FTL没有映射管理,跟上班没有钱有什么区别
大家好,我是五月。
前言
FTL(Flash Translation Layer),即闪存转换层,是各种存储设备的核心算法,作用是将Host传下来的逻辑地址转换成物理地址,也就是映射。
可以说,地址映射是FTL最原始最基本的功能。

为什么需要映射
NAND Flash最大的问题就是不能像内存一样随意写入。
根据Flash的特性能知道,写入page之前需要先将所在的Block擦除。
按照这种准则,市面上出现的Flash根本不能使用,其一,性能会很差,瓶颈限制在块擦除上,其二,持续不断对同一Block擦除,会导致Block在短时间内磨损,很容易造成存储数据丢失。
映射的观念出来后,数据不会直愣愣的写入原来的page页/Block块,而是重新映射到新的page页/Block块中,按照这个思路引导,Flash中所有的存储空间都可以按照这种page/Block映射方式进行管理。
用户肉眼看到的,是连续的逻辑地址组成的空间,实际在Flash当中,一段数据的存储很有可能是不连续的。
映射种类
首先要知道,映射种类有仨:
1. 块映射
2. 页映射
3. 混合映射(块映射+页映射)
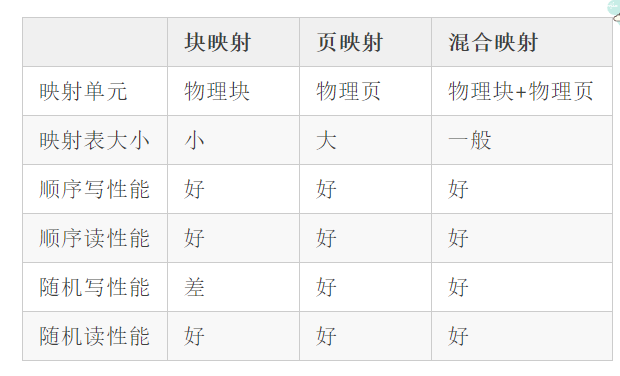
块映射
以Block为映射单位,一个逻辑块可以映射到任何的物理块上,所以块内每一页的偏移不变。
还需要映射表来记录逻辑块和物理块之间的映射关系。
优点:因为映射表只需要块的映射,所以映射表所占空间小。
缺点:性能差。如果用户要操作一个逻辑页的话,就需要把整个块的数据读取出来,再修改逻辑页,再写入flash当中,所以小尺寸数据写性能极差。
页映射
以page为映射粒度,一个逻辑页可以映射到任何的物理页上,所以块内每一页的偏移变化多端。
需要映射表来记录每一逻辑页与物理页之间的映射关系。
优点:用户可随时操作某一逻辑页,直接将数据写进对应物理页,方便快捷,性能极好。
缺点:由于每一逻辑页与物理页都有一张映射表,并且页的数量远远要比块的数量多得多,所以映射表所占空间极大。
用个例子就很好理解了:
假设有个256G的Flash,page大小为4KB,那么一共就有64M(256G/4KB)个page,也就是说需要64M个映射表,假设每个映射表占用4个字节,那么整个映射表大小就为64M*4 = 256M。
一般来说,整个映射表的大小不宜超过Flash容量的千分之一。
混合映射
混合映射是块映射和页映射的混合产物,外面经常说的Hybird level mapping就是说的它。
一个逻辑块可以映射到任何的物理块上,块内采用页映射方式,块内逻辑页可以映射到对应物理块内任何物理页上。
市面上大部分用的映射方式都是Hybird映射方式。
HyBird的映射操分为两级:
第一级是data_log,数据以page的维度写入log,这个log一般是SLC;
第一级是data_Block,当data_log写满后,数据会合并到data_Block中。
data_log由于数量有限,可以采用页映射的方式写入数据,data_Block容量比较大,所以采用块映射的方式写入。
所以在性能和所占空间都介于块映射和页映射之间。
以下是不同映射之间的比较:
映射原理
Host是通过发送逻辑地址 LBA 来访问Flash的,每一个LBA大小为 1Sec。
每一个Sec大小各有不同,有512B、4KB、8KB,业内常称为一包数据,大部分情况下都是512B。
因为PC端操作磁盘的方式,都是以Sec的方式发送命令的,操作其他存储设备比如U盘,SD卡也是一样,不会改变。
写过程
Flash是以page为单位进行写的,所以Host发送的 LAB+数据并不会立马就写进入,而是会先在Dbuf缓存起来,直到凑成了1page的数据量,才会写进Flash中。
用户每写入1page数据,FTL会先去找映射,看看LBA有没有对应的映射关系,如果没有找到,就会找一个物理页吧用户数据写入,同时新建一条映射。
那么,用户逻辑地址和物理地址的一条映射就生成了。
每写入一个逻辑页,就会有一条映射表产生或者更新。
读过程
用户读取某一个区域,发送LBA进行访问时,FTL就会先在映射表池里找呀找,找到与LBA对应的映射表,FTL就知道要在Flash的哪个物理页把数据读出来了。
如果读过程没有找到映射表,那么读取过程失败。
映射表位置
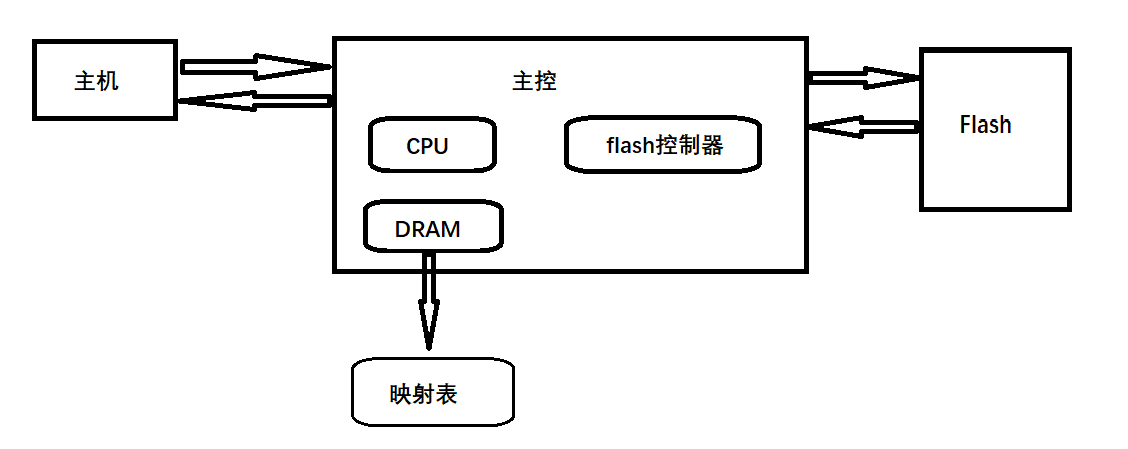
DRAM
大多数存储设备都有板载DRAM,映射表就能存储在DRAM上
作用:可以快速访问映射表,快速读写
缺点:随着映射表越来越多,所占DRAM就会越来越大,提高了成本和功耗。
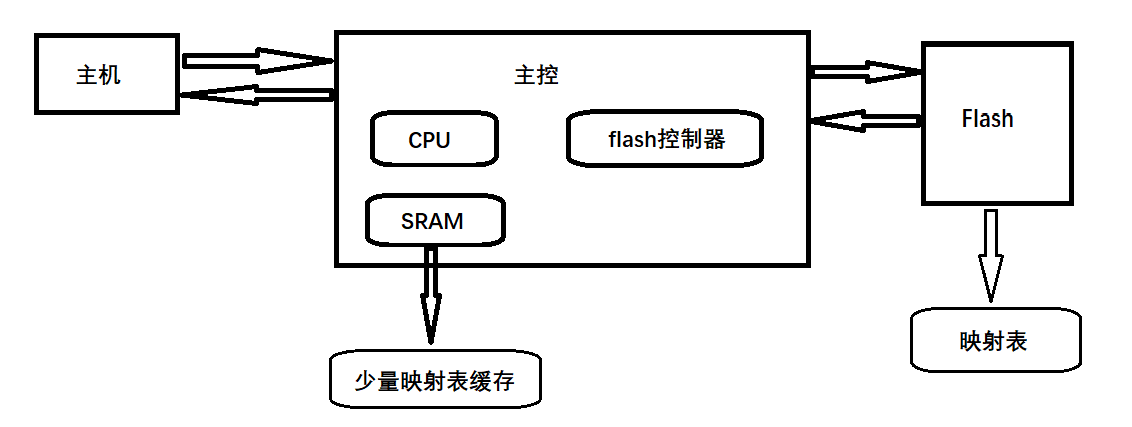
Flash
后来的主流是映射表大部分被存在于Flash中,当下要用的小部分映射表存于DRAM中。
作用:降低成本和功耗,还可以避免掉电带来的映射信息损失,另外Flash空间很大,映射表想放多少放多少。
Host发送LBA的时候,FTL会先在DRAM中寻找,如果没有找到对应的映射表,就会去Flash中读取映射表,再根据映射关系操作对应的物理页。
缺点:需要读取两次Flash,一次映射表,一次用户数据,底层带宽减小了,对于随机操作来说,就显得效率低了一点。
映射表更新
随着映射表的增加、删除、覆盖,到了某个时刻就要把映射表写进Flash保存起来,避免掉电时发生大量映射表丢失。
时不时将映射表写进Flash,就算发生了突然的异常掉电,丢失的也只是小部分映关系,后面还能通过重建映射表恢复回来。
映射表的写入时刻
1. 新生的映射表数量积累到一定的阈值
2. 用户写入的数据量积累到一定的阈值
3. 空闲闪存块的剩余数量达到一定的阈值
写入策略
1. 全部更新
将所有的映射表,无论是新产生的还是原先就有的,全部一股脑写入Flash中。
优点:固件实现简单,不用去考虑哪些映射表是新的,哪些是原本就有的。
缺点:写入数据量多,影响性能和延时,还会增加写入放大。
2. 增量更新
只把新产生的映射表写入Flash中。
优点:新增写入的数据量少,性能好,时效高。
缺点:固件实现复杂,还得区分那么那么些是新增的映射表,哪些是被覆盖的。
选择哪种写入决策,应根据硬件架构,结合实际情况考虑。
好了,这次先写到这儿,祝各位生活愉快。

FTL没有映射管理,跟上班没有钱有什么区别的更多相关文章
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 我有一个idea,但是没有钱,又没技术怎么办?
我想你还少讲一件事,就是同时如果你也没什么明确的商业计划,恭喜,那你有机会成为马云第二,因为他曾说过自己的成功要素就是「没钱」.「不懂技术」.「没有计划」,要是这么刚好让你从事互联网产业,我看不出三年 ...
- Es图形化软件使用之ElasticSearch-head、Kibana,Elasticsearch之-倒排索引操作、映射管理、文档增删改查
今日内容概要 ElasticSearch之-ElasticSearch-head ElasticSearch之-安装Kibana Elasticsearch之-倒排索引 Elasticsearch之- ...
- Linux内存管理机制中buffer和cache的区别
Linux内存管理机制中buffer和cache的区别理解linux内存管理,需要深入了解linux内存的各个参数含义和规则,下面介绍一下Linux操作系统中内存buffer和cache的区别. Fr ...
- es学习-映射管理
2.2.1 增加映射 url:http://192.168.0.108:9200/yingshe/_mapping/user/(前提 索引存在,如索引不存在 请按照上一篇创建索引添加映射) 参数: { ...
- 四十三 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字段的类型以及相关属性elasticsearch会根据json源数据的基础类型猜测你想要的字段映射,将输入的数据转换成可搜索的索引项, ...
- C#:CodeSmith根据数据库中的表创建C#数据模型Model + 因为没有钱买正版,所以附加自己写的小代码
对于C#面向对象的思想,我们习惯于将数据库中的表创建对应的数据模型: 但假如数据表很多时,我们手动增加模型类会显得很浪费时间: 这个时候有些人会用微软提供的EntityFrameWork,这个框架很强 ...
- Swift内存管理、weak和unowned以及两者区别
Swift 是自动管理内存的,这也就是说,我们不再需要操心内存的申请和分配.当我们通过初始化创建一个对象时,Swift 会替我们管理和分配内存.而释放的原则遵循了自动引用计数 (ARC) 的规则:当一 ...
- Swift内存管理、weak和unowned以及两者区别(如何使用Swift 中的weak与unowned?)
Swift 是自动管理内存的,这也就是说,我们不再需要操心内存的申请和分配. 当我们通过初始化创建一个对象时,Swift 会替我们管理和分配内存.而释放的原则遵循了自动引用计数 (ARC) 的规则:当 ...
- Flutter状态管理之provide和provider的使用区别
说道状态管理不得不说谷歌的亲自开发的两款状态管理Widget:第一个是provide,第二个是provider. 这两个的区别就是一个出来的早,现在好像没整么更新了.第二个是2019才出来的目前的版本 ...
随机推荐
- [Linux]CentOS查看RPM包依赖问题
[经典应用案例] 查看此文前,可先查看 此博文中:在安装软件过程中,如何解决的依赖组件问题? [数据库/Linux]CentOS7安装MySQL Percona版(RPM方式) : 2-1 依赖组件问 ...
- 在NodeJS中安装babel
安装babel 打开终端,输入命令:npm install --save-dev @babel/core @babel/cli @babel/preset-env @babel/node 安装完毕之后 ...
- 51nod 1153 选择子序列
51nod 选择子序列 这道题是\(Bunny\)学长在给我们的模拟赛中的一道题. 食用单调栈,处理每个数\(a_i\)左右第一个比自己大的数的下标\(left_i\),\(right_i\),并且建 ...
- Nvidia GPU虚拟化
1 背景 随着Nvidia GPU在渲染.编解码和计算领域发挥着越来越重要的作用,各大软件厂商对于Nvidia GPU的研究也越来越深入,尽管Nvidia倾向于生态闭源,但受制于极大的硬件成本压力,提 ...
- 10分钟极速入门dash应用开发
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/dash-master 大家好我是费老师,几天前我发布了由我开源维护的dash通用网页组件库fac的0 ...
- Longformer详解——从Self-Attention说开去
1.Longformer的应用场景 为了理解Longformer的原理,我们最好首先从为何需要使用Longformer开始说起.(这里默认各位已经对Self Attention等基础知识有一定的了解) ...
- node.js基于react项目打包部署到nginx中(Linux服务器)
1.首先进入React项目目录. 2.执行npm命令进行打包(生成dist包或build包). npm run build 3.将打包的静态文件放入nginx目录中(可以自己新创建一个目录,也可以放在 ...
- Tarjan学习笔寄
tarjan算法 参考博客: https://www.cnblogs.com/nullzx/p/7968110.html https://www.cnblogs.com/ljy-endl/p/1156 ...
- SSM之简单的CRUD
文章目录 前言 项目介绍 项目代码介绍 数据库文件 源码介绍 代码展示 配置文件 业务逻辑代码 总结 前言 大家好呀,前面不是说最近在学习SSM么,可能学的不是那么深,不过刚刚开始,学完肯定需要先动手 ...
- HTML中link标签的那些属性
在HTML中, link 标签是一个自闭合元素,通常位于文档的 head 部分.它用于建立与外部资源的关联,如样式表.图标等. link 标签具有多个属性,其中 rel 和 href 是最常用的. r ...