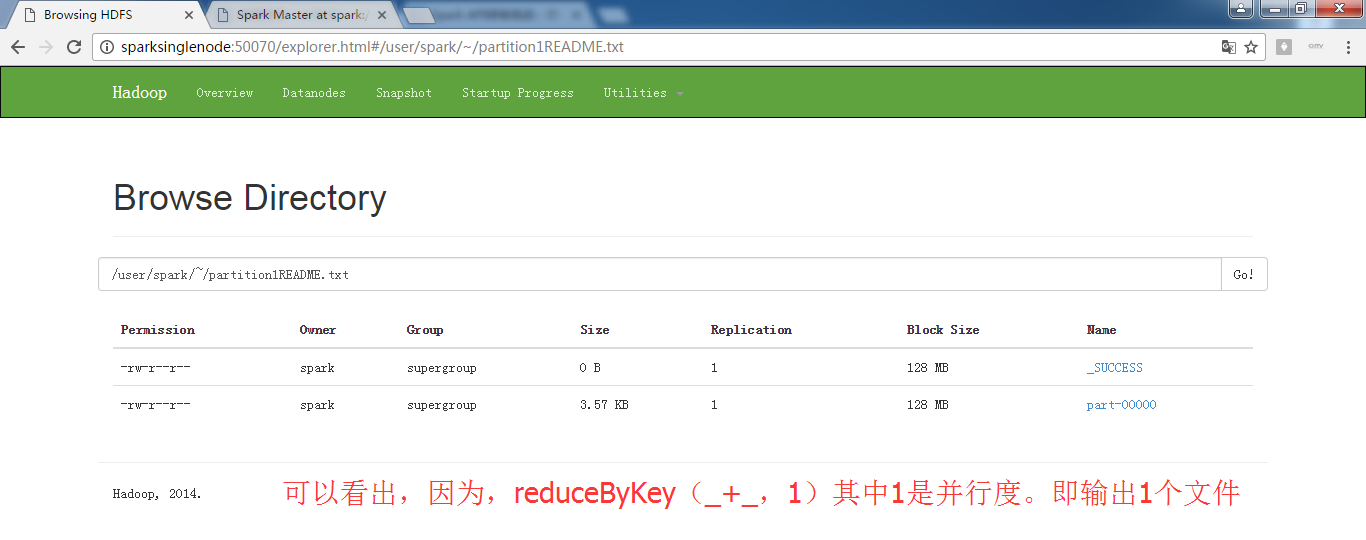

注意,~目录,不是这里。

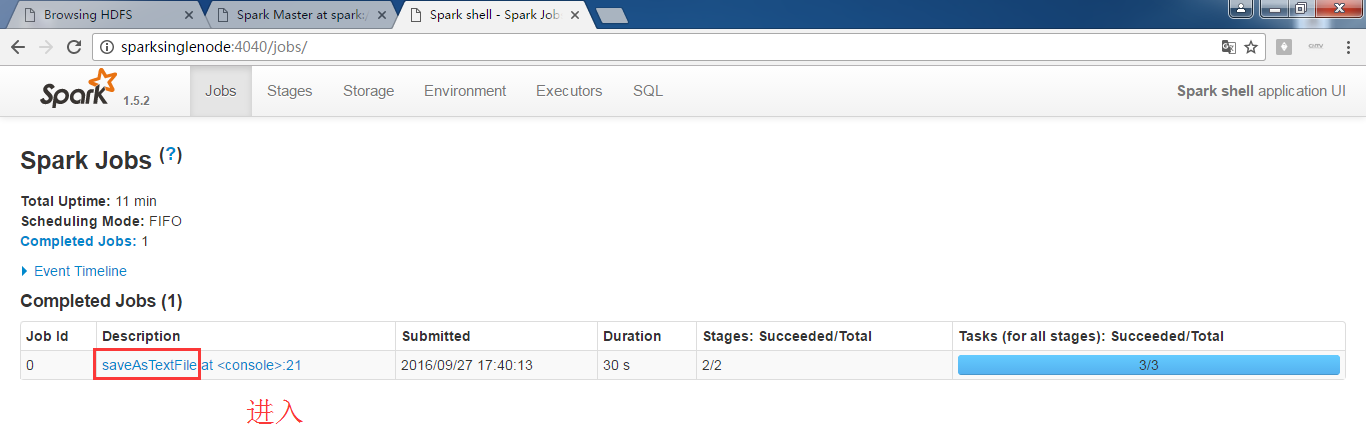

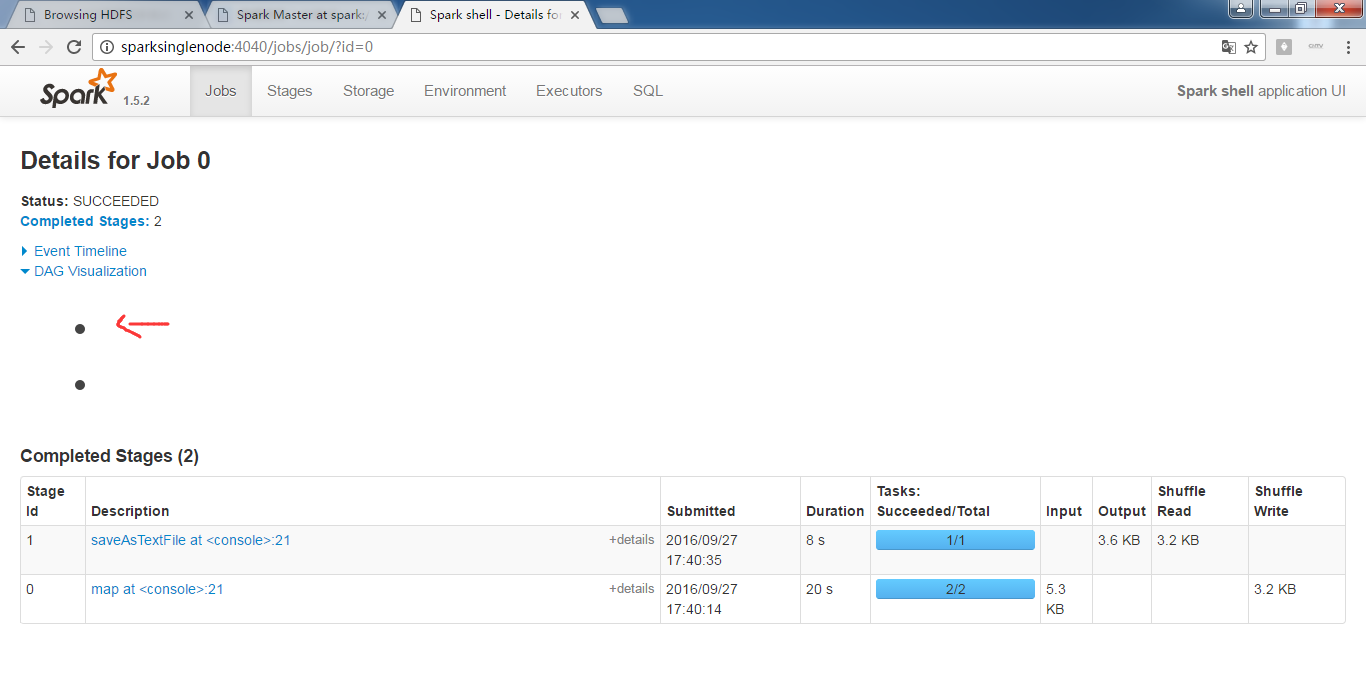
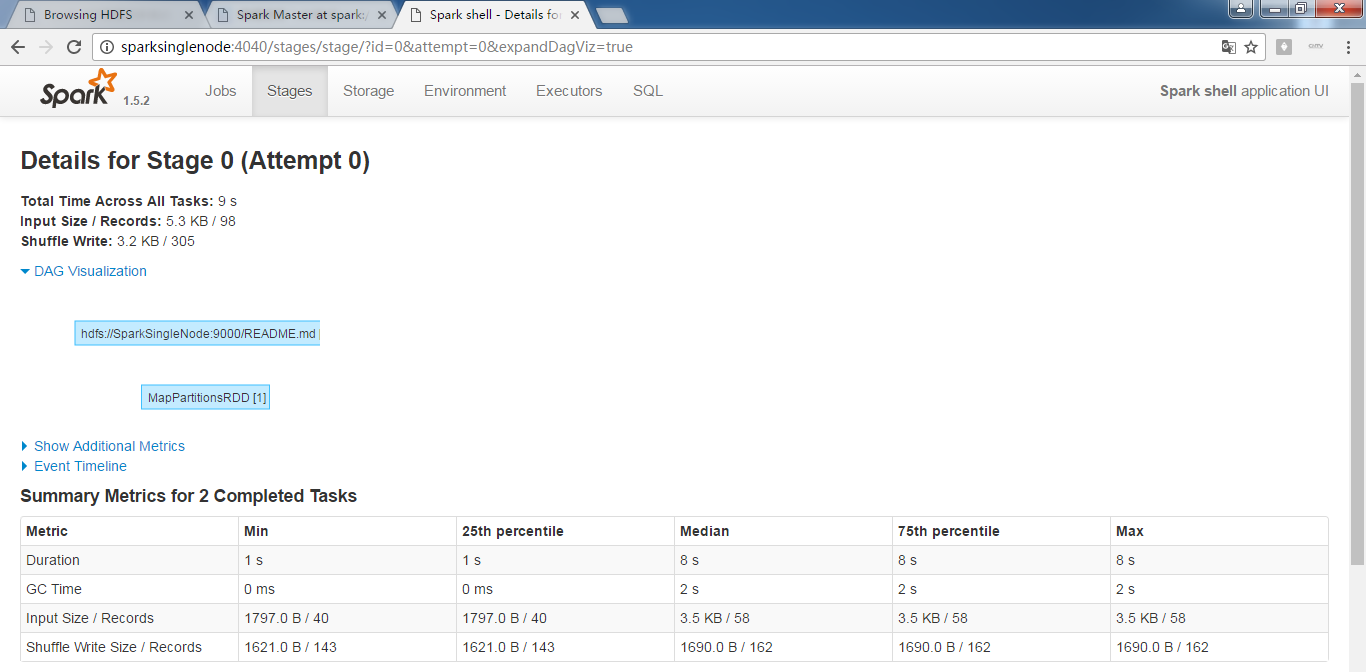
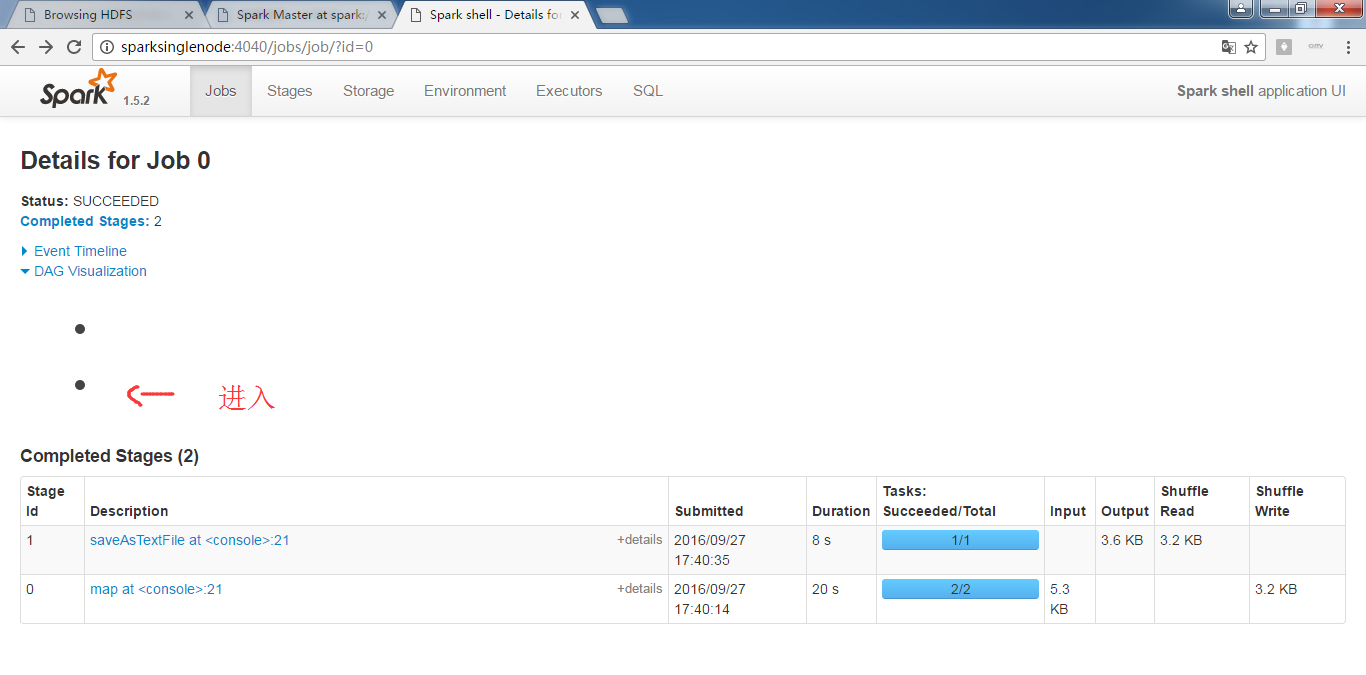

为什么,我的,不是这样的显示呢?
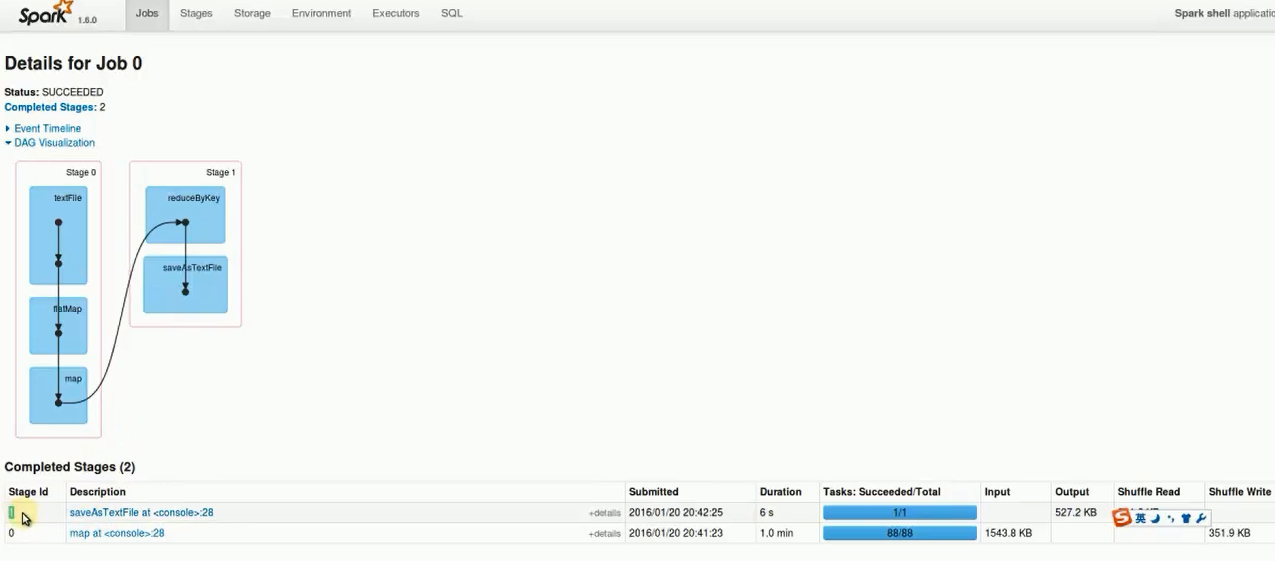
RDD的transformation和action执行的流程图
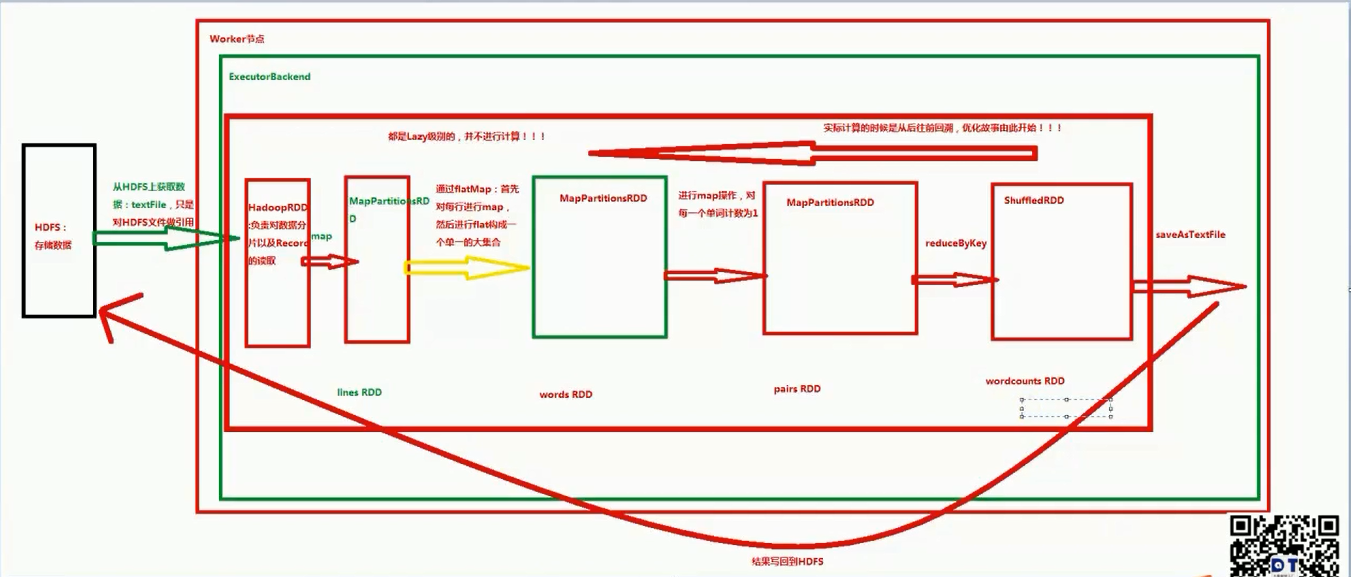
典型的transformation和action

Spark RDD/Core 编程 API入门系列 之rdd实战(rdd基本操作实战及transformation和action流程图)(源码)(三)的更多相关文章
- Spark RDD/Core 编程 API入门系列之简单移动互联网数据(五)
通过对移动互联网数据的分析,了解移动终端在互联网上的行为以及各个应用在互联网上的发展情况等信息. 具体包括对不同的应用使用情况的统计.移动互联网上的日常活跃用户(DAU)和月活跃用户(MAU)的统计, ...
- Spark RDD/Core 编程 API入门系列 之rdd案例(map、filter、flatMap、groupByKey、reduceByKey、join、cogroupy等)(四)
声明: 大数据中,最重要的算子操作是:join !!! 典型的transformation和action val nums = sc.parallelize(1 to 10) //根据集合创建RDD ...
- Spark RDD/Core 编程 API入门系列之动手实战和调试Spark文件操作、动手实战操作搜狗日志文件、搜狗日志文件深入实战(二)
1.动手实战和调试Spark文件操作 这里,我以指定executor-memory参数的方式,启动spark-shell. 启动hadoop集群 spark@SparkSingleNode:/usr/ ...
- Spark RDD/Core 编程 API入门系列之map、filter、textFile、cache、对Job输出结果进行升和降序、union、groupByKey、join、reduce、lookup(一)
1.以本地模式实战map和filter 2.以集群模式实战textFile和cache 3.对Job输出结果进行升和降序 4.union 5.groupByKey 6.join 7.reduce 8. ...
- Spark SQL 编程API入门系列之SparkSQL的依赖
不多说,直接上干货! 不带Hive支持 <dependency> <groupId>org.apache.spark</groupId> <artifactI ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- HBase编程 API入门系列之create(管理端而言)(8)
大家,若是看过我前期的这篇博客的话,则 HBase编程 API入门系列之put(客户端而言)(1) 就知道,在这篇博文里,我是在HBase Shell里创建HBase表的. 这里,我带领大家,学习更高 ...
- HBase编程 API入门系列之delete(客户端而言)(3)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面的基础,如下 HBase编程 API入门系列之put(客户端而言)(1) HBase编程 API入门系列之get(客户端而言) ...
- HBase编程 API入门系列之get(客户端而言)(2)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面是基础,如下 HBase编程 API入门系列之put(客户端而言)(1) package zhouls.bigdata.Hba ...
随机推荐
- getDrawingRect,getHitRect,getLocalVisibleRect,getGlobalVisibleRect
本文主要大体讲下getHitRect().getDrawingRect().getLocalVisibleRect().getGlobalVisibleRect. getLocationOnScree ...
- PL/SQL学习(三)游标
原文参考:http://plsql-tutorial.com/ 两种类型: 隐式: 执行INSERT.UPDATE.DELETE 或者只返回一条结果的SELECT语句时默认创建 ...
- css3怎么隐藏dom:4种方法
1.display:none; 2.position:absolute; left:-99999px; 3.visibility:hidden; 4.opacity:0;
- yii2源码学习笔记(十一)
Controller控制器类,是所有控制器的基类,用于调用模型和布局. <?php /** * @link http://www.yiiframework.com/ * @copyright C ...
- Ubuntu的关机重启命令知识
Ubuntu的关机重启命令知识,以作备忘. 重启命令: 1.reboot 2.shutdown -r now 立刻重启(root用户使用) 3.shutdown -r 10 过10分钟自动重启(roo ...
- PHP、JSP、.NET各自的真正优势是什么
PHP的优势在于, 跨平台, 极易部署, 易维护, 为Web而生, 开源社区强大, 文档丰富.至于说3足鼎立, 谈不上, 全球前100万的sites中, 70%是PHP. JSP和Asp..net 也 ...
- Learn Docker
Learn Docker A Container is to VM today, what VM was to Physical Servers a while ago. The workload s ...
- 【原】jQuery编写插件
分享一下编写设置和获取颜色的插件,首先我将插件的名字命名为jquery.color.js.该插件用来实现以下两个功能1.设置元素的颜色.2.获取元素的颜色. 先在搭建好如下编写插件的框架: ;(fun ...
- Memcached(二)Memcached Java API基础之MemcachedClient
1. 构造函数 public MemcachedClient(InetSocketAddress[] ia) throws IOException; public MemcachedClient(Li ...
- Java多线程初学者指南(10):使用Synchronized关键字同步类方法
要想解决“脏数据”的问题,最简单的方法就是使用synchronized关键字来使run方法同步,代码如下: public synchronized void run() { ... } 从上面的代码可 ...