实现手写体 mnist 数据集的识别任务
实现手写体 mnist 数据集的识别任务,共分为三个模块文件,分别是描述网络结构的前向传播过程文件(mnist_forward.py)、 描述网络参数优化方法的反向传播 过 程 文件 ( mnist_backward.py )、
验证 模 型 准确 率 的 测试 过 程 文件(mnist_test.py)。
前向传播过程文件(mnist_forward.py) 在前向传播过程中,需要定义网络模型输入层个数、隐藏层节点数、输出层个数,定义网络参数 w、偏置 b,定义由输入到输出的神经网络架构。
实现手写体 mnist 数据集的识别任务前向传播过程如下:
#coding:utf-8
#1前向传播过程
import tensorflow as tf #网络输入节点为784个(代表每张输入图片的像素个数)
INPUT_NODE = 784
#输出节点为10个(表示输出为数字0-9的十分类)
OUTPUT_NODE = 10
#隐藏层节点500个
LAYER1_NODE = 500 def get_weight(shape, regularizer):
#参数满足截断正态分布,并使用正则化,
w = tf.Variable(tf.truncated_normal(shape,stddev=0.1))
#w = tf.Variable(tf.random_normal(shape,stddev=0.1))
#将每个参数的正则化损失加到总损失中
if regularizer != None: tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(regularizer)(w))
return w def get_bias(shape):
#初始化的一维数组,初始化值为全 0
b = tf.Variable(tf.zeros(shape))
return b def forward(x, regularizer):
#由输入层到隐藏层的参数w1形状为[784,500]
w1 = get_weight([INPUT_NODE, LAYER1_NODE], regularizer)
#由输入层到隐藏的偏置b1形状为长度500的一维数组,
b1 = get_bias([LAYER1_NODE])
#前向传播结构第一层为输入 x与参数 w1矩阵相乘加上偏置 b1 ,再经过relu函数 ,得到隐藏层输出 y1。
y1 = tf.nn.relu(tf.matmul(x, w1) + b1)
#由隐藏层到输出层的参数w2形状为[500,10]
w2 = get_weight([LAYER1_NODE, OUTPUT_NODE], regularizer)
#由隐藏层到输出的偏置b2形状为长度10的一维数组
b2 = get_bias([OUTPUT_NODE])
#前向传播结构第二层为隐藏输出 y1与参 数 w2 矩阵相乘加上偏置 矩阵相乘加上偏置 b2,得到输出 y。
#由于输出 。由于输出 y要经过softmax oftmax 函数,使其符合概率分布,故输出y不经过 relu函数
y = tf.matmul(y1, w2) + b2
return y
由上述代码可知,在前向传播过程中,规定网络输入结点为 784 个(代表每张输入图片的像素个数), 隐藏层节点 500 个,输出节点 10 个(表示输出为数字 0-9的十分类) 。由输入层到隐藏层的参数 w1 形状[784,500],由隐藏层到输出层的参数 w2 形状为[500,10],参数满足截断正态分布,并使用正则化,将每个参数的正则化损失加到总损失中。由输入层到隐藏层的偏置 b1 形状为长度为 500的一维数组,由隐藏层到输出层的偏置 b2 形状为长度为 10 的一维数组,初始化值为全 0。前向传播结构第一层为输入 x 与参数 w1 矩阵相乘加上偏置 b1,再经过 relu 函数,得到隐藏层输出 y1。前向传播结构第二层为隐藏层输出 y1 与参数 w2 矩阵相乘加上偏置 b2,得到输出 y。由于输出 y 要经过 softmax 函数,使其符合概率分布,故输出 y 不经过 relu 函数。
反向传播过程文件(mnist_backward.py)
反向传播过程实现利用训练数据集对神经网络模型训练,通过降低损失函数值,实现网络模型参数的优化,从而得到准确率高且泛化能力强的神经网络模型。实现手写体 mnist 数据集的识别任务反向传播过程如下:
#coding:utf-8
#2反向传播过程
#引入tensorflow、input_data、前向传播mnist_forward和os模块
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_forward
import os #每轮喂入神经网络的图片数
BATCH_SIZE = 200
#初始学习率
LEARNING_RATE_BASE = 0.1
#学习率衰减率
LEARNING_RATE_DECAY = 0.99
#正则化系数
REGULARIZER = 0.0001
#训练轮数
STEPS = 50000
#滑动平均衰减率
MOVING_AVERAGE_DECAY = 0.99
#模型保存路径
MODEL_SAVE_PATH="./model/"
#模型保存名称
MODEL_NAME="mnist_model" def backward(mnist):
#用placeholder给训练数据x和标签y_占位
x = tf.placeholder(tf.float32, [None, mnist_forward.INPUT_NODE])
y_ = tf.placeholder(tf.float32, [None, mnist_forward.OUTPUT_NODE])
#调用mnist_forward文件中的前向传播过程forword()函数,并设置正则化,计算训练数据集上的预测结果y
y = mnist_forward.forward(x, REGULARIZER)
#当前计算轮数计数器赋值,设定为不可训练类型
global_step = tf.Variable(0, trainable=False) #调用包含所有参数正则化损失的损失函数loss
ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cem = tf.reduce_mean(ce)
loss = cem + tf.add_n(tf.get_collection('losses'))
#设定指数衰减学习率learning_rate
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True) #使用梯度衰减算法对模型优化,降低损失函数
#train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
train_step = tf.train.MomentumOptimizer(learning_rate,0.9).minimize(loss, global_step=global_step)
#train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss, global_step=global_step)
#定义参数的滑动平均
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
ema_op = ema.apply(tf.trainable_variables())
#实例化可还原滑动平均的saver
#在模型训练时引入滑动平均可以使模型在测试数据上表现的更加健壮
with tf.control_dependencies([train_step,ema_op]):
train_op = tf.no_op(name='train') saver = tf.train.Saver() with tf.Session() as sess:
#所有参数初始化
init_op = tf.global_variables_initializer()
sess.run(init_op)
#每次喂入batch_size组(即200组)训练数据和对应标签,循环迭代steps轮
for i in range(STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
if i % 1000 == 0:
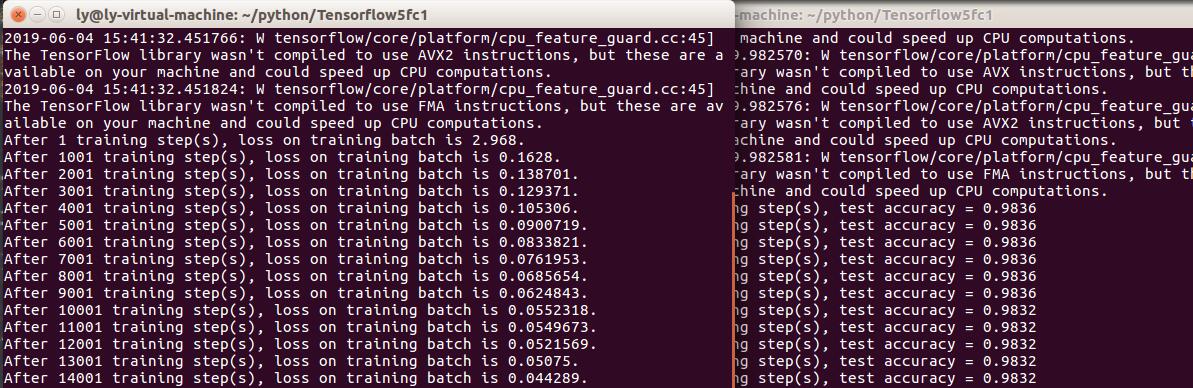
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
#将当前会话加载到指定路径
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step) def main():
#读入mnist
mnist = input_data.read_data_sets("./data/", one_hot=True)
#反向传播
backward(mnist) if __name__ == '__main__':
main()
由上述代码可知,在反向传播过程中,首先引入 tensorflow、input_data、前向传播 mnist_forward 和 os 模块,定义每轮喂入神经网络的图片数、初始学习率、学习率衰减率、正则化系数、训练轮数、模型保存路径以及模型保存名称等相关信息。在反向传播函数 backword 中,首先读入 mnist,用 placeholder 给训练数据 x 和标签 y_占位,调用 mnist_forward 文件中的前向传播过程 forword()函数,并设置正则化,计算训练数据集上的预测结果 y,并给当前计算轮数计数器赋值,设定为不可训练类型。接着,调用包含所有参数正则化损失的损失函数loss,并设定指数衰减学习率 learning_rate。然后,使用梯度衰减算法对模型优化,降低损失函数,并定义参数的滑动平均。最后,在 with 结构中,实现所有参数初始化,每次喂入 batch_size 组(即 200 组)训练数据和对应标签,循环迭代 steps 轮,并每隔 1000 轮打印出一次损失函数值信息,并将当前会话加载到指定路径。最后,通过主函数 main(),加载指定路径下的训练数据集,并调用规定的 backward()函数训练模型。
测试过程文件(mnist_test.py)
当训练完模型后,给神经网络模型输入测试集验证网络的准确性和泛化性。注意,所用的测试集和训练集是相互独立的。 实现手写体 mnist 数据集的识别任务测试传播过程如下
#coding:utf-8
#验证网络的准确性和泛化性
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_forward
import mnist_backward
#程序5秒的循环间隔时间
TEST_INTERVAL_SECS = 5 def test(mnist):
#利用tf.Graph()复现之前定义的计算图
with tf.Graph().as_default() as g:
#利用placeholder给训练数据x和标签y_占位
x = tf.placeholder(tf.float32, [None, mnist_forward.INPUT_NODE])
y_ = tf.placeholder(tf.float32, [None, mnist_forward.OUTPUT_NODE])
#调用mnist_forward文件中的前向传播过程forword()函数
y = mnist_forward.forward(x, None)
#实例化具有滑动平均的saver对象,从而在会话被加载时模型中的所有参数被赋值为各自的滑动平均值,增强模型的稳定性
ema = tf.train.ExponentialMovingAverage(mnist_backward.MOVING_AVERAGE_DECAY)
ema_restore = ema.variables_to_restore()
saver = tf.train.Saver(ema_restore)
#计算模型在测试集上的准确率
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) while True:
with tf.Session() as sess:
#加载指定路径下的ckpt
ckpt = tf.train.get_checkpoint_state(mnist_backward.MODEL_SAVE_PATH)
#若模型存在,则加载出模型到当前对话,在测试数据集上进行准确率验证,并打印出当前轮数下的准确率
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
accuracy_score = sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})
print("After %s training step(s), test accuracy = %g" % (global_step, accuracy_score))
#若模型不存在,则打印出模型不存在的提示,从而test()函数完成
else:
print('No checkpoint file found')
return
time.sleep(TEST_INTERVAL_SECS) def main():
#加载指定路径下的测试数据集
mnist = input_data.read_data_sets("./data/", one_hot=True)
test(mnist) if __name__ == '__main__':
main()
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./data/",one_hot=True)
print "train.labels[0]",mnist.train.labels[0]
print "test data size:",mnist.test.num_examples
print "validation data size:",mnist.validation.num_examples
print "train data size:",mnist.train.num_examples
print mnist.train.images[0]
在上述代码中,首先需要引入 time 模块、tensorflow、input_data、前向传播mnist_forward、反向传播 mnist_backward 模块和 os 模块,并规定程序 5 秒的循环间隔时间。接着,定义测试函数 test(),读入 mnist 数据集,利用 tf.Graph()复现之前定义的计算图,利用 placeholder 给训练数据 x 和标签 y_占位,调用mnist_forward 文件中的前向传播过程 forword()函数,计算训练数据集上的预测结果 y。接着,实例化具有滑动平均的 saver 对象,从而在会话被加载时模型中的所有参数被赋值为各自的滑动平均值,增强模型的稳定性,然后计算模型在测试集上的准确率。在 with 结构中,加载指定路径下的 ckpt,若模型存在,则加载出模型到当前对话,在测试数据集上进行准确率验证,并打印出当前轮数下的准确率,若模型不存在,则打印出模型不存在的提示,从而 test()函数完成。
通过主函数 main(),加载指定路径下的测试数据集,并调用规定的 test 函数,进行模型在测试集上的准确率验证。
运行以上三个文件,可得到手写体 mnist 数据集的识别任务的运行结果:
在此之前,在运行反向传播 mnist_backward 模块时,读取数据集时发现错误;可以选择下载已经下好的数据集;
百度网盘链接:
链接:https://pan.baidu.com/s/1oOnOIRTovIygCc1jn-8NJg
提取码:a2vm 
本文参考:
慕课APP中人工智能实践-Tensorflow笔记;北京大学曹健老师的课程
实现手写体 mnist 数据集的识别任务的更多相关文章
- mnist 数据集的识别源码解析
在基本跑完识别代码后,再来谈一谈自己对代码的理解: 1 前向传播过程文件(mnist_forward.py) 第一个函数get_weight(shape, regularizer); 定义了 ...
- tensorflow笔记(五)之MNIST手写识别系列二
tensorflow笔记(五)之MNIST手写识别系列二 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7455233.html ...
- Python实现bp神经网络识别MNIST数据集
title: "Python实现bp神经网络识别MNIST数据集" date: 2018-06-18T14:01:49+08:00 tags: [""] cat ...
- 一个简单的TensorFlow可视化MNIST数据集识别程序
下面是TensorFlow可视化MNIST数据集识别程序,可视化内容是,TensorFlow计算图,表(loss, 直方图, 标准差(stddev)) # -*- coding: utf-8 -*- ...
- RNN入门(一)识别MNIST数据集
RNN介绍 在读本文之前,读者应该对全连接神经网络(Fully Connected Neural Network, FCNN)和卷积神经网络( Convolutional Neural Netwo ...
- 卷积神经网络CNN识别MNIST数据集
这次我们将建立一个卷积神经网络,它可以把MNIST手写字符的识别准确率提升到99%,读者可能需要一些卷积神经网络的基础知识才能更好的理解本节的内容. 程序的开头是导入TensorFlow: impor ...
- Caffe系列4——基于Caffe的MNIST数据集训练与测试(手把手教你使用Lenet识别手写字体)
基于Caffe的MNIST数据集训练与测试 原创:转载请注明https://www.cnblogs.com/xiaoboge/p/10688926.html 摘要 在前面的博文中,我详细介绍了Caf ...
- SGD与Adam识别MNIST数据集
几种常见的优化函数比较:https://blog.csdn.net/w113691/article/details/82631097 ''' 基于Adam识别MNIST数据集 ''' import t ...
- 使用线性回归识别手写阿拉伯数字mnist数据集
学习了tensorflow的线性回归. 首先是一个sklearn中makeregression数据集,对其进行线性回归训练的例子.来自腾讯云实验室 import tensorflow as tf im ...
随机推荐
- JDK 动态代理的实现
JDK 动态代理的实现 虽然在常用的 Java 框架(Spring.MyBaits 等)中,经常见到 JDK 动态代理的使用,也知道了怎么去写一个 JDK 动态代理的 Demo,但是并不清楚实现原理. ...
- 翻转引起 cocos studio 引擎与cocos2d 代码相同坐标显示不同
使用setFlippedX后,又改变锚点为1.此时代码中坐标需要相对于cocos studio 中增加它本身的width,因为(0.5,0.5)是相对于自己中点的翻转,不变坐标.而(1,0.5)是相对 ...
- 原生JS数组操作的6个函数 arr.forEach arr.map arr.filter arr.some arr.every arr.findIndex
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- Linux下用Bash语言实现输出水仙花数的功能
题目链接: 题目描述 打印出所有"水仙花数",所谓"水仙花数"是指一个三位数,其各位数字立方和等于该本身. 例如:153是一个水仙花数,因为153=1^3+5^ ...
- Java期末考试冲刺总结
经过长达将近三个小时的冲刺,我感觉身心俱疲,但它无法掩盖我敲代码的欲望! 三个小时我只实现了公文流转系统的的部分功能. 我深刻的意识到建民老师说的这套关系之复杂,它真的是太复杂了!!!没有系统的梳理, ...
- mybatis一级缓存和二级缓存(一)
一级缓存: 就是Session级别的缓存.一个Session做了一个查询操作,它会把这个操作的结果放在一级缓存中. 如果短时间内这个session(一定要同一个session)又做了同一个操作,那么h ...
- Oracle忘记用户名和密码
Microsoft Windows [版本 10.0.16299.192](c) 2017 Microsoft Corporation.保留所有权利. C:\WINDOWS\system32>e ...
- 常用phpstorm快捷键
欢迎提交你经常使用的快捷键 ctrl+j 插入活动代码提示 ctrl+alt+t 当前位置插入环绕代码 alt+insert 生成代码菜单 ctrl+q 查看代码注释 ctrl+d 复制当前行 ctr ...
- 安装postman时遇到“无法定位程序输入点 SetDefaultDllDirectories于动态链接库KERNEL32.dll 上.”的问题
安装postman时遇到“无法定位程序输入点 SetDefaultDllDirectories于动态链接库KERNEL32.dll 上.”的问题 解决办法: 1.安装系统更新补丁KB2533623,下 ...
- 初识消息队列--ActiveMq
消息队列 即MessageQueue,是一种消息中间件,在遇到系统请求量比较大的情况下,导致请求堆积过多无法及时返回,可以通过它进行异步的消息处理,从而缓解系统压力. ActiveMq ActiveM ...