吴裕雄 python 数据处理(2)
import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(data.head())
a = data.stack()
print(a)
b = a.unstack()
print(b)

import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(data.head())
df = data.set_index("日期")
print(df.head())

import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
print(a.info())

import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
print(data.head())

import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = data["价格"].groupby([data["出发地"],data["目的地"]]).mean()
print(a)

import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_route_cnt.csv")
print(data.head())

import pandas as pd
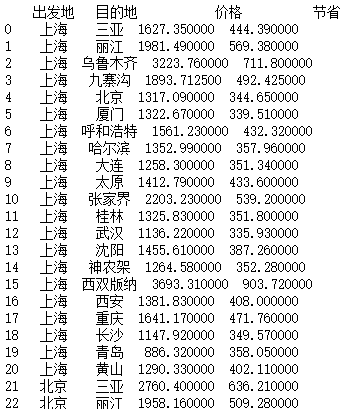
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = data.groupby([data["出发地"],data["目的地"]],as_index=False).mean()
print(a)
import pandas as pd
data = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_route_cnt.csv")
print(data.head())
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
print(data_1.head())
a = data_1.groupby([data_1["出发地"],data_1["目的地"]],as_index=False).mean()
print(a.head())
b = pd.merge(a,data)
print(b.head())

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = pd.pivot_table(data_1,values=["价格"],index=["出发地"],columns=["目的地"])
print(a.head())

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = pd.pivot_table(data_1[data_1["出发地"]=="杭州"],values=["价格"],index=["出发地","目的地"],columns=["去程方式"])
print(a)

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(data_1.head())
print(data_1.isnull().head())
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
print(a.isnull())

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.dropna(axis=0)
print(b)

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.dropna(axis=1)
print(b)

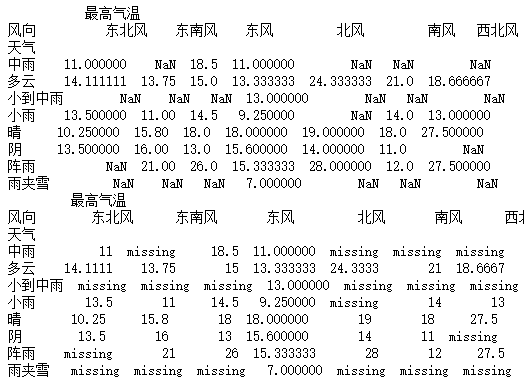
import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.fillna("missing")
print(b)
import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.fillna(method="pad")
print(b)

import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.fillna(method="bfill",limit=1)
print(b)

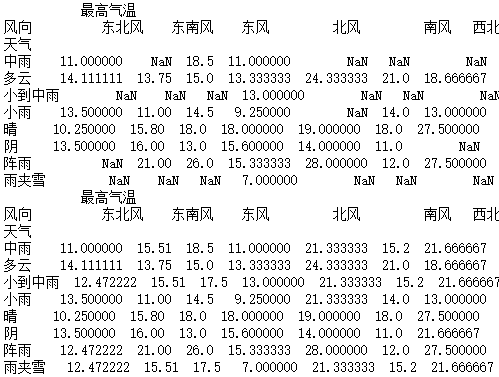
import pandas as pd
data_1 = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
a = pd.pivot_table(data_1,values=["最高气温"],index=["天气"],columns=["风向"])
print(a)
b = a.fillna(a.mean())
print(b)
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(np.shape(df))
print(df.head())
fig,ax = plt.subplots(1,1,figsize=(8,5))
ax.hist(df["最低气温"],bins=20)
plt.show()
d = df["最低气温"]
zscore = (d-d.mean())/d.std()
df["isOutlier"]=zscore.abs()>3
print(df.head())
a = df["isOutlier"].value_counts()
print(a)


%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\sale_data.csv")
print(np.shape(df))
print(df.head())
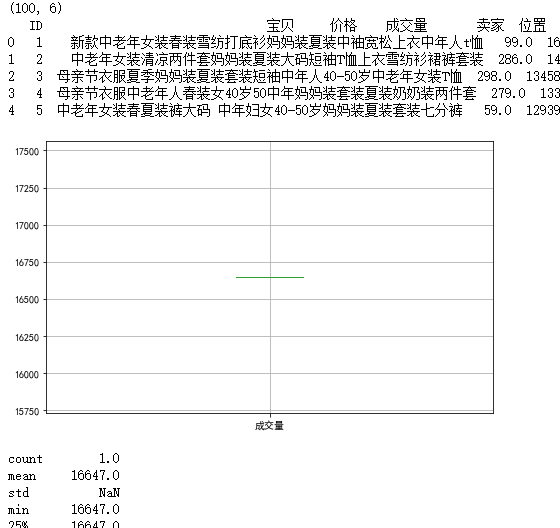
a = df[df["卖家"]=="夏奈凤凰旗舰店"]
fig,ax = plt.subplots(1,1,figsize=(8,5))
a.boxplot(column="成交量",ax=ax)
plt.show()
b = a["成交量"]
print(b.describe())
a["isOutlier"]=d>d.quantile(0.75)
c = a[a["isOutlier"]==True]
print(c)
import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(np.shape(df))
print(df.head())
a = df.duplicated()
print(np.shape(a))
print(a[:5])

import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(np.shape(df))
a = df.set_index("日期")
print(a.head())
b = a.duplicated()
print(b[:5])
import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(np.shape(df))
a = df.set_index("日期")
print(a.head())
b = a.duplicated("最高气温")
print(b[:5])

import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\hz_weather.csv")
print(type(df))
print(np.shape(df))
a = df.set_index("日期")
print(a.head())
b = a.drop_duplicates("最高气温")
print(np.shape(b))
print(b.head())

import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
print(df.head())
print(df.info())

import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = df.duplicated().value_counts()
print(a)
import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = df.drop_duplicates()
b = a.duplicated().value_counts()
print(b)

import numpy as np
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
a = df.drop_duplicates()
print(a.describe())

%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
print(np.shape(df))
fig,axes = plt.subplots(1,2,figsize=(12,5))
axes[0].hist(df["价格"],bins=20)
df.boxplot(column="价格",ax=axes[1])
plt.show()

%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\qunar_free_trip.csv")
d = df["价格"]
zscore = (d-d.mean())/d.std()
print(zscore[0:3])
df["isOutlier"]=zscore.abs()>3.5
print(df["isOutlier"].value_counts())
a = df[df["isOutlier"]==True]
print(a.head())

吴裕雄 python 数据处理(2)的更多相关文章
- 吴裕雄 python 数据处理(3)
import time a = time.time()print(a)b = time.localtime()print(b)c = time.strftime("%Y-%m-%d %X&q ...
- 吴裕雄 python 数据处理(1)
import time print(time.time())print(time.localtime())print(time.strftime('%Y-%m-%d %X',time.localtim ...
- 吴裕雄 python 神经网络——TensorFlow 输入数据处理框架
import tensorflow as tf files = tf.train.match_filenames_once("E:\\MNIST_data\\output.tfrecords ...
- 吴裕雄 python神经网络 花朵图片识别(10)
import osimport numpy as npimport matplotlib.pyplot as pltfrom PIL import Image, ImageChopsfrom skim ...
- 吴裕雄 python神经网络 花朵图片识别(9)
import osimport numpy as npimport matplotlib.pyplot as pltfrom PIL import Image, ImageChopsfrom skim ...
- 吴裕雄 python 神经网络——TensorFlow pb文件保存方法
import tensorflow as tf from tensorflow.python.framework import graph_util v1 = tf.Variable(tf.const ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(4)
# -*- coding: utf-8 -*- import glob import os.path import numpy as np import tensorflow as tf from t ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(3)
import glob import os.path import numpy as np import tensorflow as tf from tensorflow.python.platfor ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(2)
import glob import os.path import numpy as np import tensorflow as tf from tensorflow.python.platfor ...
随机推荐
- gcc gdb调试 (三)
编写代码过程中少不了调试.在windows下面,我们有visual studio工具.在linux下面呢,实际上除了gdb工具之外,你没有别的选择.那么,怎么用gdb进行调试呢?我们可以一步一步来试试 ...
- 开启postgresql的远程权限
cd /etc/postxxxx/版本号/main vim postgresql.conf 修改 #listen_addresses ='localhost'为 listen_addresses =' ...
- fiddler工具能干啥
1.通过模拟弱网进行测试(试了木有效果) http://www.cnblogs.com/LanTianYou/p/7095174.html (试了貌似没反应) http://caibaojian.co ...
- python中将HTTP头部中的GMT时间转换成datetime时间格式
原文: https://blog.csdn.net/zoulonglong/article/details/80585716 需求背景:目前在做接口的自动化测试平台,由于接口用例执行后返回的结果中的时 ...
- word2vec 的理解
1.CBOW 模型 CBOW模型包括输入层.投影层.输出层.模型是根据上下文来预测当前词,由输入层到投影层的示意图如下: 这里是对输入层的4个上下文词向量求和得到的当前词向量,实际应用中,上下文窗口大 ...
- 用Dockerfile生成docker image
在docker的官方php镜像中,有独立的php和apache版本的,这里尝试用php-fpm7.2.1(alpine3.7)作为基础镜像,在把nginx1.13.8加进去. 第一步:拉取php镜像: ...
- mysql更新(七) MySQl创建用户和授权
14-补充内容:MySQl创建用户和授权 权限管理 我们知道我们的最高权限管理者是root用户,它拥有着最高的权限操作.包括select.update.delete.update.grant等操作 ...
- selenium+python自动化90-unittest多线程执行用例
前言 假设执行一条脚本(.py)用例一分钟,那么100个脚本需要100分钟,当你的用例达到一千条时需要1000分钟,也就是16个多小时... 那么如何并行运行多个.py的脚本,节省时间呢?这就用到多线 ...
- 红帽配置Centos仓库[红帽Redhat7替换Centos7网络源]
1.卸载红帽yum源 rpm -e $(rpm -qa|grep yum) --nodeps 2.删除所有repo相关文件 rm -rf /etc/yum.conf rm -rf /etc/yum.r ...
- create a bootable USB stick on Ubuntu
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu?_ga=2.141187314.17572770 ...