7.spark Streaming 技术内幕 : 从DSteam到RDD全过程解析
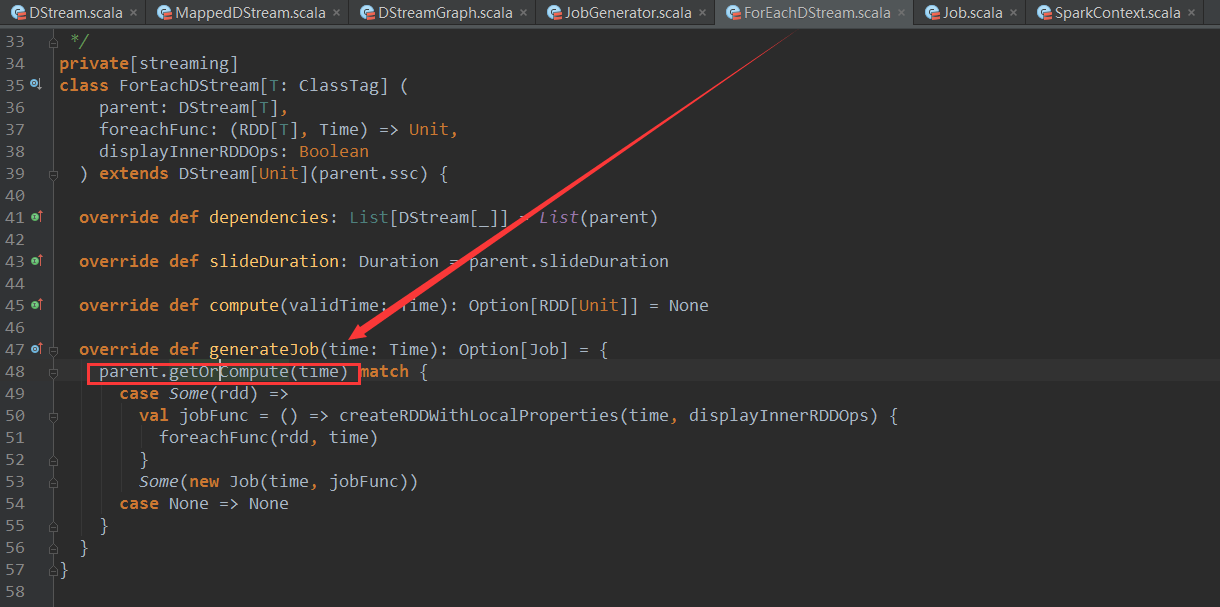
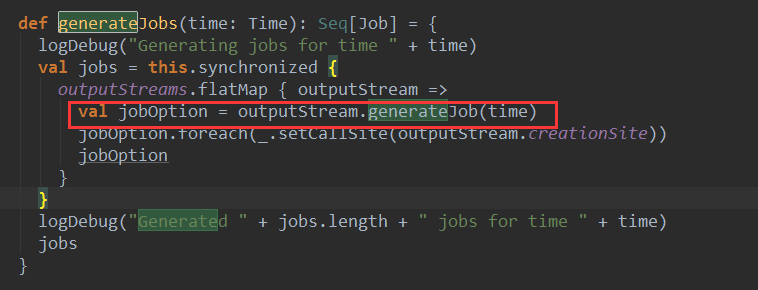
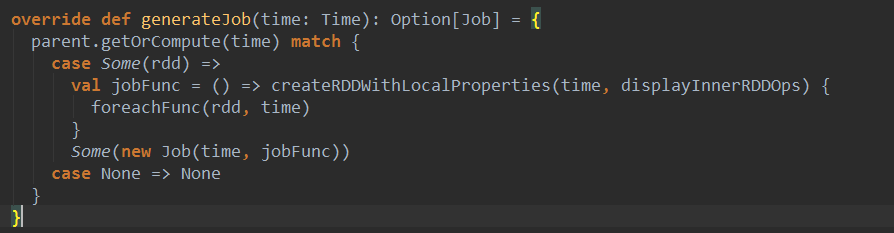
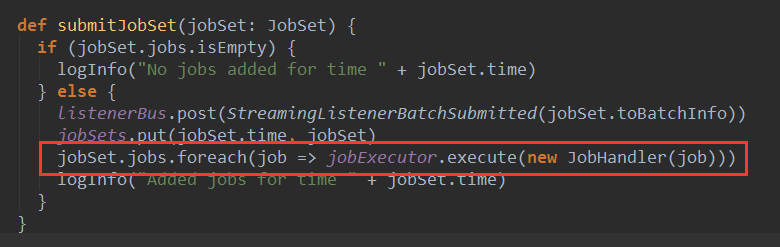
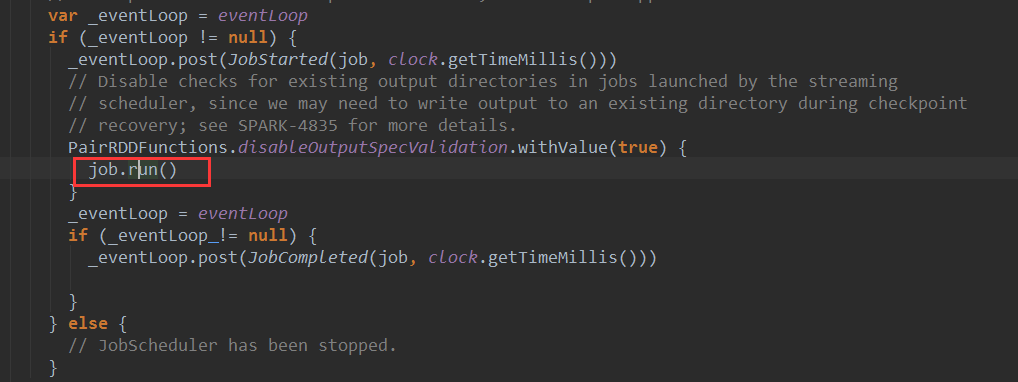
上篇博客讨论了Spark Streaming 程序动态生成Job的过程,并留下一个疑问: JobScheduler将动态生成的Job提交,然后调用了Job对象的run方法,最后run方法的调用是如何触发RDD的Action操作,从而真正触发Job的执行的呢?本文就具体讲解这个问题。
object WordCount{def main(args:Array[String]):Unit={val sparkConf =newSparkConf().setMaster("local[4]").setAppName("WordCount")val ssc =newStreamingContext(sparkConf,Seconds(1))val lines = ssc.socketTextStream("localhost",9999)val words = lines.flatMap(_.split(" "))val wordCounts = words.map(x =>(x,1)).reduceByKey(_+_)wordCounts.print()ssc.start()ssc.awaitTermination()}}



| Output Operation | Meaning |
|---|---|
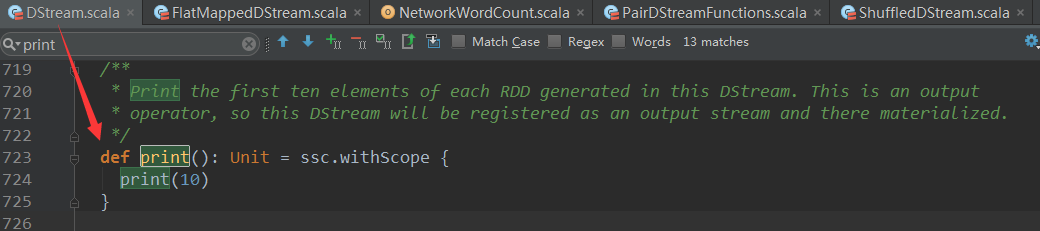
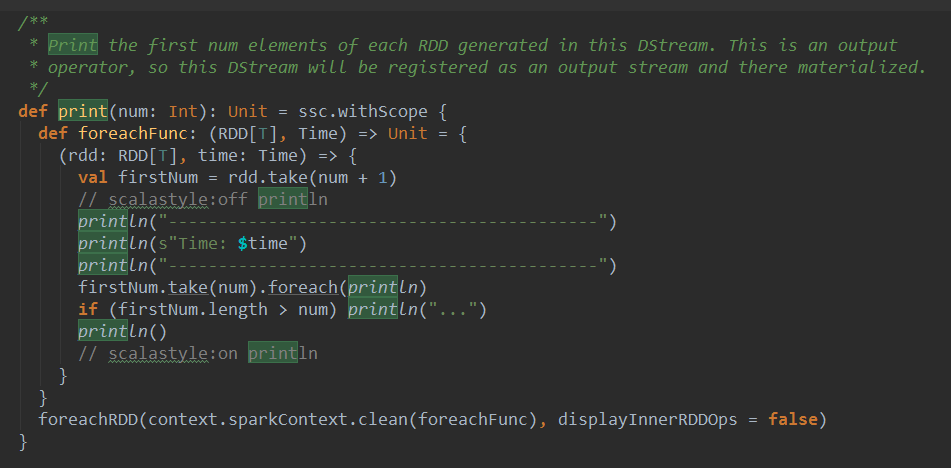
| print() | Prints the first ten elements of every batch of data in a DStream on the driver node running the streaming application. This is useful for development and debugging. Python API This is called pprint() in the Python API. |
| saveAsTextFiles(prefix, [suffix]) | Save this DStream's contents as text files. The file name at each batch interval is generated based onprefix and suffix: "prefix-TIME_IN_MS[.suffix]". |
| saveAsObjectFiles(prefix, [suffix]) | Save this DStream's contents as SequenceFiles of serialized Java objects. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". Python API This is not available in the Python API. |
| saveAsHadoopFiles(prefix, [suffix]) | Save this DStream's contents as Hadoop files. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". Python API This is not available in the Python API. |
| foreachRDD(func) | The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs. |


7.spark Streaming 技术内幕 : 从DSteam到RDD全过程解析的更多相关文章
- 9. Spark Streaming技术内幕 : Receiver在Driver的精妙实现全生命周期彻底研究和思考
原创文章,转载请注明:转载自 听风居士博客(http://www.cnblogs.com/zhouyf/) Spark streaming 程序需要不断接收新数据,然后进行业务逻辑 ...
- Spark streaming技术内幕6 : Job动态生成原理与源码解析
原创文章,转载请注明:转载自 周岳飞博客(http://www.cnblogs.com/zhouyf/) Spark streaming 程序的运行过程是将DStream的操作转化成RDD的操作,S ...
- 6.Spark streaming技术内幕 : Job动态生成原理与源码解析
原创文章,转载请注明:转载自 周岳飞博客(http://www.cnblogs.com/zhouyf/) Spark streaming 程序的运行过程是将DStream的操作转化成RDD的操作, ...
- 贯通Spark Streaming JobScheduler内幕实现和深入思考
本节主要内容: 一.SparkStreaming Job生成深度思考 二.SparkStreaming Job生成源码解析 JobScheduler的地位非常的重要,所有的关键都在JobSchedul ...
- 16.Spark Streaming源码解读之数据清理机制解析
原创文章,转载请注明:转载自 听风居士博客(http://www.cnblogs.com/zhouyf/) 本期内容: 一.Spark Streaming 数据清理总览 二.Spark Streami ...
- 10.Spark Streaming源码分析:Receiver数据接收全过程详解
原创文章,转载请注明:转载自 听风居士博客(http://www.cnblogs.com/zhouyf/) 在上一篇中介绍了Receiver的整体架构和设计原理,本篇内容主要介绍Receiver在 ...
- Spark技术内幕:Sort Based Shuffle实现解析
在Spark 1.2.0中,Spark Core的一个重要的升级就是将默认的Hash Based Shuffle换成了Sort Based Shuffle,即spark.shuffle.manager ...
- 9.Spark Streaming
Spark Streaming 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性 ...
- Spark Streaming的优化之路—从Receiver到Direct模式
作者:个推数据研发工程师 学长 1 业务背景 随着大数据的快速发展,业务场景越来越复杂,离线式的批处理框架MapReduce已经不能满足业务,大量的场景需要实时的数据处理结果来进行分析.决 ...
随机推荐
- bzoj 2095 [Poi2010]Bridges 判断欧拉维护,最大流+二分
[Poi2010]Bridges Time Limit: 10 Sec Memory Limit: 259 MBSubmit: 1448 Solved: 510[Submit][Status][D ...
- CentOS 下安装 LEMP 服务(nginx、MariaDB/MySQL 和 php)
转载自:https://linux.cn/article-4314-1.html 编译自:http://xmodulo.com/install-lemp-stack-centos.html 作者: D ...
- [LeetCode] string整体做hash key,窗口思想复杂度O(n)。附来自LeetCode的4例题(标题有字数限制,写不下所有例题题目 T.T)
引言 在字符串类型的题目中,常常在解题的时候涉及到大量的字符串的两两比较,比如要统计某一个字符串出现的次数.如果每次比较都通过挨个字符比较的方式,那么毫无疑问是非常占用时间的,因此在一些情况下,我们可 ...
- telnet退出
windows下退出telnet:可以参考下面linux退出,也可以直接关闭窗口. linux退出telnet: 1.输入ctrl+]:显示出telnet>. 2.此时可以输入?,查看可以使用的 ...
- mongo在centos与windows上部署与配置,及远程连接mongo与数据用户和角色分配
1.下载mongodb社区版: windows 安装包安装: https://www.mongodb.com/download-center#community(mongo下载中心) 配置环境变量 控 ...
- HDU 5869 Different GCD Subarray Query 树状数组+离线
Problem Description This is a simple problem. The teacher gives Bob a list of problems about GCD (Gr ...
- Maven搭建SpringMVC + SpringJDBC项目详解
前言 上一次复习搭建了SpringMVC+Mybatis,这次搭建一下SpringMVC,采用的是SpringJDBC,没有采用任何其他的ORM框架,SpringMVC提供了一整套的WEB框架,所以如 ...
- ssh连接提示 "Connection closed by remote host"
如果原来是可以用ssh连接的, 突然连接不上通常是连接数过多导致的. 解决方法一. 把SSH连接数改大 修改服务器上的这个文件:/etc/ssh/sshd_config 找到这行: # MaxSess ...
- js获取摄像头视频流
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- [uva11997]k个最小和
一个k*k的矩阵,每行选取一个数相加则得到一个和,求最小的前k个和. k<=750 已知前m行最小的前k个和d[1]…d[k],则前m+1行最小的前k个和都必定是d[i](i<=k)+a[ ...