java实现跳跃表
先贴上一个MIT跳跃表公开课链接:http://open.163.com/movie/2010/12/7/S/M6UTT5U0I_M6V2TTJ7S.html
redis中的有序链表结构就是在跳跃表的基础上实现的。详细的可以参考http://blog.csdn.net/acceptedxukai/article/details/17333673
我的实现方法是,最左侧使用数值的最小值(Double.MIN_VALUE)当作下界。因此,规定存储的值至少大于该值。
下面是跳跃表的图例
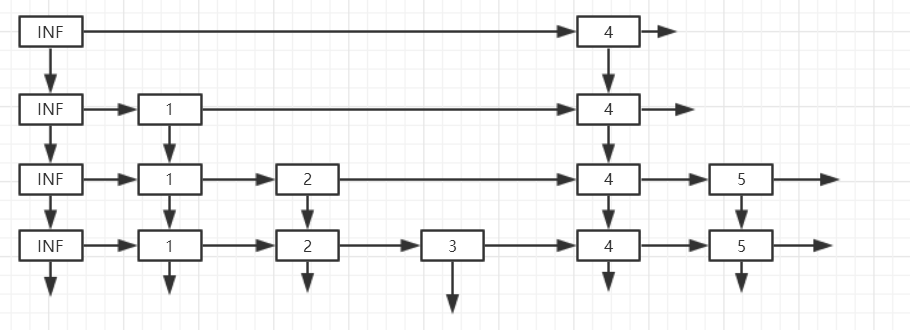
1,实现每个节点类
包含 分值score,val,以及next和down指针
/**
* 跳跃表的节点的构成
*
* @param <E>
*/
private static class SkipNode<E> {
E val;//存储的数据
double score;//跳跃表按照这个分数值进行从小到大排序。
SkipNode<E> next, down;//next指针,指向下一层的指针 SkipNode() {
} SkipNode(E val, double score) {
this.val = val;
this.score = score;
}
}
2,查找,插入,删除方法:即整个类的全部代码
package com.ljd.skiplist; import java.util.ArrayList;
import java.util.List;
import java.util.Random; /**
* Created by author on 2017/10/9.
* 实现跳跃表:能够对递增链表实现logN的查询时间
*/
public class SkipList<T> {
public static void main(String[] args) {
//测试随机数生成的结果对二取模,结果是否是接近于0.5
// Random r = new Random(47);
// int t = 1, a = 1;
// while (a < 10000000) {
// a++;
// if (r.nextInt() % 2 == 0)
// t++;
// }
// System.out.println(t * 1.0 / a); SkipList<String> list = new SkipList<>();
list.put(1.0, "1.0");
System.out.println(list);
list.put(2.0, "2.0");
System.out.println(list);
list.put(3.0, "3.0");
System.out.println(list);
list.put(4.0, "4.0");
System.out.println(list);
list.put(4.0, "5.0");
System.out.println(list);
list.delete(3.0);
list.delete(3.5);
System.out.println(list);
System.out.println("查找4.0" + list.get(4.0));
} /**
* 跳跃表的节点的构成
*
* @param <E>
*/
private static class SkipNode<E> {
E val;//存储的数据
double score;//跳跃表按照这个分数值进行从小到大排序。
SkipNode<E> next, down;//next指针,指向下一层的指针 SkipNode() {
} SkipNode(E val, double score) {
this.val = val;
this.score = score;
}
} private static final int MAX_LEVEL = 1 << 6; //跳跃表数据结构
private SkipNode<T> top;
private int level = 0;
//用于产生随机数的Random对象
private Random random = new Random(); public SkipList() {
//创建默认初始高度的跳跃表
this(4);
} //跳跃表的初始化
public SkipList(int level) {
this.level = level;
int i = level;
SkipNode<T> temp = null;
SkipNode<T> prev = null;
while (i-- != 0) {
temp = new SkipNode<T>(null, Double.MIN_VALUE);
temp.down = prev;
prev = temp;
}
top = temp;//头节点
} /**
* 产生节点的高度。使用抛硬币
*
* @return
*/
private int getRandomLevel() {
int lev = 1;
while (random.nextInt() % 2 == 0)
lev++;
return lev > MAX_LEVEL ? MAX_LEVEL : lev;
} /**
* 查找跳跃表中的一个值
*
* @param score
* @return
*/
public T get(double score) {
SkipNode<T> t = top;
while (t != null) {
if (t.score == score)
return t.val;
if (t.next == null) {
if (t.down != null) {
t = t.down;
continue;
} else
return null;
}
if (t.next.score > score) {
t = t.down;
} else
t = t.next;
}
return null;
} public void put(double score, T val) {
//1,找到需要插入的位置
SkipNode<T> t = top, cur = null;//若cur不为空,表示当前score值的节点存在
List<SkipNode<T>> path = new ArrayList<>();//记录每一层当前节点的前驱节点
while (t != null) {
if (t.score == score) {
cur = t;
break;//表示存在该值的点,表示需要更新该节点
}
if (t.next == null) {
path.add(t);//需要向下查找,先记录该节点
if (t.down != null) {
t = t.down;
continue;
} else {
break;
}
}
if (t.next.score > score) {
path.add(t);//需要向下查找,先记录该节点
if (t.down == null) {
break;
}
t = t.down;
} else
t = t.next;
}
if (cur != null) {
while (cur != null) {
cur.val = val;
cur = cur.down;
}
} else {//当前表中不存在score值的节点,需要从下到上插入
int lev = getRandomLevel();
if (lev > level) {//需要更新top这一列的节点数量,同时需要在path中增加这些新的首节点
SkipNode<T> temp = null;
SkipNode<T> prev = top;//前驱节点现在是top了
while (level++ != lev) {
temp = new SkipNode<T>(null, Double.MIN_VALUE);
path.add(0, temp);//加到path的首部
temp.down = prev;
prev = temp;
}
top = temp;//头节点
level = lev;//level长度增加到新的长度
}
//从后向前遍历path中的每一个节点,在其后面增加一个新的节点
SkipNode<T> downTemp = null, temp = null, prev = null;
// System.out.println("当前深度为"+level+",当前path长度为"+path.size());
for (int i = level - 1; i >= level - lev; i--) {
temp = new SkipNode<T>(val, score);
prev = path.get(i);
temp.next = prev.next;
prev.next = temp;
temp.down = downTemp;
downTemp = temp;
}
}
} /**
* 根据score的值来删除节点。
*
* @param score
*/
public void delete(double score) {
//1,查找到节点列的第一个节点的前驱
SkipNode<T> t = top;
while (t != null) {
if (t.next == null) {
t = t.down;
continue;
}
if (t.next.score == score) {
// 在这里说明找到了该删除的节点
t.next = t.next.next;
t = t.down;
//删除当前节点后,还需要继续查找之后需要删除的节点
continue;
}
if (t.next.score > score)
t = t.down;
else
t = t.next;
}
} @Override
public String toString() {
StringBuilder sb = new StringBuilder();
SkipNode<T> t = top, next = null;
while (t != null) {
next = t;
while (next != null) {
sb.append(next.score + " ");
next = next.next;
}
sb.append("\n");
t = t.down;
}
return sb.toString();
}
}
对于插入的时候,在寻找插入位置的同时,我使用了一个ArrayList存储查找方向向下时的节点。这样在构造节点的时候,只需要直接从这个list中拿prev节点就行了。
下面这种方式的实现,比上面的少消耗了很多存val的空间,这个后续看能否实现。
java实现跳跃表的更多相关文章
- 跳跃表Skip List【附java实现】
skip list的原理 Java中的LinkedList是一种常见的链表结构,这种结构支持O(1)的随机插入及随机删除, 但它的查找复杂度比较糟糕,为O(n). 假如我们有一个有序链表如下,如果我们 ...
- 基于跳跃表的 ConcurrentSkipListMap 内部实现(Java 8)
我们知道 HashMap 是一种键值对形式的数据存储容器,但是它有一个缺点是,元素内部无序.由于它内部根据键的 hash 值取模表容量来得到元素的存储位置,所以整体上说 HashMap 是无序的一种容 ...
- 跳跃表-原理及Java实现
跳跃表-原理及Java实现 引言: 上周现场面试阿里巴巴研发工程师终面,被问到如何让链表的元素查询接近线性时间.笔者苦思良久,缴械投降.面试官告知回去可以看一下跳跃表,遂出此文. 跳跃表的引入 我们知 ...
- 【Redis】跳跃表原理分析与基本代码实现(java)
最近开始看Redis设计原理,碰到一个从未遇见的数据结构:跳跃表(skiplist).于是花时间学习了跳表的原理,并用java对其实现. 主要参考以下两本书: <Redis设计与实现>跳表 ...
- 跳跃表Skip List的原理和实现
>>二分查找和AVL树查找 二分查找要求元素可以随机访问,所以决定了需要把元素存储在连续内存.这样查找确实很快,但是插入和删除元素的时候,为了保证元素的有序性,就需要大量的移动元素了.如果 ...
- 数据结构与算法(c++)——跳跃表(skip list)
今天要介绍一个这样的数据结构: 单向链接 有序保存 支持添加.删除和检索操作 链表的元素查询接近线性时间 ——跳跃表 Skip List 一.普通链表 对于普通链接来说,越靠前的节点检索的时间花费越低 ...
- 讲讲跳跃表(Skip Lists)
跳跃表(Skip Lists)是一种有序的数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的.在大部分情况下,跳跃表的效率可以和平衡树相媲美,并且在实现上比平衡树要更为 ...
- 跳跃表Skip List的原理
1.二分查找和AVL树查找 二分查找要求元素可以随机访问,所以决定了需要把元素存储在连续内存.这样查找确实很快,但是插入和删除元素的时候,为了保证元素的有序性,就需要大量的移动元素了.如果需要的是一个 ...
- JAVA SkipList 跳表 的原理和使用例子
跳跃表是一种随机化数据结构,基于并联的链表,其效率可比拟于二叉查找树(对于大多数操作需要O(log n)平均时间),并且对并发算法友好. 关于跳跃表的具体介绍可以参考MIT的公开课:跳跃表 跳跃表的应 ...
随机推荐
- A Magic Lamp -- hdu -- 3183
http://acm.hdu.edu.cn/showproblem.php?pid=3183 A Magic Lamp Time Limit: 2000/1000 MS (Java/Others) ...
- web-day5
第5章WEB05- BootStrap篇 今日任务 使用JQuery完成表单校验 使用BootStrap制作一个响应式页面 使用BootStrap制作网站首页 教学导航 教学目标 掌握什么是响应式及响 ...
- 微信小程序-button组件
主要属性: 注:button-hover 默认为{background-color: rgba(0, 0, 0, 0.1); opacity: 0.7;} 效果图: ml: <!--默认的but ...
- tarjan算法--求解无向图的割点和桥
1.桥:是存在于无向图中的这样的一条边,如果去掉这一条边,那么整张无向图会分为两部分,这样的一条边称为桥 也就是说 无向连通图中,如果删除某边后,图变成不连通,则称该边为桥 2.割点:无向连通图中,如 ...
- 类变量的初始化时机(摘录自java突破程序员基本功德16课)
先看书本的一个例子,代码如下: public class Price { final static Price INSTANCE=new Price(2.8); static double initP ...
- WPF点滴(3) 行为-Behavior
为了定制个性化的用户界面,我们通常会借助于WPF强大的样式(style),修改控件属性,重写控件模板(template),样式帮助我们构建一致的个性化控件.通过样式可以调整界面的显示效果,这只是界面构 ...
- Angular build Error:In this configuration Angular requires Zone.js
Angular cli 运行 build后打开生成的index.html报错:In this configuration Angular requires Zone.js 生成代码如下: ng bui ...
- 关于C++中字符串与数字的互相转换
方法搬自博客: Qt数据类型转换 侵删 1. 把QString转换为double类型 //法一: QString str="123.45"; double val=str.to ...
- AJPFX:外汇的爆仓和追加保证金
在外汇交易中,当可用保证金变成0时,账户即会爆仓.而为了防止爆仓,您可以在可用保证金不足时追加保证金以防止爆仓. 例如,您在AJPFX的账户是100倍的杠杆,一手欧美货币对合约为10万美金(1 LOT ...
- git 下载指定tag版本的源码
git clone --branch x.x.x https://xxx.xxx.com/xxx/xxx.git