MapReduce编程之wordcount
实践
MapReduce编程之wordcount
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /**
* 使用MapReduce开发WordCount的应用程序
*/
public class WordCountApp { /**
* Map:读取输入的文件
*/
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{ LongWritable one = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 接收到的每一行数据
String line = value.toString();
//按照指定分隔符进行拆分
String[] words = line.split(" ");
for(String word : words){
// 通过上下文把map的处理结果输出
context.write(new Text(word),one);
}
} } /**
* 归并操作
*/
public static class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for(LongWritable value : values){
//求key出现的次数和
sum += value.get();
}
context.write(key, new LongWritable(sum));
}
} /**
* 定义Driver:封装lMapReduce作业的所有信息
* @param args
*/
public static void main(String[] args) throws Exception{
//创建configuration
Configuration configuration = new Configuration();
//准备清理已存在的输出目录
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
System.out.println("out file exists,but is has deleted!");
}
//创建job
Job job = Job.getInstance(configuration,"WordCount");
//设置job的处理类
job.setJarByClass(WordCountApp.class);
//设置作业处理的输入路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
//设置map相关参数
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce相关参数
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置作业处理的输出路径
FileOutputFormat.setOutputPath(job , new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
运行
hadoop jar hadoop-train-1.0-SNAPSHOT.jar WordCountApp /hdfsapi/test/b.txt /hdfsapi/test/out
MapReduce编程之Combiner
本地reduce(map端reduce)
减少Map Tasks输出的数据量及数据网络传输量
combiner案例开发
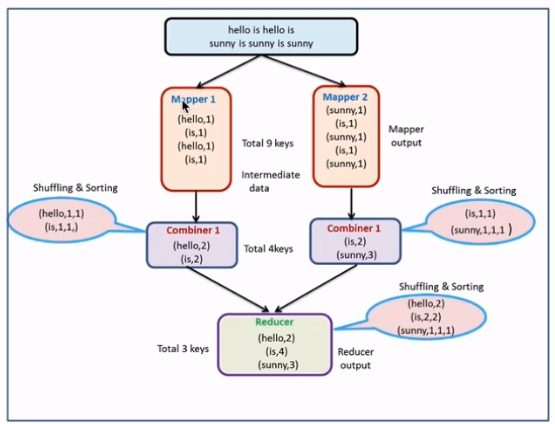
使用场景:求和、求次数
代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /**
* 使用MapReduce开发WordCount的应用程序
*/
public class CombinerApp { /**
* Map:读取输入的文件
*/
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{ LongWritable one = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 接收到的每一行数据
String line = value.toString();
//按照指定分隔符进行拆分
String[] words = line.split(" ");
for(String word : words){
// 通过上下文把map的处理结果输出
context.write(new Text(word),one);
}
} } /**
* 归并操作
*/
public static class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for(LongWritable value : values){
//求key出现的次数和
sum += value.get();
}
context.write(key, new LongWritable(sum));
}
} /**
* 定义Driver:封装lMapReduce作业的所有信息
* @param args
*/
public static void main(String[] args) throws Exception{ //创建configuration
Configuration configuration = new Configuration();
//准备清理已存在的输出目录
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
System.out.println("out file exists,but is has deleted!");
}
//创建job
Job job = Job.getInstance(configuration,"WordCount");
//设置job的处理类
job.setJarByClass(CombinerApp.class);
//设置作业处理的输入路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
//设置map相关参数
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce相关参数
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//通过job的设置combiner处理类,其实逻辑上和我们的reduce是一模一样的
job.setCombinerClass(MyReduce.class);
//设置作业处理的输出路径
FileOutputFormat.setOutputPath(job , new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
- 执行命令
hadoop jar hadoop-train-1.0-SNAPSHOT.jar WordCountApp /hdfsapi/test/b.txt /hdfsapi/test/out
MapReduce编程之Partitioner
partitioner决定MapTask输出的数据交由哪个ReduceTask处理
默认实现:分发的key的hash值对ReduceTask个数取模
partitioner案例开发
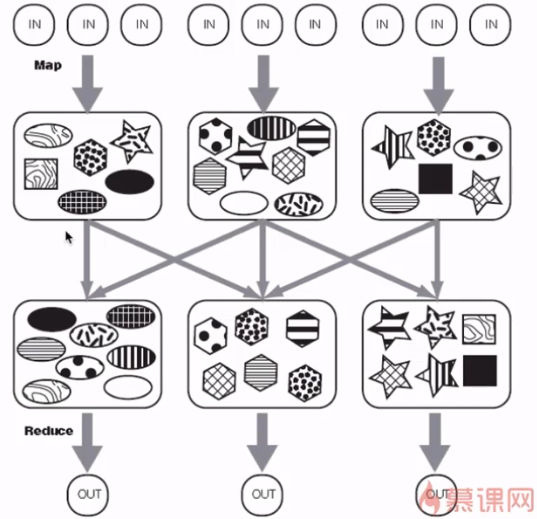
- 代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /**
* 使用MapReduce开发WordCount的应用程序
*/
public class PartitionerApp { /**
* Map:读取输入的文件
*/
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{ LongWritable one = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 接收到的每一行数据
String line = value.toString();
//按照指定分隔符进行拆分
String[] words = line.split(" ");
context.write(new Text(words[0]),new LongWritable(Long.parseLong(words[1])));
}
} /**
* 归并操作
*/
public static class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for(LongWritable value : values){
//求key出现的次数和
sum += value.get();
}
context.write(key, new LongWritable(sum));
}
} public static class MyPartitioner extends Partitioner<Text,LongWritable>{
@Override
public int getPartition(Text key, LongWritable longWritable, int i) {
if(key.toString().equals("xiaomi")){
return 0;
}
if(key.toString().equals("huawei")){
return 1;
}
if(key.toString().equals("iphone")){
return 2;
}
return 3;
}
}
/**
* 定义Driver:封装lMapReduce作业的所有信息
* @param args
*/
public static void main(String[] args) throws Exception{ //创建configuration
Configuration configuration = new Configuration();
//准备清理已存在的输出目录
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
System.out.println("out file exists,but is has deleted!");
}
//创建job
Job job = Job.getInstance(configuration,"WordCount");
//设置job的处理类
job.setJarByClass(PartitionerApp.class);
//设置作业处理的输入路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
//设置map相关参数
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce相关参数
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//通过job的设置partition
job.setPartitionerClass(MyPartitioner.class);
//设置4个reduce,每个分区一个
job.setNumReduceTasks(4);
//设置作业处理的输出路径
FileOutputFormat.setOutputPath(job , new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
- 执行命令
hadoop jar hadoop-train-1.0-SNAPSHOT.jar PartitionerApp /hdfsapi/test/partitioner /hdfsapi/test/outpartitioner
MapReduce编程之wordcount的更多相关文章
- mapReduce编程之auto complete
1 n-gram模型与auto complete n-gram模型是假设文本中一个词出现的概率只与它前面的N-1个词相关.auto complete的原理就是,根据用户输入的词,将后续出现概率较大的词 ...
- mapReduce编程之Recommender System
1 协同过滤算法 协同过滤算法是现在推荐系统的一种常用算法.分为user-CF和item-CF. 本文的电影推荐系统使用的是item-CF,主要是由于用户数远远大于电影数,构建矩阵的代价更小:另外,电 ...
- mapReduce编程之google pageRank
1 pagerank算法介绍 1.1 pagerank的假设 数量假设:每个网页都会给它的链接网页投票,假设这个网页有n个链接,则该网页给每个链接平分投1/n票. 质量假设:一个网页的pagerank ...
- MapReduce编程之Reduce Join多种应用场景与使用
在关系型数据库中 Join 是非常常见的操作,各种优化手段已经到了极致.在海量数据的环境下,不可避免的也会碰到这种类型的需求, 例如在数据分析时需要连接从不同的数据源中获取到数据.不同于传统的单机模式 ...
- MapReduce编程之Semi Join多种应用场景与使用
Map Join 实现方式一 ● 使用场景:一个大表(整张表内存放不下,但表中的key内存放得下),一个超大表 ● 实现方式:分布式缓存 ● 用法: SemiJoin就是所谓的半连接,其实仔细一看就是 ...
- MapReduce编程之Map Join多种应用场景与使用
Map Join 实现方式一:分布式缓存 ● 使用场景:一张表十分小.一张表很大. ● 用法: 在提交作业的时候先将小表文件放到该作业的DistributedCache中,然后从DistributeC ...
- Hadoop基础-Map端链式编程之MapReduce统计TopN示例
Hadoop基础-Map端链式编程之MapReduce统计TopN示例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.项目需求 对“temp.txt”中的数据进行分析,统计出各 ...
- 网络编程之socket
网络编程之socket socket:在网络编程中的一个基本组件,也称套接字. 一个套接字就是socket模块中的socket类的一个实例. 套接字包括两个: 服务器套接字和客户机套接字 套接字的实例 ...
- C++混合编程之idlcpp教程Python篇(9)
上一篇在这 C++混合编程之idlcpp教程Python篇(8) 第一篇在这 C++混合编程之idlcpp教程(一) 与前面的工程相比,工程PythonTutorial7中除了四个文件PythonTu ...
随机推荐
- BOM心得-定时器
写在前面的话:之前一直以为定时器的返回值是Object类型,所以timer初始化也是写null,今天发现返回值是number,进而发觉这个返回值代表的是定时器的索引,指代这是第几个定时器 个人觉得只用 ...
- mtcp的快速编译(连接)
mtcp的快速编译 http://mos.kaist.edu/guide/config/03_build_mtcp.html 介绍DPDK中使用mtcp的文档 https://dpdksummit.c ...
- Linux服务器有什么优势?
为您的企业选择服务器时,您可以选择几种不同的选项.虽然许多公司使用基于Windows的服务器,但选择Linux服务器可能是您最好的选择.为什么Linux服务器比其他服务器更好?以下是使用Linux服务 ...
- How to use bmw icom a2
Lan Connect Operation Details 1. Connect the LAN cable to ICOM A1/ICOM A2, another side to laptop LA ...
- BZOJ1059或洛谷1129 [ZJOI2007]矩阵游戏
BZOJ原题链接 洛谷原题链接 通过手算几组例子后,很容易发现,同一列的\(1\)永远在这一列,且这些\(1\)有且仅有一个能产生贡献,行同理. 所以我们可以只考虑交换列,使得每一行都能匹配一个\(1 ...
- BUG(1):一个关于指针的bug
是时候记录一下这个让我栽了两次的bug了. 具体情况如下: #include <stdio.h>#include <stdlib.h> struct app_info_t { ...
- 用PS绘制立体字的效果教程
1. 新建一个透明画布. 2. 利用选区绘制一个圆圈 3. 利用渐变工具绘制渐变 (颜色自拟) 4. 选择混合器画笔工具按住ALT 点击填充颜色的图层 5. 新建画布填充黑色 利用混合画笔进行绘制. ...
- Python之路(第九篇)Python文件操作
一.文件的操作 文件句柄 = open('文件路径+文件名', '模式') 例子 f = open("test.txt","r",encoding = “utf ...
- ssrf绕过总结
前言 昨天忘了在公众号还是微博上看到的了,看到一个SSRF绕过的技巧,使用的是 ⓔⓧⓐⓜⓟⓛⓔ.ⓒⓞⓜ 绕过的,自己也没遇到过.然后想想自己对SSRF绕过还是停留在之前的了解,也没学习过新的绕过方法, ...
- 繁体简体转化_langconv.py
from copy import deepcopyimport re try: import psyco psyco.full()except: pass try: from zh_wiki impo ...