[转载]机器学习优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
[转载]机器学习优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
https://blog.csdn.net/u010089444/article/details/76725843
这篇博客格式不好直接粘贴,就不附原文了。
有几个点可以注意下,原文没有写的很清楚:
优化方法的作用是什么?
可以说,没有优化方法,机器学习模型一般一样可以执行,所以说它并不是必须的。但是优化方法可以动态调整学习率以及影响迭代中参数调整的方向和幅度,可以加速收敛,是对原方法的一种优化。
Momentum:
Momentum方法一般用来辅助SGD,从下图也能看出来:
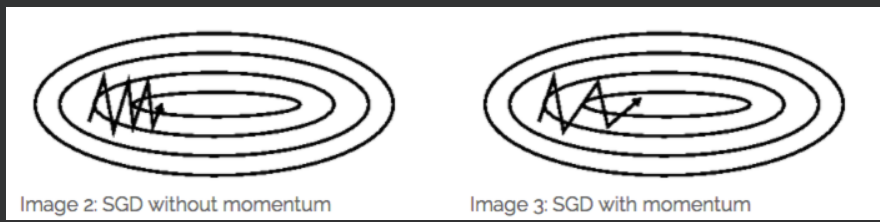
它的作用是加速SGD,并且抑制震荡。
另外,从原理上来说,它应用在BGD上也没有什么问题。
Nesterov Momentum方法是Momentum方法的一种改进,思路也是和传统的思路比较类似的:传统思路中,在一次参数更新中,更新后面的参数如果要使用前面的参数,则使用本次更新中前面参数已经更新了的值可以加速收敛。这里是反过来了:先更新vt,后更新梯度。但是vt的计算中要用到梯度,这里就使用梯度更新后的值可以使得结果更加准确、收敛更快。但是这时更新值还没有计算出来,于是使用了”预测“值,J中的梯度计算取的是迭代公式中的线性部分。
什么是”矩估计“
来源:https://baike.baidu.com/item/%E7%9F%A9%E4%BC%B0%E8%AE%A1
矩估计,即矩估计法,也称“矩法估计”,就是利用样本矩来估计总体中相应的参数。首先推导涉及感兴趣的参数的总体矩(即所考虑的随机变量的幂的期望值)的方程。然后取出一个样本并从这个样本估计总体矩。接着使用样本矩取代(未知的)总体矩,解出感兴趣的参数。从而得到那些参数的估计。
其实就是用样本估计总体
在实际应用中 ,Adam为最常用的方法,可以比较快地得到一个预估结果
[转载]机器学习优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam的更多相关文章
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam) 深度学习笔记(一):logistic分类 深度学习笔记(二):简单神经网络,后向传播算法及实现 ...
- 优化方法:SGD,Momentum,AdaGrad,RMSProp,Adam
参考: https://blog.csdn.net/u010089444/article/details/76725843 1. SGD Batch Gradient Descent 在每一轮的训练过 ...
- 机器学习优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
SGD: 此处的SGD指mini-batch gradient descent,关于batch gradient descent, stochastic gradient descent, 以及 mi ...
- 优化器,SGD+Momentum;Adagrad;RMSProp;Adam
Optimization 随机梯度下降(SGD): 当损失函数在一个方向很敏感在另一个方向不敏感时,会产生上面的问题,红色的点以“Z”字形梯度下降,而不是以最短距离下降:这种情况在高维空间更加普遍. ...
- 5、Tensorflow基础(三)神经元函数及优化方法
1.激活函数 激活函数(activation function)运行时激活神经网络中某一部分神经元,将激活信息向后传入下一层的神经网络.神经网络之所以能解决非线性问题(如语音.图像识别),本质上就是激 ...
- Deep Learning基础--参数优化方法
1. 深度学习流程简介 1)一次性设置(One time setup) -激活函数(Activation functions) - 数据预处理(Data Preprocessing) ...
- 各种优化方法总结比较(sgd/momentum/Nesterov/adagrad/adadelta)
前言 这里讨论的优化问题指的是,给定目标函数f(x),我们需要找到一组参数x,使得f(x)的值最小. 本文以下内容假设读者已经了解机器学习基本知识,和梯度下降的原理. Batch gradient d ...
- 深度学习常见的优化方法(Optimizer)总结:Adam,SGD,Momentum,AdaGard等
机器学习的常见优化方法在最近的学习中经常遇到,但是还是不够精通.将自己的学习记录下来,以备不时之需 基础知识: 机器学习几乎所有的算法都要利用损失函数 lossfunction 来检验算法模型的优劣, ...
- 优化方法总结以及Adam存在的问题(SGD, Momentum, AdaDelta, Adam, AdamW,LazyAdam)
优化方法总结以及Adam存在的问题(SGD, Momentum, AdaDelta, Adam, AdamW,LazyAdam) 2019年05月29日 01:07:50 糖葫芦君 阅读数 455更多 ...
随机推荐
- HearthBuddy Ai 调试实战2 在使用海巨人的时候,少召唤了一个图腾(费用是对的)
问题 游戏面板 8是青玉之爪13是海巨人17是恐狼前锋 64是萨满 66是圣骑士63,99,46,是微型木乃伊[其中99和46都是2血3攻,63是2血1攻]57是鱼人木乃伊 微型木乃伊 "L ...
- JDBC的异常处理方式
A: try...catch(...) {...} finally {} B: 关闭ResultSet,Statement , Connection import java.sql.Connectio ...
- linux简单命令8---用户登录查看命令
---------------------------------------------------------------------------------------------------- ...
- java.lang.NoClassDefFoundError: org/springframework/aop/TargetSource
在使用Spring框架时 报错 :java.lang.NoClassDefFoundError: org/springframework/aop/TargetSource 原因:为引入spring-a ...
- groupby+agg
一.在处理pandas表格数据时,有时会遇到这样的问题:按照某一列聚合后,判断另一列是否出现唯一值,比如安泰杯--跨境电商比赛中,某个商人的ID如果出现在两个国家(xx和yy),则要剔除这样的数据,这 ...
- 使用 bash 脚本把 AWS EC2 数据备份到 S3
目录 一.IAM 秘钥授权方式(普通) 1.1.打开 IAM 1.2.添加用户 1.3.安装和配置 AWS CLI 1.4.配置授权 二.IAM 角色授权方式(安全) 2.1.创建一个 EC2 访问 ...
- Jmeter 逻辑控制器 之 循环控制器
今天和大家分享下循环控制器的使用. 一.认识循环控制器 如下图:新增一个循环控制器 循环控制器的设置界面: 循环次数:永远和自定义次数,这个应该比较好理解. 二.使用循环控制器 其实大家对Jmeter ...
- FFMPEG 常用命令行
目录 1. 分离音视频 2. 解复用 3. 视频转码 4. 视频封装 5. 视频剪切 6. 视频录制 7.叠加水印 8.将MP3转换为PCM数据 9. 推送RTP流.接收RTP流并存为ts文件 10. ...
- zabbix监控LAMP全教程
一.安装前准备 A.下载yum源 1.备份/etc/yum.repos.d/CentOS-Base.repo ,在备份之前,要先安装wget 插件 #mv /etc/yum.repos.d/CentO ...
- OpenCV2.源码_编译&调试
1.VS 调试第三方库源码 - writeeee的专栏 - CSDN博客.html(https://blog.csdn.net/writeeee/article/details/82692770) Z ...