回归算法比较(线性回归,Ridge回归,Lasso回归)
代码实现:
# -*- coding: utf-8 -*-
"""
Created on Mon Jul 16 09:08:09 2018 @author: zhen
""" from sklearn.linear_model import LinearRegression, Ridge, Lasso
import mglearn
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
# 线性回归
x, y = mglearn.datasets.load_extended_boston()
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0) linear_reg = LinearRegression()
lr = linear_reg.fit(x_train, y_train) print("lr.coef_:{}".format(lr.coef_)) # 斜率
print("lr.intercept_:{}".format(lr.intercept_)) # 截距 print("="*25+"线性回归"+"="*25)
print("Training set score:{:.2f}".format(lr.score(x_train, y_train)))
print("Rest set score:{:.2f}".format(lr.score(x_test, y_test))) """
总结:
训练集和测试集上的分数非常接近,这说明可能存在欠耦合。
训练集和测试集之间的显著性能差异是过拟合的明显标志。解决方式是使用岭回归!
"""
print("="*25+"岭回归(默认值1.0)"+"="*25)
# 岭回归
ridge = Ridge().fit(x_train, y_train) print("Training set score:{:.2f}".format(ridge.score(x_train, y_train)))
print("Test set score:{:.2f}".format(ridge.score(x_test, y_test))) print("="*25+"岭回归(alpha=10)"+"="*25)
# 岭回归
ridge_10 = Ridge(alpha=10).fit(x_train, y_train) print("Training set score:{:.2f}".format(ridge_10.score(x_train, y_train)))
print("Test set score:{:.2f}".format(ridge_10.score(x_test, y_test))) print("="*25+"岭回归(alpha=0.1)"+"="*25)
# 岭回归
ridge_01 = Ridge(alpha=0.1).fit(x_train, y_train) print("Training set score:{:.2f}".format(ridge_01.score(x_train, y_train)))
print("Test set score:{:.2f}".format(ridge_01.score(x_test, y_test))) # 可视化
fig = plt.figure(10)
plt.subplots_adjust(wspace =0, hspace =0.6)#调整子图间距
ax1 = plt.subplot(2, 1, 1) ax2 = plt.subplot(2, 1, 2) ax1.plot(ridge_01.coef_, 'v', label="Ridge alpha=0.1")
ax1.plot(ridge.coef_, 's', label="Ridge alpha=1")
ax1.plot(ridge_10.coef_, '^', label="Ridge alpha=10") ax1.plot(lr.coef_, 'o', label="LinearRegression") ax1.set_ylabel("Cofficient magnitude")
ax1.set_ylim(-25,25)
ax1.hlines(0, 0, len(lr.coef_))
ax1.legend(ncol=2, loc=(0.1, 1.05)) print("="*25+"Lasso回归(默认配置)"+"="*25)
lasso = Lasso().fit(x_train, y_train) print("Training set score:{:.2f}".format(lasso.score(x_train, y_train)))
print("Test set score:{:.2f}".format(lasso.score(x_test, y_test)))
print("Number of features used:{}".format(np.sum(lasso.coef_ != 0))) print("="*25+"Lasso回归(aplpha=0.01)"+"="*25)
lasso_001 = Lasso(alpha=0.01, max_iter=1000).fit(x_train, y_train) print("Training set score:{:.2f}".format(lasso_001.score(x_train, y_train)))
print("Test set score:{:.2f}".format(lasso_001.score(x_test, y_test)))
print("Number of features used:{}".format(np.sum(lasso_001.coef_ != 0))) print("="*15+"Lasso回归(aplpha=0.0001)太小可能会过拟合"+"="*15)
lasso_00001 = Lasso(alpha=0.0001, max_iter=1000).fit(x_train, y_train) print("Training set score:{:.2f}".format(lasso_00001.score(x_train, y_train)))
print("Test set score:{:.2f}".format(lasso_00001.score(x_test, y_test)))
print("Number of features used:{}".format(np.sum(lasso_00001.coef_ != 0))) # 可视化
ax2.plot(ridge_01.coef_, 'o', label="Ridge alpha=0.1")
ax2.plot(lasso.coef_, 's', label="lasso alpha=1")
ax2.plot(lasso_001.coef_, '^', label="lasso alpha=0.001")
ax2.plot(lasso_00001.coef_, 'v', label="lasso alpha=0.00001") ax2.set_ylabel("Cofficient magnitude")
ax2.set_xlabel("Coefficient index")
ax2.set_ylim(-25,25)
ax2.legend(ncol=2, loc=(0.1, 1))
结果:


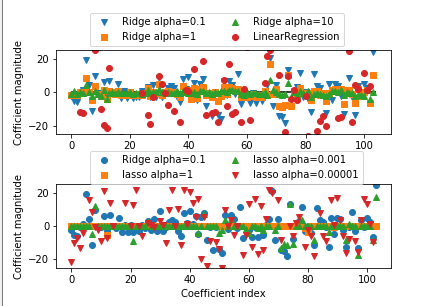
总结:各回归算法在相同的测试数据中表现差距很多,且算法内的配置参数调整对自身算法的效果影响也是巨大的,
因此合理挑选合适的算法和配置合适的配置参数是使用算法的关键!
回归算法比较(线性回归,Ridge回归,Lasso回归)的更多相关文章
- 线性回归大结局(岭(Ridge)、 Lasso回归原理、公式推导),你想要的这里都有
本文已参与「新人创作礼」活动,一起开启掘金创作之路. 线性模型简介 所谓线性模型就是通过数据的线性组合来拟合一个数据,比如对于一个数据 \(X\) \[X = (x_1, x_2, x_3, ..., ...
- Lasso回归算法: 坐标轴下降法与最小角回归法小结
前面的文章对线性回归做了一个小结,文章在这: 线性回归原理小结.里面对线程回归的正则化也做了一个初步的介绍.提到了线程回归的L2正则化-Ridge回归,以及线程回归的L1正则化-Lasso回归.但是对 ...
- 多元线性回归模型的特征压缩:岭回归和Lasso回归
多元线性回归模型中,如果所有特征一起上,容易造成过拟合使测试数据误差方差过大:因此减少不必要的特征,简化模型是减小方差的一个重要步骤.除了直接对特征筛选,来也可以进行特征压缩,减少某些不重要的特征系数 ...
- SparkMLlib学习分类算法之逻辑回归算法
SparkMLlib学习分类算法之逻辑回归算法 (一),逻辑回归算法的概念(参考网址:http://blog.csdn.net/sinat_33761963/article/details/51693 ...
- SparkMLlib分类算法之逻辑回归算法
SparkMLlib分类算法之逻辑回归算法 (一),逻辑回归算法的概念(参考网址:http://blog.csdn.net/sinat_33761963/article/details/5169383 ...
- LASSO回归与L1正则化 西瓜书
LASSO回归与L1正则化 西瓜书 2018年04月23日 19:29:57 BIT_666 阅读数 2968更多 分类专栏: 机器学习 机器学习数学原理 西瓜书 版权声明:本文为博主原创文章,遵 ...
- 线性回归——lasso回归和岭回归(ridge regression)
目录 线性回归--最小二乘 Lasso回归和岭回归 为什么 lasso 更容易使部分权重变为 0 而 ridge 不行? References 线性回归很简单,用线性函数拟合数据,用 mean squ ...
- Spark MLlib回归算法------线性回归、逻辑回归、SVM和ALS
Spark MLlib回归算法------线性回归.逻辑回归.SVM和ALS 1.线性回归: (1)模型的建立: 回归正则化方法(Lasso,Ridge和ElasticNet)在高维和数据集变量之间多 ...
- 【机器学习】正则化的线性回归 —— 岭回归与Lasso回归
注:正则化是用来防止过拟合的方法.在最开始学习机器学习的课程时,只是觉得这个方法就像某种魔法一样非常神奇的改变了模型的参数.但是一直也无法对其基本原理有一个透彻.直观的理解.直到最近再次接触到这个概念 ...
随机推荐
- 设计模式 | 外观模式/门面模式(facade)
定义: 为子系统中的一组接口提供一个一致的界面,此模式定义了一个高层接口,这个接口使得这一子系统更加容易使用. 结构:(书中图,侵删) 一个简洁易用的外观类 一个复杂的子系统 实例: 书中提到了理 ...
- 基于geoserver的REST服务完成mysql数据源动态发布
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1. 背景 在之前的<简析GeoServer服务的内部文件组织以及 ...
- windows之自动化在虚拟机部署操作系统并自带python环境
(1)使用详情: **************************** * 操作说明 * **************************** 1.修改Config文件夹中的Se ...
- linux操作系统的前世今生
linux操作系统是李纳斯-拖瓦兹于1970年正式发布第一个真正的内核版本,他也称Linux之父,Linux是由Unix发展而来,发展到现在Linux操作系统凭借着良好的性能和稳定性已被linux已被 ...
- LOJ #6060. 「2017 山东一轮集训 Day1 / SDWC2018 Day1」Set
有趣的思博套路题,想到了基本上加上个对线性基的理解就可以过了 首先考虑到这个把数分成两半的分别异或的过程不会改变某一位上\(1\)的总个数 因此我们求出所有数的\(\operatorname{xor} ...
- Re:Unity游戏开发有哪些让你拍案叫绝的技巧?
这是我在知乎一个问题: <Unity游戏开发有哪些让你拍案叫绝的技巧?> 下面的回答,觉得蛮有趣的,贴在这里和博客的朋友们分享下. ----- 分享一个比较好玩的内容吧. 大家都知道Uni ...
- 技能提升丨Seacms 8.7版本SQL注入分析
有些小伙伴刚刚接触SQL编程,对SQL注入表示不太了解.其实在Web攻防中,SQL注入就是一个技能繁杂项,为了帮助大家能更好的理解和掌握,今天小编将要跟大家分享一下关于Seacms 8.7版本SQL注 ...
- chrome谷歌浏览器开发者工具-网络带宽控制
有时候我们想在本地测试一下图片预加载loading的加载情况,如下图: 可无奈一般网络带宽都比较好,基本上看不到效果,图片一下子就加载出来了, 可能这个时候有些小伙伴想到的办法是用定时器延迟加载 其实 ...
- 安装虚拟机,磁盘选择厚置备延迟置零与厚置备置零和Thin Provision有什么区别
(1)厚置备延迟置零: (2)厚置备置零: (3)Thin Provision(精简置备). 这三种类型的磁盘,每一种类型的磁盘创建的方式和磁盘性能都有所不同,具体解释如下.1.厚置备延迟置零举例,本 ...
- 批量执行工具PSSH详解
批量执行工具PSSH详解 pssh是一个python编写可以在多台服务器上执行命令的工具,同时支持拷贝文件,是同类工具中很出色的,使用必须在各个服务器上配置好密钥认证访问. 安装pssh包 yum 安 ...