机器学习入门-文本数据-构造Tf-idf词袋模型(词频和逆文档频率) 1.TfidfVectorizer(构造tf-idf词袋模型)
TF-idf模型:TF表示的是词频:即这个词在一篇文档中出现的频率
idf表示的是逆文档频率, 即log(文档的个数/1+出现该词的文档个数) 可以看出出现该词的文档个数越小,表示这个词越稀有,在这篇文档中也是越重要的
TF-idf: 表示TF*idf, 即词频*逆文档频率
词袋模型不仅考虑了一个词的词频,同时考虑了这个词在整个语料库中的重要性
代码:
第一步:使用DataFrame格式处理数据,同时数组化数据
第二步:定义函数,进行分词和停用词的去除,并使用‘ ’连接去除停用词后的列表
第三步:使用np.vectorizer向量化函数,同时调用函数进行分词和停用词的去除
第四步:使用TfidfVectorizer函数,构造TF-idf的词袋模型
import pandas as pd
import numpy as np
import re
import nltk #pip install nltk corpus = ['The sky is blue and beautiful.',
'Love this blue and beautiful sky!',
'The quick brown fox jumps over the lazy dog.',
'The brown fox is quick and the blue dog is lazy!',
'The sky is very blue and the sky is very beautiful today',
'The dog is lazy but the brown fox is quick!'
] labels = ['weather', 'weather', 'animals', 'animals', 'weather', 'animals'] # 第一步:构建DataFrame格式数据
corpus = np.array(corpus)
corpus_df = pd.DataFrame({'Document': corpus, 'categoray': labels}) # 第二步:构建函数进行分词和停用词的去除
# 载入英文的停用词表
stopwords = nltk.corpus.stopwords.words('english')
# 建立词分割模型
cut_model = nltk.WordPunctTokenizer()
# 定义分词和停用词去除的函数
def Normalize_corpus(doc):
# 去除字符串中结尾的标点符号
doc = re.sub(r'[^a-zA-Z0-9\s]', '', string=doc)
# 是字符串变小写格式
doc = doc.lower()
# 去除字符串两边的空格
doc = doc.strip()
# 进行分词操作
tokens = cut_model.tokenize(doc)
# 使用停止用词表去除停用词
doc = [token for token in tokens if token not in stopwords]
# 将去除停用词后的字符串使用' '连接,为了接下来的词袋模型做准备
doc = ' '.join(doc) return doc # 第三步:向量化函数和调用函数
# 向量化函数,当输入一个列表时,列表里的数将被一个一个输入,最后返回也是一个个列表的输出
Normalize_corpus = np.vectorize(Normalize_corpus)
# 调用函数进行分词和去除停用词
corpus_norm = Normalize_corpus(corpus) # 第四步:使用TfidVectorizer进行TF-idf词袋模型的构建
from sklearn.feature_extraction.text import TfidfVectorizer Tf = TfidfVectorizer(use_idf=True)
Tf.fit(corpus_norm)
vocs = Tf.get_feature_names()
corpus_array = Tf.transform(corpus_norm).toarray()
corpus_norm_df = pd.DataFrame(corpus_array, columns=vocs)
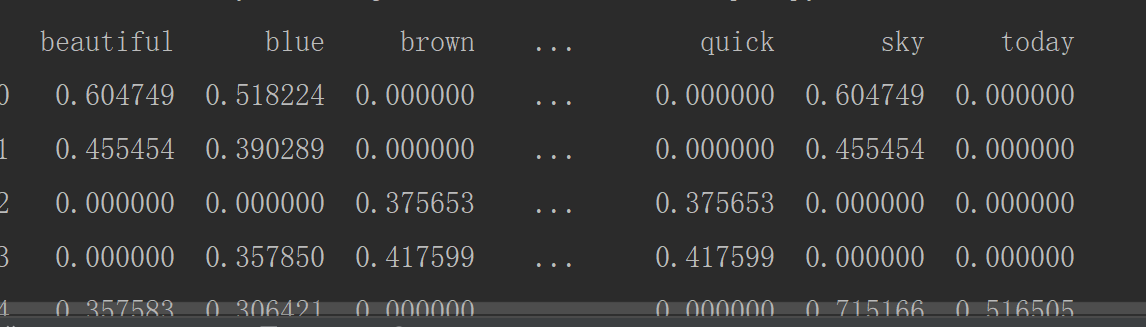
print(corpus_norm_df.head())
机器学习入门-文本数据-构造Tf-idf词袋模型(词频和逆文档频率) 1.TfidfVectorizer(构造tf-idf词袋模型)的更多相关文章
- 机器学习入门-文本数据-构造Ngram词袋模型 1.CountVectorizer(ngram_range) 构建Ngram词袋模型
函数说明: 1 CountVectorizer(ngram_range=(2, 2)) 进行字符串的前后组合,构造出新的词袋标签 参数说明:ngram_range=(2, 2) 表示选用2个词进行前后 ...
- 机器学习入门-文本数据-构造词频词袋模型 1.re.sub(进行字符串的替换) 2.nltk.corpus.stopwords.words(获得停用词表) 3.nltk.WordPunctTokenizer(对字符串进行分词操作) 4.np.vectorize(对函数进行向量化) 5. CountVectorizer(构建词频的词袋模型)
函数说明: 1. re.sub(r'[^a-zA-Z0-9\s]', repl='', sting=string) 用于进行字符串的替换,这里我们用来去除标点符号 参数说明:r'[^a-zA-Z0- ...
- 【Lucene3.6.2入门系列】第14节_SolrJ操作索引和搜索文档以及整合中文分词
package com.jadyer.solrj; import java.util.ArrayList; import java.util.List; import org.apache.solr. ...
- 请转发!简单2分钟制作无接触式小区进出微信登记表!全免费!数据安全!所有数据均存在创建人登录的QQ腾讯文档里!
全免费!数据安全!所有数据均存在创建人登录的QQ腾讯文档里! 阻击疫情到了最吃劲的关键期,大家能不出门就不出门,但免不了出去买个菜.取个快递啥的,每次出入的时候,社区同志都在认真拿着笔记录每个进出信息 ...
- 机器学习入门-文本特征-使用LDA主题模型构造标签 1.LatentDirichletAllocation(LDA用于构建主题模型) 2.LDA.components(输出各个词向量的权重值)
函数说明 1.LDA(n_topics, max_iters, random_state) 用于构建LDA主题模型,将文本分成不同的主题 参数说明:n_topics 表示分为多少个主题, max_i ...
- 机器学习入门-文本特征-word2vec词向量模型 1.word2vec(进行word2vec映射编码)2.model.wv['sky']输出这个词的向量映射 3.model.wv.index2vec(输出经过映射的词名称)
函数说明: 1. from gensim.model import word2vec 构建模型 word2vec(corpus_token, size=feature_size, min_count ...
- C#word(2007)操作类--新建文档、添加页眉页脚、设置格式、添加文本和超链接、添加图片、表格处理、文档格式转化
转:http://www.cnblogs.com/lantionzy/archive/2009/10/23/1588511.html 1.新建Word文档 #region 新建Word文档/// &l ...
- (大数据工程师学习路径)第二步 Vim编辑器----Vim文档编辑
一.vim重复命令 1.重复执行上次命令 在普通模式下.(小数点)表示重复上一次的命令操作 拷贝测试文件到本地目录 $ cp /etc/protocols . 打开文件进行编辑 $ vim proto ...
- 【机器学习】机器学习入门02 - 数据拆分与测试&算法评价与调整
0. 前情回顾 上一周的文章中,我们通过kNN算法了解了机器学习的一些基本概念.我们自己实现了简单的kNN算法,体会了其过程.这一周,让我们继续机器学习的探索. 1. 数据集的拆分 上次的kNN算法介 ...
随机推荐
- go学习day3
strings和strconv使用 1.strings.HasPrefix(s string, prefix string) bool:判断字符串s是否以prefix开头 2.strings.HasS ...
- Python实现简单的网页抓取
现在开源的网页抓取程序有很多,各种语言应有尽有. 这里分享一下Python从零开始的网页抓取过程 第一步:安装Python 点击下载适合的版本https://www.python.org/ 我这里选择 ...
- SSM的配置文件
Mybatis: SqlMapConfig.xml,配置了数据源,连接池,事务,加载sql映射文件(pojo),sqlsessionFactory对象,配置到spring容器中,mapeer代理对象或 ...
- go语言学习--go中闭包
Go语言支持匿名函数,即函数可以像普通变量一样被传递或使用. 使用方法如下: package main import ( "fmt" ) func main() { var v f ...
- 一个简单的基于多进程实现并发的Socket程序
在单进程的socket的程序的基础上,实现多进程并发效果的思路具体是:在server端开启“链接循环”,每建立一次链接就生成一个Process对象进行server-client的互动,而client端 ...
- [UE4]裁剪 Clipping
Clipping裁剪,是每个UI都有的属性.一般是在容器UI上设置,对容器内的UI进行裁剪. 一.Clip to Bounds:裁剪到边界 二.Clip To Bounds - Without Int ...
- 采用boosting思想开发一个解决二分类样本不平衡的多估计器模型
# -*- coding: utf-8 -*- """ Created on Wed Oct 31 20:59:39 2018 脚本描述:采用boosting思想开发一个 ...
- TensorFlow安装教程(ubuntu 18.04)
此教程的硬件条件: 1.Nvidia GPU Geforce390及以上 2.Ubuntu 18.04操作系统 3.Anaconda工具包 如果python版本为3.7及以上,使用如下命令降级到3.6 ...
- (转)WebApi返回Json格式字符串
原文地址:https://www.cnblogs.com/elvinle/p/6252065.html WebApi返回json格式字符串, 在网上能找到好几种方法, 其中有三种普遍的方法, 但是感觉 ...
- DB通用类:Sqlite通用类库
Sqlite通用类库 using System; using System.Collections; using System.Collections.Generic; using System.IO ...