python爬虫:爬取猫眼TOP100榜的100部高分经典电影
1、问题描述:
爬取猫眼TOP100榜的100部高分经典电影,并将数据存储到CSV文件中
2、思路分析:
(1)目标网址:http://maoyan.com/board/4
(2)代码结构:

(3) init(self)初始化函数
· hearders用到了fake_useragent库,用来随机生成请求头。
· datas空列表,用于保存爬取的数据。
def __init__(self,url):
self.headers = {"User-Agent": UserAgent().random}
self.url = url
self.datas = list()
(4) getPage()函数
猫眼Top100榜总共有10页电影,每页的链接基本一样,只有最后一个数字在变化http://maoyan.com/board/4?offset=10,所以可以通过for循环来访问10页的电影。
# 通过for循环,获取10页的电影信息的源码
def getPage(self):
for i in range(0,10):
url = self.url + "?offset={0}".format(i*10)
response = requests.get(url, headers = self.headers)
if response.status_code == 200:
self.parsePage(response.text)
else:
return None
(5)parsePage()函数
每页都有10部高分经典电影,通过BeautifulSoup获取每页10部电影的详细信息:名字、主演、上映时间、评分。
# 通过BeautifulSoup获取每页10部电影的详细信息
def parsePage(self, html):
soup = BeautifulSoup(html, "html.parser")
details = soup.find_all("dd")
for dd in details:
data = {}
data["index"] = dd.find("i").text
data["name"] = dd.find("p", class_ = "name").text
data["star"] = dd.find("p", class_="star").text.strip()[3:]
data["time"] = dd.find("p", class_="releasetime").text.strip()[5:]
data["score"] = dd.find("p", class_="score").text
self.datas.append(data)
(6)savaData()函数
通过DataFrame(),把Top100的电影存储到CSV文件中。
它默认的是按照列名的字典顺序排序的。想要自定义列的顺序,可以加columns字段
# 通过DataFrame,把Top100的电影存储到CSV文件中
def saveData(self):
self.getPage()
data = pd.DataFrame(self.datas)
columns = ["index", "name", "star", "time", "score"]
data.to_csv(".\maoyanTop100.csv", index=False, columns=columns)
3、效果展示
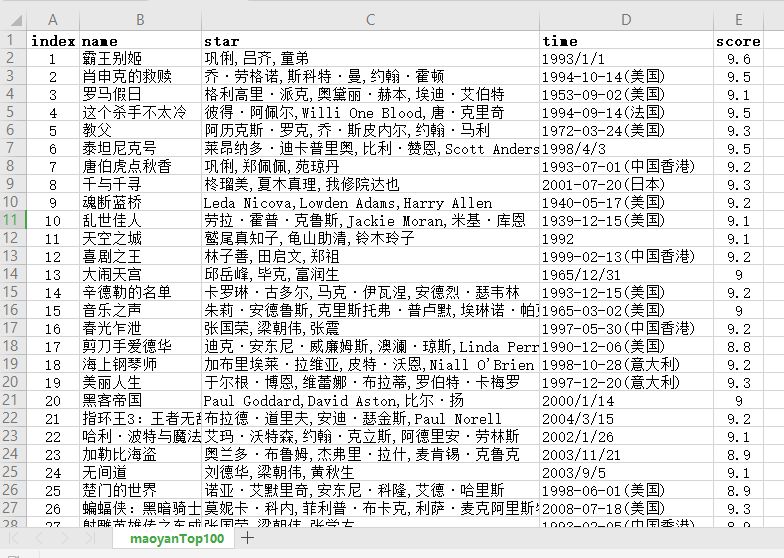
4、完整代码:
# -* conding: utf-8 *-
#author: wangshx6
#data: 2018-11-08
#description: 爬取猫眼TOP100榜的100部高分经典电影
import requests
from bs4 import BeautifulSoup
import pandas as pd
from fake_useragent import UserAgent
class MaoyanSpider(object):
def __init__(self,url):
self.headers = {"User-Agent": UserAgent().random}
self.url = url
self.datas = list()
# 通过for循环,获取10页的电影信息的源码
def getPage(self):
for i in range(0,10):
url = self.url + "?offset={0}".format(i*10)
response = requests.get(url, headers = self.headers)
if response.status_code == 200:
self.parsePage(response.text)
else:
return None
# 通过BeautifulSoup获取每页10部电影的详细信息
def parsePage(self, html):
soup = BeautifulSoup(html, "html.parser")
details = soup.find_all("dd")
for dd in details:
data = {}
data["index"] = dd.find("i").text
data["name"] = dd.find("p", class_ = "name").text
data["star"] = dd.find("p", class_="star").text.strip()[3:]
data["time"] = dd.find("p", class_="releasetime").text.strip()[5:]
data["score"] = dd.find("p", class_="score").text
self.datas.append(data)
# 通过DataFrame,把Top100的电影存储到CSV文件中
def saveData(self):
self.getPage()
data = pd.DataFrame(self.datas)
columns = ["index", "name", "star", "time", "score"]
data.to_csv(".\maoyanTop100.csv", index=False, columns=columns)
if __name__ == "__main__":
url = "http://maoyan.com/board/4"
spider = MaoyanSpider(url)
spider.saveData()
python爬虫:爬取猫眼TOP100榜的100部高分经典电影的更多相关文章
- 【爬虫】-爬取猫眼TOP100
原文崔庆才<python3网络爬虫实战> 本文为自学记录,如有侵权,请联系删除 目标: 熟悉正则表达式,以及爬虫流程 获取猫眼TOP100榜单 1.网站分析 目标站点为http://www ...
- Python 爬取 猫眼 top100 电影例子
一个Python 爬取猫眼top100的小栗子 import json import requests import re from multiprocessing import Pool #//进程 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
随机推荐
- JavaScript Hacks
JavaScript Hacks,很多都是在网上看到的,觉得好就记下来了.在这里给大家推荐一个项目,里面很多代码片段都值得学习https://github.com/Chalarangelo/30-se ...
- MarkDown 编辑器学习
MarkDown 编辑器学习 是一种简单快键的文字排版工具,可以用于编写说明文档,鉴于其语法简洁明了,且其渲染生成的样式简单美观,很多开发者也用它来写博客,已被国内外很多流行博客平台所支持.生成的文件 ...
- canvas制作倒计时炫丽效果
<!DOCTYPE html> <head> <title>canvas倒计时</title> <style> .canvas{ displ ...
- 栅格那点儿事(四E)
栅格金字塔 如果上面的部分都已经看过了,那么如何在ArcMap中更好的渲染一个栅格数据你已经知道了.可仅展示好一个栅格数据是不够的,我们还需要知道如何快速的展示一个栅格数据. 讲金字塔之前,先解释 ...
- Android基础Activity篇——Intent返回数据给上一个活动
1.如果活动B要将数据返回给活动A,那么需要以下三步: 1.1在活动A中使用startActivityForResult()方法启动活动B. 1.2在活动B中使用setResult()方法传回Iten ...
- python-rrdtool
https://nagios-plugins.org/doc/guidelines.html nagios检测信息 host GPING OK – rtt min/avg/max/mdev = 0.8 ...
- Eclipse: 导入项目乱码问题解决
1.编码不对 a.对某文件或某工程更改编码: 鼠标移到工程名或文件名,右键->Properties->Resource->Text file enCoding ->更改编码(G ...
- COGS 146. [USACO Jan08] 贝茜的晨练计划
★☆ 输入文件:cowrun.in 输出文件:cowrun.out 简单对比时间限制:1 s 内存限制:32 MB 奶牛们打算通过锻炼来培养自己的运动细胞,作为其中的一员,贝茜选择的运 ...
- TP5.1:模板赋值与变量输出
模板赋值:assign() 模板渲染:fetch() 前提准备: 1.在app/index/controller下建立一个控制器,名为Templates.php,里面有test1和test2方法,并且 ...
- leetcode: 链表2
1. copy-list-with-random-pointer(拷贝一个带随机指针的链表) A linked list is given such that each node contains a ...