kudu的写数据流程

写入操作是指需进行插入、更新或删除操作的一组行。需要注意的事项是Kudu强制执行主关键字的唯一性,主关键字是可以更改行的唯一标识符。为了强制执行此约束条件,Kudu必须以不同的方式处理插入和更新操作,并且这会影响tablet服务器如何处理写入
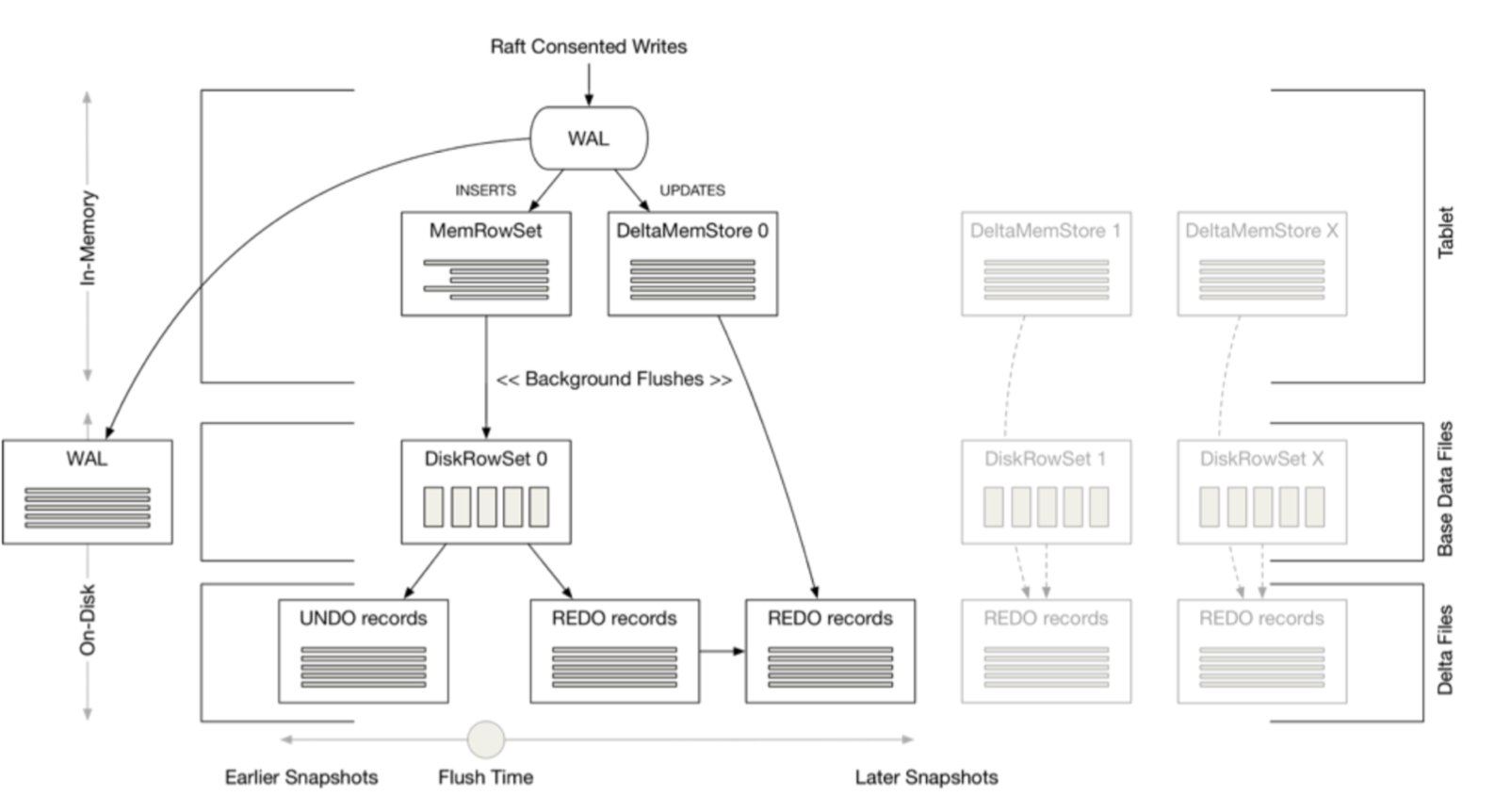
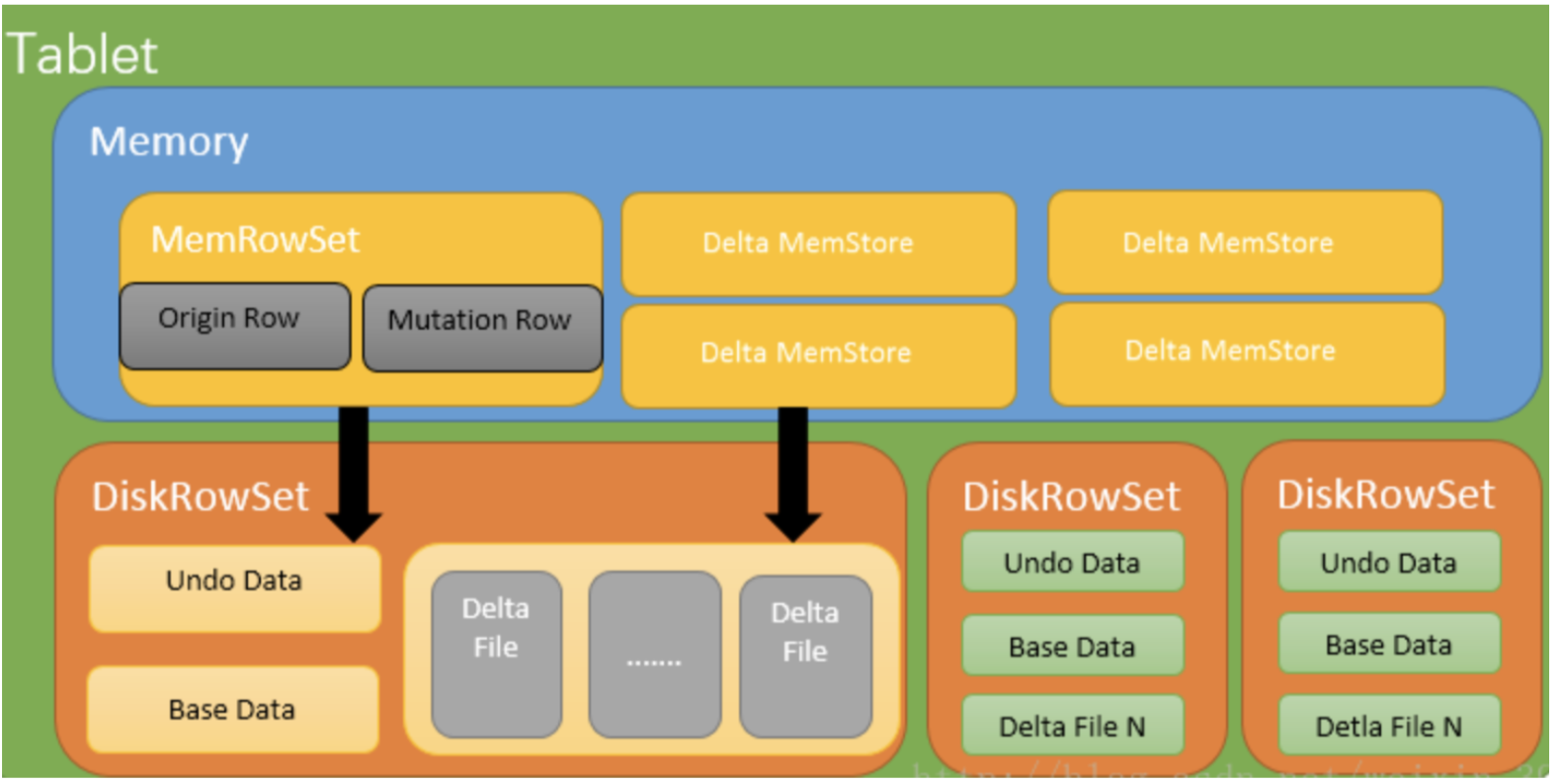
Kudu中的每个tablet包含预写式日志(WAL)和多个行集合(RowSet),它们是保存在存储器和磁盘上(被刷新时)的不相交的行集合。
写入操作先被提交到tablet的预写式日志(WAL),并根据Raft 一致性算法取得追随节点的同意,然后才会被添加到其中一个tablet的内存中;
插入会被添加到tablet的MemRowSet中。为了在MemRowSet中支持多版本并发控制(MVCC),对最近插入的行(即尚未刷新到磁盘的新的行)的更新和删除操作将被追加到MemRowSet中的原始行之后以生成重做(REDO)记录的列表。(读取者需要应用相关的重做(REDO)记录,根据扫描程序给定的时间戳构建行的正确快照。)
当MemRowSet填满时,则被刷新到磁盘并成为一个DiskRowSet。为了支持磁盘中存储数据的多版本并发控制(MVCC)功能,DiskRowSets被分为两种不同的文件类型:
MemRowSet中行的最新版本(即应用了其所有重做(REDO)记录的原始插入)被写入到基础数据文件。这是一种柱状文件格式(非常像Parquet),用于快速、高效的读取访问,其赋予了Kudu支持分析访问模式的能力。 MemRowSet中存在的行的先前版本(即重做(REDO)记录的倒序)作为一组撤销(UNDO)记录写入增量文件。时间行程读取可以应用相关的撤销(UNDO)记录,从早期的时间点构建行的正确快照。
更新已被编码和压缩的柱状格式化数据文件需要重写整个文件,因此基础数据文件一旦被刷新则被认为是不可变的。
此外,行关键字唯一性约束意味着基本记录的更新和删除不能被添加到tablet的MemRowSet中,而是被添加到名为DeltaMemStore的单独的内存存储器中。
像MemRowSet一样,所有的变化都将被添加到DeltaMemStore中作为一组重做(REDO)记录;
当DeltaMemStore填满时,重做(REDO)记录将被刷新到磁盘上存储的增量文件中。
每个DiskRowSet都存在一个单独的DeltaMemStore。如需构建行的正确快照,读取者必须在应用相关撤销(UNDO)或重做(REDO)记录之前首先找到行的基本记录
综上所述:
Kudu插入一条新数据
1、客户端连接TMaster获取表的相关信息,包括分区信息,表中所有tablet的信息;
2、客户端找到负责处理读写请求的tablet所负责维护的TServer。Kudu接受客户端的请求,检查请求是否符合要求(表结构);
3、Kudu在Tablet中的所有rowset(memrowset,diskrowset)中进行查找,看是否存在与待插入数据相同主键的数据,如果存在就返回错误,否则继续;
4、写入操作先被提交到tablet的预写日志(WAL),并根据Raft一致性算法取得追随节点的同意,然后才会被添加到其中一个tablet的内存中,插入会被添加到tablet的MemRowSet中。为了在MemRowSet中支持多版本并发控制(MVCC),对最近插入的行(即尚未刷新到磁盘的新的行)的更新和删除操作将被追加到MemRowSet中的原始行之后以生成REDO记录的列表。
5、Kudu在MemRowset中写入一行新数据,在MemRowset(1G或者是120s)数据达到一定大小时,MemRowset将数据落盘,并生成一个diskrowset用于持久化数据,还生成一个memrowset继续接收新数据的请求
kudu的写数据流程的更多相关文章
- day4-hdfs的核心工作原理\写数据流程 \读数据流程
namenode元数据管理要点 1.什么是元数据? hdfs的目录结构及每一个文件的块信息(块的id,块的副本数量,块的存放位置<datanode>) 2.元数据由谁负责管理? namen ...
- Solr 写数据流程
Solr 写数据流程: 1.源字符串首先经过分词器处理,包括:拆分词以及去除stopword. 2.然后经过语言处理,包括大小写转换以及单词转换. 3.将源数据中需要的信息加入到Document中的各 ...
- HDFS 读/写数据流程
1. HDFS 写数据流程 客户端通过 Distributed FileSystem 模块向 NameNode 请求上传文件, NameNode 检查目标文件是否已存在,父目录是否存在: NameNo ...
- HA工作机制及namenode向QJM写数据流程
HA工作机制 (配置HA高可用传送门:https://www.cnblogs.com/zhqin/p/11904317.html) HA:高可用(7*24小时不中断服务) 主要的HA是针对集群的mas ...
- kudu的读取数据流程
当客户端从Kudu的表中读取数据时,必须首先建立需要连接的系列tablet服务器. 通过执行tablet发现过程(如上所述)来确定包含要读取的主关键字范围的tablet的位置(读取不必在领导者tabl ...
- HDFS数据流——写数据流程
剖析HDFS文件写入 假设文件ss.avi共200m,其写入HDFS指定路径/user/atguigu/ss.avi流程如下: 1)客户端向namenode请求上传文件到指定路径,namenode通过 ...
- HDFS写数据和读数据流程
HDFS数据存储 HDFS client上传数据到HDFS时,首先,在本地缓存数据,当数据达到一个block大小时.请求NameNode分配一个block. NameNode会把block所在的Dat ...
- Hadoop(8)-HDFS的读写数据流程以及机架感知
1. HDFS的写数据流程 1.客户端通过fs模块向NameNode申请文件上传,NameNode检查请求是否合法,如用户权限,目标文件是否已存在,父目录是否存在等等 2.NameNode返回是否可以 ...
- HDFS读写数据流程
HDFS的组成 1.NameNode:存储文件的元数据,如文件名,文件目录结构,文件属性(创建时间,文件权限,文件大小) 以及每个文件的块列表和块所在的DataNode等.类似于一本书的目录功能. 2 ...
随机推荐
- linux 新机器的配置(git + nodejs+ mongodb)
安装nodejs: wget https://nodejs.org/dist/v6.9.5/node-v6.9.5-linux-x64.tar.xz tar xvf node-v6.9.5-linux ...
- nginx中Geoip_module模块的使用
nginx中Geoip_module模块的使用 .安装模块,nginx也是通过yum安装 yum install nginx-module-geoip -y # 可以看到模块的链接库文件 [root@ ...
- 前端 ----jQuery操作表单
05-使用jQuery操作input的value值 表单控件是我们的重中之重,因为一旦牵扯到数据交互,离不开form表单的使用,比如用户的注册登录功能等 那么通过上节知识点我们了解到,我们在使用j ...
- class, extends和super es6语法
摘自https://www.cnblogs.com/queende7/p/8668497.html,谢谢博主的分享!
- 13)django-ORM(连表一对多,外键创建,创建数据,3种查询)
一对多需要使用外键 一:外键创建ForeignKey b=models.ForeignKey(to="Business",to_field=("id"))#dj ...
- Float与二进制之间的转化(Java实现)
在线转化:http://www.binaryconvert.com import java.text.DecimalFormat; public class SinglePrecision { //浮 ...
- 图片文字css小知识点
行内元素,图片和文字中间有缝隙,需要给父元素设置font-size:0: 图片和文字不对齐,给图片设置vertical-align:top 文字行高有缝隙 设置vertical-align:top
- 第九单元 利用vi编辑器创建和编辑正文文件
vi编辑器简介 什么是vi vi编辑器的操作模式 vi编辑器的3种基本模式 在vi编辑器中光标的移动 移动光标位置的键与光标移动间的关系 进入插入模式 从命令行模式进入插入模式的命令 在命令行模式下 ...
- ubuntu 安装Mysql8.0
1. 去官网下载安装包 下载链接:点击打开链接 https://dev.mysql.com/downloads/mysql/ 如果你的系统是32位选择第一个,64位选择第二个 也可以用wget 下载 ...
- Practical Web Penettation Testing (the first one Mutillidae 大黄蜂 之二)
1.how to use dpkg cmmand first it can be used for list all software , dpkg -l (由于kali linux 没有启动所以 ...