使用 IntelliJ IDEA 导入 Spark 最新源码及编译 Spark 源代码(博主强烈推荐)
前言
其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来。
本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程。
准备工作
1、scala 2.10.4(本地的安装)
Scala的安装(本地)
2、Jdk1.7+ 或 jdk1.8+ (本地的安装)
Jdk 1.7*安装并配置
Jdk 1.8*安装并配置
JDK的windows和Linux版本之下载
3、IntelliJ IDEA
IntelliJ IDEA(Community版本)的下载、安装和WordCount的初步使用(本地模式和集群模式)
IntelliJ IDEA(Ultimate版本)的下载、安装和WordCount的初步使用(本地模式和集群模式)
Spark源码的编译过程详细解读(各版本)
另外,最后还是建议大家开始先使用 pre-built 的 Spark,对 Spark 的运行、使用方法有所了解,编写了一些 Spark 应用程序后再展开源代码的阅读,并尝试修改源码,进行手动编译。
总体流程
1、从 Github 导入 Spark 工程
打开IntelliJ IDEA 后,在菜单栏中选择 VCS→Check out from Version Control→Git,之后在 Git Repository URL 中填入 Spark 项目的地址,并指定好本地路径,如下图所示。

https://github.com/apache/spark.git





或者,我们可以直接先下载好,
比如我这里,已经下载好了

解压,
提前,先准备好
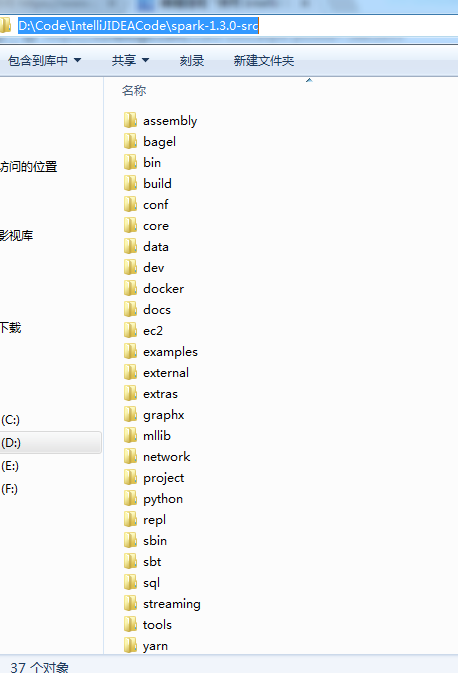
对于spark源码的目录结构
1、编译相关 : sbt 、assembly、project
2、spark核心 :core
3、Spark Lib : streaming 、 sql 、graphx 、mllib
4、运行脚本和配置 : bin 、sbin 、conf
5、虚拟化 : ec2 、docker 、dev
6、式例 : examples 、data
7、部署相关: yarn
8、python支持 : python
9、repl : repl
10、 3pp : externals
现在,我开始,进入spark源码导入工作。

先来关闭,已有的工程。
File -> Close Project
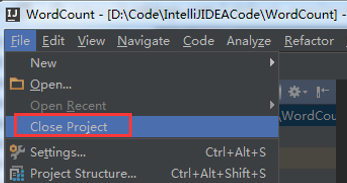
得到,如下

选择,Import Project

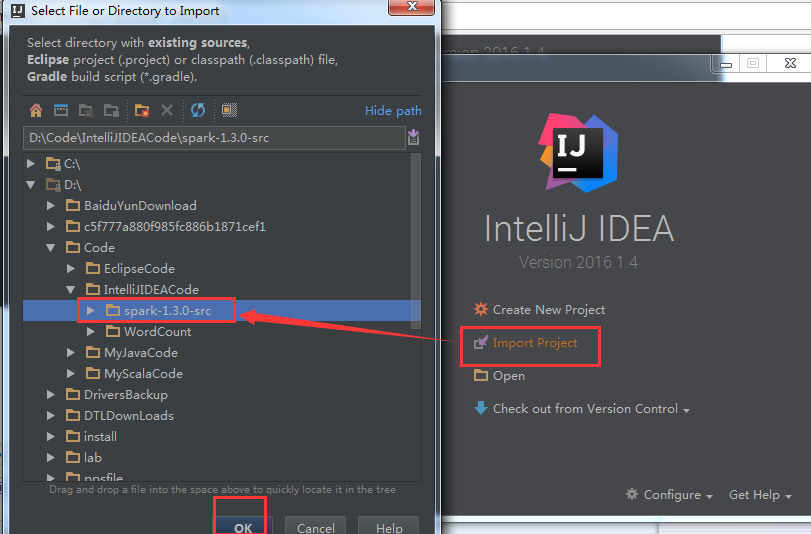
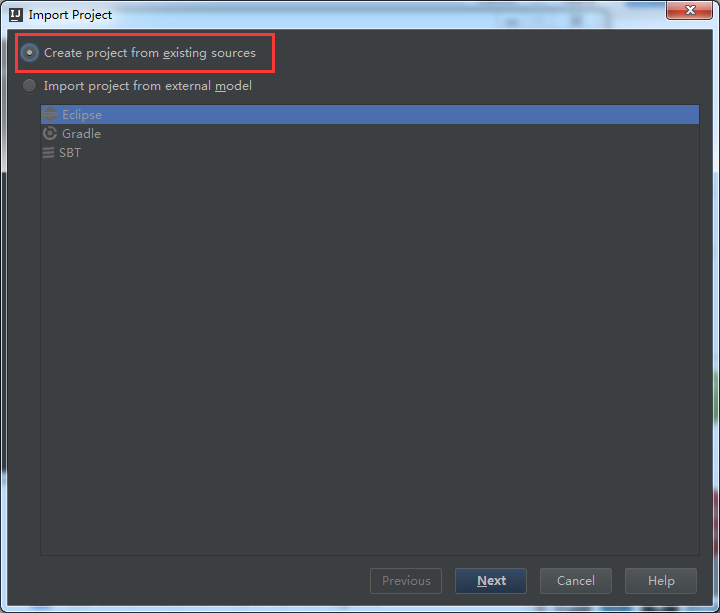
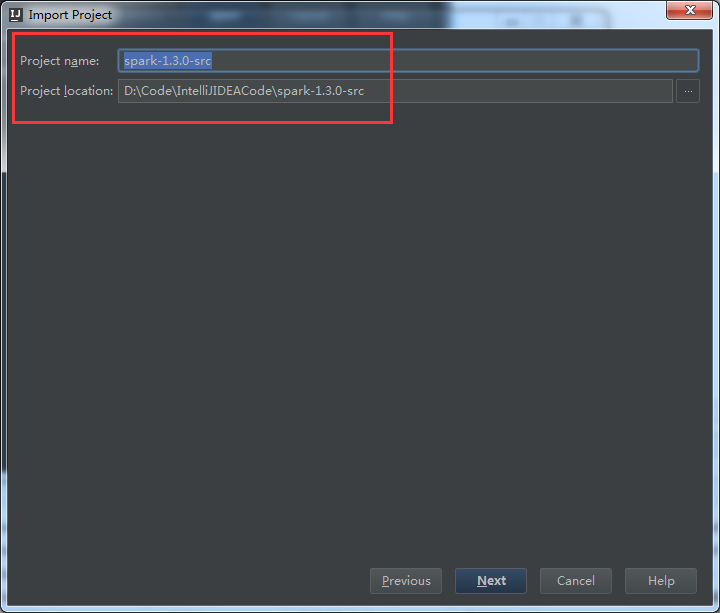
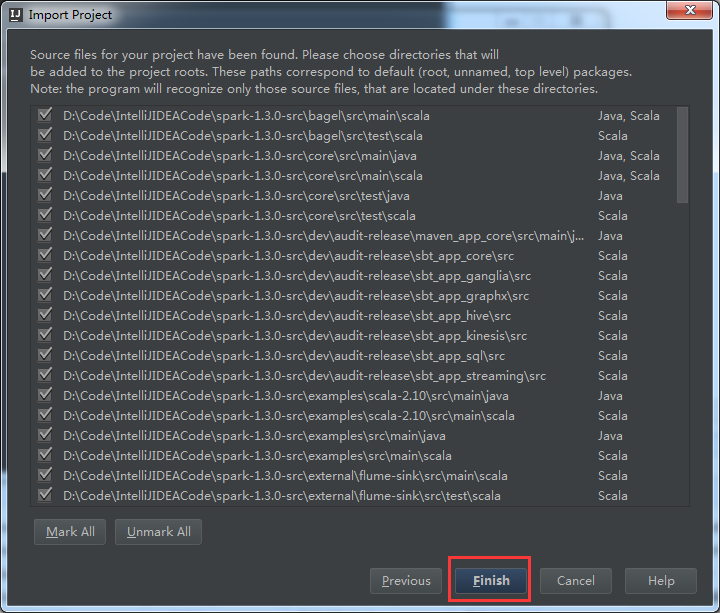
这里,为了日后的spark源码阅读环境的方便和开发
安装之后的几个常用设置:
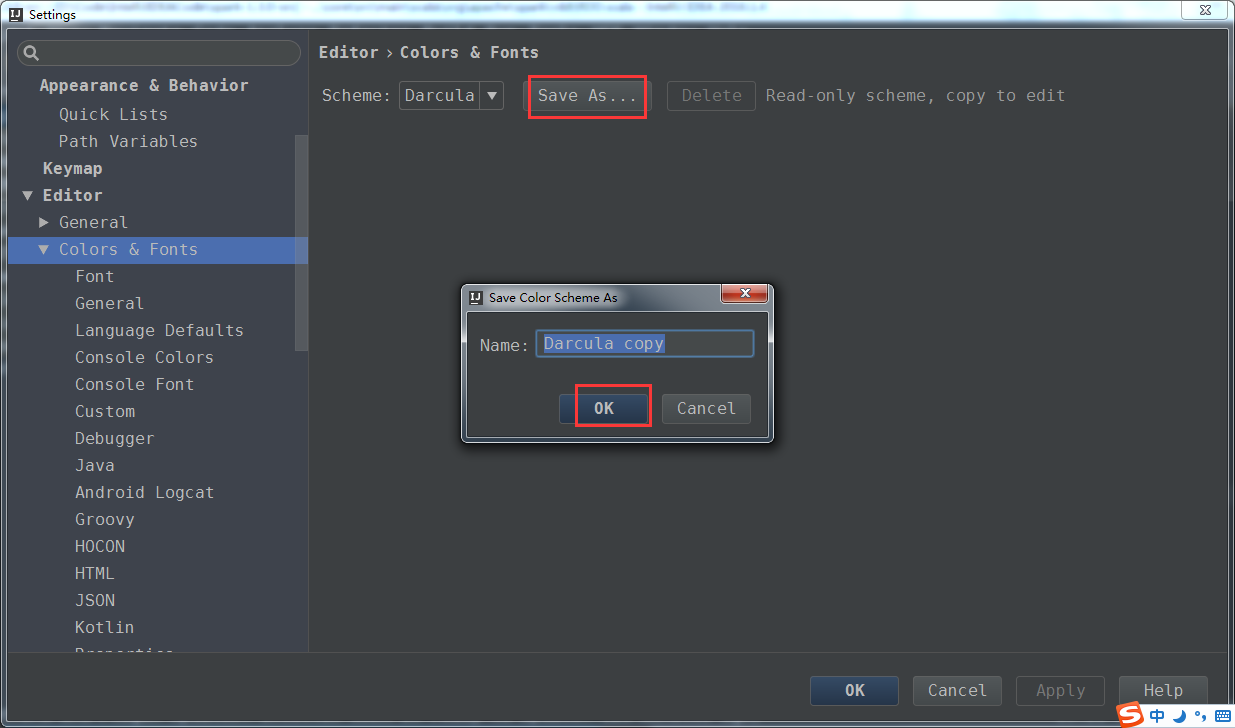
1、界面字体大小的设置


可见,界面字体的效果
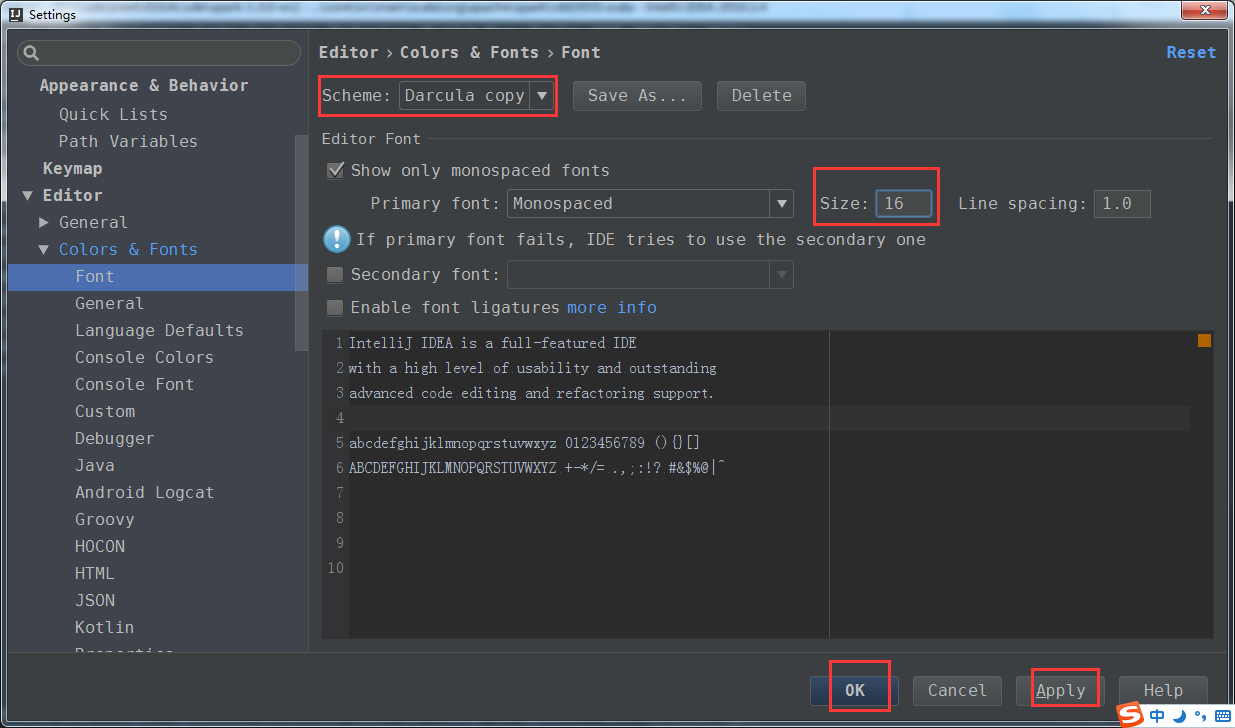
2、代码字体的设置
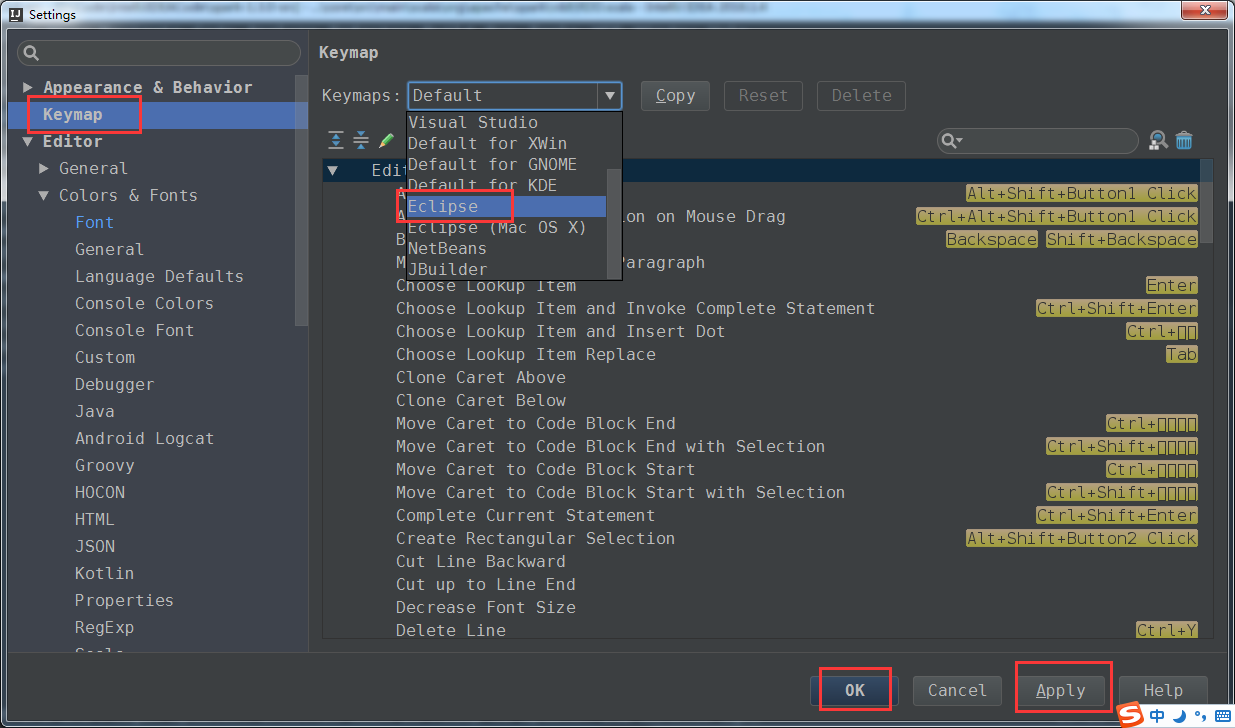
3、因我们平常,用习惯了eclipse,快捷键,设置为我们平常,eclipse的风格。
完成
简单,带领,如何巧看spark源码?
这里,为了避免一个不利的阅读,
放到D盘的根目录下,







设置行号

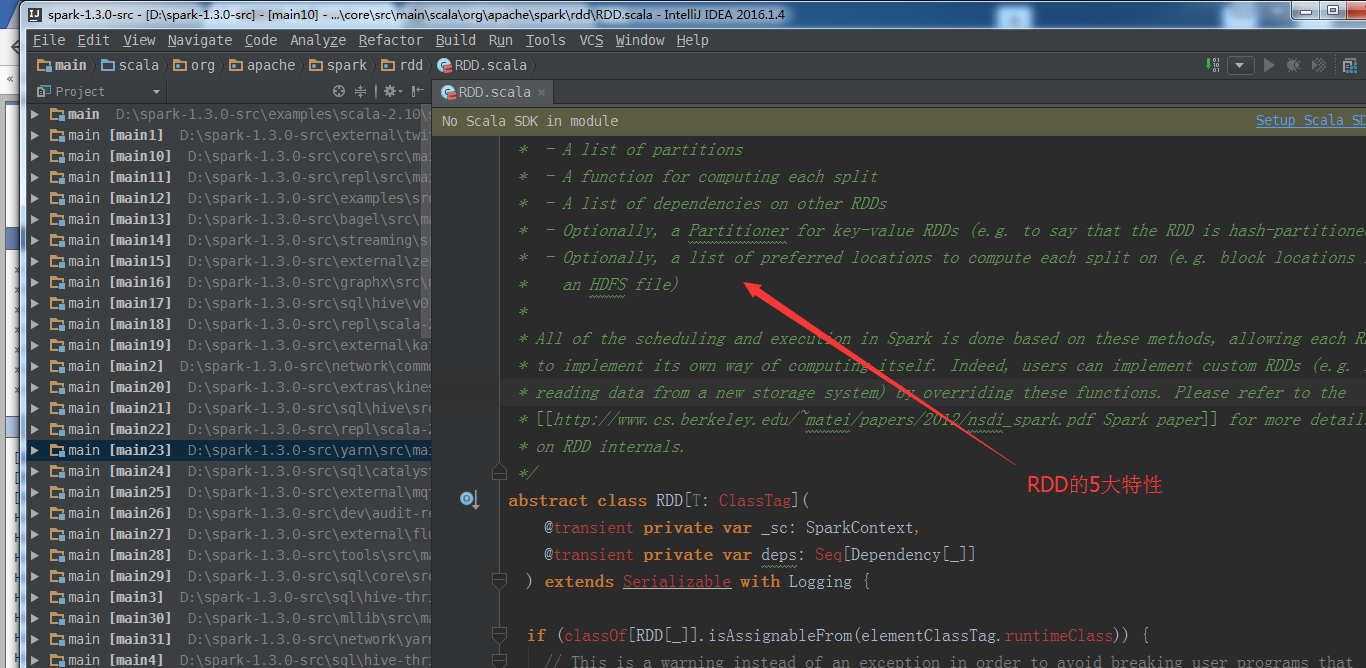
其他的源码,首先,Ctrl + Shift + R,然后,自行去阅读。
建议,在理解概念,真的,可以拿源码来帮助理解!
总结
所以啊,源码 + 官网 ,是黄金组合。
更新博客(2017年),见
spark最新源码下载并导入到开发环境下助推高质量代码(Scala IDEA for Eclipse和IntelliJ IDEA皆适用)(以spark2.2.0源码包为例)(图文详解)
如何在IDEA里给大数据项目导入该项目的相关源码(博主推荐)(图文详解)
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
以及对应本平台的QQ群:161156071(大数据躺过的坑)


使用 IntelliJ IDEA 导入 Spark 最新源码及编译 Spark 源代码(博主强烈推荐)的更多相关文章
- 使用 IntelliJ IDEA 导入 Spark 最新源码及编译 Spark 源代码
前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. 准备工作 1.sca ...
- spark最新源码下载并导入到开发环境下助推高质量代码(Scala IDEA for Eclipse和IntelliJ IDEA皆适用)(以spark2.2.0源码包为例)(图文详解)
不多说,直接上干货! 前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. ...
- 使用 IntelliJ IDEA 导入 Spark源码及编译 Spark 源代码
1. 准备工作 首先你的系统中需要安装了 JDK 1.6+,并且安装了 Scala.之后下载最新版的 IntelliJ IDEA 后,首先安装(第一次打开会推荐你安装)Scala 插件,相关方法就不多 ...
- Spark编程环境搭建(基于Intellij IDEA的Ultimate版本)(包含Java和Scala版的WordCount)(博主强烈推荐)
福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- windows下在idea用maven导入spark2.3.1源码并编译并运行示例
一.前提 1.配置好maven:intellij idea maven配置及maven项目创建 2.下载好spark源码: 二.导入源码: 1.将下载的源码包spark-2.3.1.tgz解压(E:\ ...
- Spark源码的编译过程详细解读(各版本)
说在前面的话 重新试多几次.编译过程中会出现下载某个包的时间太久,这是由于连接网站的过程中会出现假死,按ctrl+c,重新运行编译命令. 如果出现缺少了某个文件的情况,则要先清理maven(使用命 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- Spark源码的编译过程详细解读(各版本)(博主推荐)
不多说,直接上干货! 说在前面的话 重新试多几次.编译过程中会出现下载某个包的时间太久,这是由于连接网站的过程中会出现假死,按ctrl+c,重新运行编译命令. 如果出现缺少了某个文件的情况,则要 ...
- 第一篇:Spark SQL源码分析之核心流程
/** Spark SQL源码分析系列文章*/ 自从去年Spark Submit 2013 Michael Armbrust分享了他的Catalyst,到至今1年多了,Spark SQL的贡献者从几人 ...
随机推荐
- CVO实现过程
module vid_cvo #( , , , , , )( input clk, input rst_p, :] idata, input ivalid, input vid_sop, input ...
- git服务器使用
服务器版本:CentOS6.3 root用户密码:123456 服务器地址:192.168.1.125 搭建Git服务器参考:搭建Git服务器 使用git服务器首先要克隆仓库,即添加一个远程仓库,参考 ...
- css的三种使用方式:行内样式,内嵌样式,外部引用样式
三中的使用方法的简单实例如下: 行内样式: <!doctype html> <html> <head> <meta charset="UTF-8&q ...
- Hdu1205 吃糖果 2017-06-29 14:26 24人阅读 评论(0) 收藏
吃糖果 Problem Description HOHO,终于从Speakless手上赢走了所有的糖果,是Gardon吃糖果时有个特殊的癖好,就是不喜欢将一样的糖果放在一起吃,喜欢先吃一种,下一次吃另 ...
- Hdu 1009 FatMouse' Trade 2016-05-05 23:02 86人阅读 评论(0) 收藏
FatMouse' Trade Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Tot ...
- execl 导入
/** * 导入Excel功能 是把execl表中的数据添加到数据表中 */ public function import(){ if (!empty($_FILES)) { $file = re ...
- Scala_继承
继承 Scala与Java在继承方面的区别 Scala中的继承与Java有着显著的不同: 重写一个非抽象方法必须使用override修饰符 只有主构造器可以调用超类的主构造器 在子类中重写超类的抽象方 ...
- JQuery实用技巧
1.关于页面元素的引用通过jquery的$()引用元素包括通过id.class.元素名以及元素的层级关系及dom或者xpath条件等方法,且返回的对象为jquery对象(集合对象),不能直接调用dom ...
- artificial neural network in spark MLLib
神经网络模型 每个node包含两种操作:线性变换(仿射变换)和激发函数(activation function). 其中仿射变换是通用的,而激发函数可以很多种,如下图. MLLib中实现ANN 使用两 ...
- openvSwitch tunnel
ovs tunnel 实验拓扑 实验拓扑搭建基础脚本 #vbox虚拟机1 ip netns add left ip link add name veth1 type veth peer name sw ...