seaborn分类数据可视化
转载:https://cloud.tencent.com/developer/article/1178368
seaborn针对分类型的数据有专门的可视化函数,这些函数可大致分为三种:
- 分类数据散点图:swarmplot(), stripplot()
- 分类数据的分布图: boxplot(), violinplot()
- 分类数据的统计估算图 : barplot(), pointplot()
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns sns.set(style="whitegrid", color_codes=True)
np.random.seed(sum(map(ord, "categorical"))) #下载三个数据集
titanic = sns.load_dataset("titanic")
tips = sns.load_dataset("tips") #panda DataFrame结构
iris = sns.load_dataset("iris")
#分类数据散点图:stripplot();x是分类特征day,y是目标变量,连续值
sns.stripplot(x="day",y="total_bill",data=tips)
横坐标是分类数据,一些数据点上会互相重叠,不便于观察,一个简单的解决办法是加入 jitter 参数,调整横坐标位置:
sns.stripplot(x="day", y="total_bill", data=tips, jitter=True)
#分类数据散点图:swarmplot(),这个函数的好处就是所有的点都不会重叠,这样可以很清晰的观察到数据的分布
sns.swarmplot(x="day", y="total_bill", data=tips)

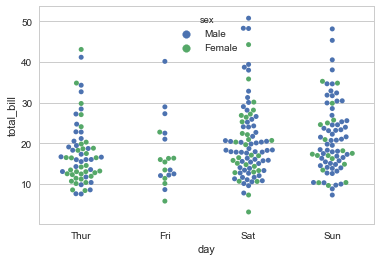
通过 hue 参数加入另一个嵌套的分类变量,而且嵌套的分类变量可以以不同的颜色区别
sns.swarmplot(x="day", y="total_bill", hue="sex", data=tips)
seaborn 会尝试推断出分类变量的顺序。数据是 pandas 的分类数据类型,那么就是使用默认的分类数据顺序,如果是其他的数据类型,字符串类型的类别将按照它们在DataFrame中显示的顺序进行绘制,但是数组类别将被排序:
sns.swarmplot(x="size", y="total_bill", data=tips)

将分类变量放在垂直轴上是非常有用的(当类别名称相对较长或有很多类别),可以使用 orient 关键字强制定向,但通常可以互换x和y的变量的数据类型来完成:
sns.swarmplot(x="total_bill", y="day", hue="time", data=tips)

分类数据分布图:
箱型图:箱型图可以直观观察到数据的四分位分布(1/4分位,中位数,3/4分位,以及四分位距),这种可视化对于在机器学习的预处理阶段(尤其是发现数据异常离散值)十分有效。
sns.boxplot(x="day", y="total_bill", hue="time", data=tips)

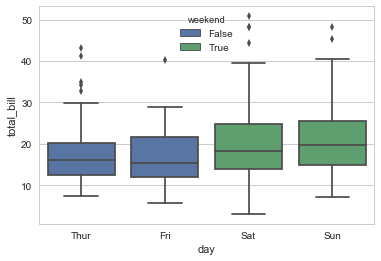
使用 hue 参数的假设是这个变量嵌套在x或者y轴内。所以默认的情况下,hue 变量的不同类型值会保持偏置状态(两类或几类数据共同在x轴数据类型的一个类中),就像上面那个图所示。但是如果 hue 所使用的变量不是嵌套的,那么你可以使用 dodge 参数来禁止这个默认的偏置状态。
tips["weekend"] = tips["day"].isin(["Sat", "Sun"])
sns.boxplot(x="day", y="total_bill", hue="weekend", data=tips, dodge=False)
提琴图:它结合了箱体图和分布教程中描述的核心密度估计过程
sns.violinplot(x="total_bill", y="day", hue="time", data=tips)

这种方法使用核密度估计来更好地描述值的分布。此外,小提琴内还显示了箱体四分位数和四分位距。由于小提琴使用KDE,还有一些其他可以调整的参数,相对于简单的boxplot增加了一些复杂性:
sns.violinplot(x="total_bill", y="day", hue="time", data=tips, bw=.1, scale="count", scale_hue=False)

当 hue 的嵌套类型只有两类的时候,也可以使用 split 参数将小提琴分割:
sns.violinplot(x="day", y="total_bill", hue="sex", data=tips, split=True)

可以在提琴图内使用 inner 参数以横线的形式来展示每个观察点的分布,来代替箱型的整体分布:
sns.violinplot(x="day", y="total_bill", hue="sex", data=tips, split=True, inner="stick", palette="Set3")
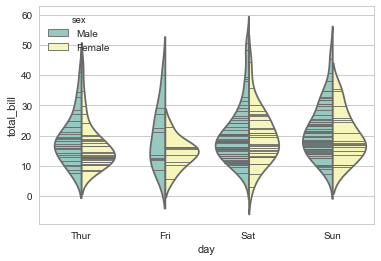
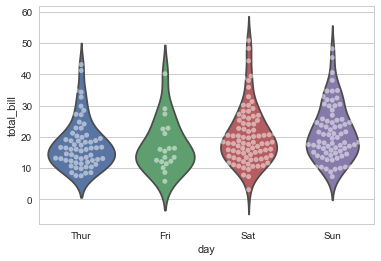
可以将 swarmplot(),violinplot(),或 boxplot() 混合使用,这样可以结合多种绘图的特点展示更完美的效果:
sns.violinplot(x="day", y="total_bill", data=tips, inner=None)
sns.swarmplot(x="day", y="total_bill", data=tips, color="w", alpha=.5)
分类数据统计估计图:展示每一类的集中趋势
Seaborn中 barplot() 函数会在整个数据集上显示估计,默认情况下使用均值进行估计。 当在每个类别中有多个类别时(使用了 hue),它可以使用引导来计算估计的置信区间,并使用误差条来表示置信区间:
sns.barplot(x="sex", y="survived", hue="class", data=titanic)

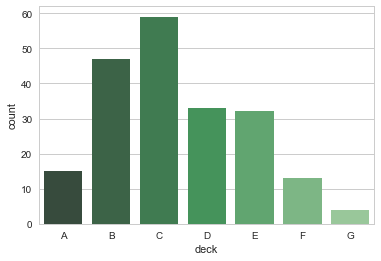
条形图的特殊情况是当想要显示每个类别的数量,而不是计算统计量,使用 countplot() 函数:
sns.countplot(x="deck", data=titanic, palette="Greens_d")
更多内容见:
seaborn分类数据可视化的更多相关文章
- seaborn分类数据可视化:散点图|箱型图|小提琴图|lv图|柱状图|折线图
一.散点图stripplot( ) 与swarmplot() 1.分类散点图stripplot( ) 用法stripplot(x=None, y=None, hue=None, data=None, ...
- Python图表数据可视化Seaborn:2. 分类数据可视化-分类散点图|分布图(箱型图|小提琴图|LV图表)|统计图(柱状图|折线图)
1. 分类数据可视化 - 分类散点图 stripplot( ) / swarmplot( ) sns.stripplot(x="day",y="total_bill&qu ...
- seaborn教程4——分类数据可视化
https://segmentfault.com/a/1190000015310299 Seaborn学习大纲 seaborn的学习内容主要包含以下几个部分: 风格管理 绘图风格设置 颜色风格设置 绘 ...
- seaborn线性关系数据可视化:时间线图|热图|结构化图表可视化
一.线性关系数据可视化lmplot( ) 表示对所统计的数据做散点图,并拟合一个一元线性回归关系. lmplot(x, y, data, hue=None, col=None, row=None, p ...
- seaborn分布数据可视化:直方图|密度图|散点图
系统自带的数据表格(存放在github上https://github.com/mwaskom/seaborn-data),使用时通过sns.load_dataset('表名称')即可,结果为一个Dat ...
- 用seaborn对数据可视化
以下用sns作为seaborn的别名 1.seaborn整体布局设置 sns.set_syle()函数设置图的风格,传入的参数可以是"darkgrid", "whiteg ...
- Python Seaborn综合指南,成为数据可视化专家
概述 Seaborn是Python流行的数据可视化库 Seaborn结合了美学和技术,这是数据科学项目中的两个关键要素 了解其Seaborn作原理以及使用它生成的不同的图表 介绍 一个精心设计的可视化 ...
- Seaborn数据可视化入门
在本节学习中,我们使用Seaborn作为数据可视化的入门工具 Seaborn的官方网址如下:http://seaborn.pydata.org 一:definition Seaborn is a Py ...
- 5 种使用 Python 代码轻松实现数据可视化的方法
数据可视化是数据科学家工作中的重要组成部分.在项目的早期阶段,你通常会进行探索性数据分析(Exploratory Data Analysis,EDA)以获取对数据的一些理解.创建可视化方法确实有助于使 ...
随机推荐
- PostgreSQL11.2 configure卡住 checking for DocBook XML V4.2
在PG11.2的数据库编译过程中,卡在了“checking for DocBook XML V4.2”,不动,需要安装docbook才可以. 需要安装: yum install docbook-dtd ...
- C高级第一次PTA作业
作业要求一 附加题目 写程序证明P++等价于(p)++还是等价于*(p++)? 1.设计思路: (1).题目算法描述 第一步:定义变量p并赋初值 第二步:分三次计算每次分别输出 p++,(p)++,* ...
- Linux基础和网络管理上机试题 - imsoft.cnblogs
一.(使用at命令实现任务的的自动化,要求用一条条的指令完成) 找出系统中任何以txt为后缀名的文档,并且进行打印.打印结束后给用户foxy发出邮件通知取件.指定时间为十二月二十五日凌晨两点 ...
- 使用git错误日志
错误日志 pull错误 将远程仓库内容pull下来的过程中,碰到了拒绝合并两个不相关的历史,所以无法下载,同样的也无法push 但是我的东西明明是从组织里克隆下来的,只是做了一些修改 后来我我尝试不替 ...
- android 自动拨打电话 挂断电话代码
页面布局文件代码 ( res下面的layout下面的activity_main.xml代码 ) <RelativeLayout xmlns:android="http://sche ...
- Transformer-view java实体 转换视图 Lists.transform
自: https://blog.csdn.net/mnmlist/article/details/53870520 meta_ws 连接: https://github.com/kse-music/d ...
- Comet OJ - Contest #2简要题解
Comet OJ - Contest #2简要题解 前言: 我没有小裙子,我太菜了. A 因自过去而至的残响起舞 https://www.cometoj.com/contest/37/problem/ ...
- python 取整
1.向下取整 向下取整直接用内建的 int() 函数即可: >>> a = 3.75 >>> int(a) 3 2.四舍五入 对数字进行四舍五入用 round() ...
- Tomcat配置JNDI数据源的三种方式-转-http://blog.51cto.com/xficc/1564691
第一种,单个应用独享数据源 就一步,找到Tomcat的server.xml找到工程的Context节点,添加一个私有数据源 Xml代码 <Context docBase="WebA ...
- 转-spring boot web相关配置
spring boot web相关配置 80436 spring boot集成了servlet容器,当我们在pom文件中增加spring-boot-starter-web的maven依赖时,不做任何w ...