机器学习:SVM(非线性数据分类:SVM中使用多项式特征和核函数SVC)
一、基础理解
- 数据:线性数据、非线性数据;
- 线性数据:线性相关、非线性相关;(非线性相关的数据不一定是非线性数据)
1)SVM 解决非线性数据分类的方法
方法一:
- 多项式思维:扩充原本的数据,制造新的多项式特征;(对每一个样本添加多项式特征)
- 步骤:
- PolynomialFeatures(degree = degree):扩充原始数据,生成多项式特征;
- StandardScaler():标准化处理扩充后的数据;
- LinearSVC(C = C):使用 SVM 算法训练模型;
方法二:
- 使用scikit-learn 中封装好的核函数: SVC(kernel='poly', degree=degree, C=C)
- 功能:当 SVC() 的参数 kernel = ‘poly’ 时,直接使用多项式特征处理数据;
- 注:使用 SVC() 前,也需要对数据进行标准化处理
二、例
1)生成数据
- datasets.make_ + 后缀:自动生成数据集;
- 如果想修改生成的数据量,可在make_moons()中填入参数;
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets X, y = datasets.make_moons(noise=0.15, random_state=666)
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()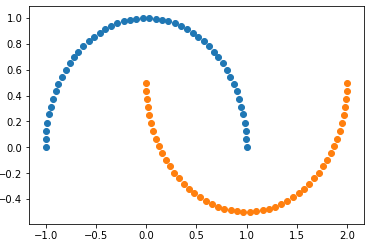
2)绘图函数
def plot_decision_boundary(model, axis): x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape) from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9']) plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
3)方法一:多项式思维
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline def PolynomialSVC(degree, C=1.0):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std)scaler', StandardScaler()),
('linearSVC', LinearSVC(C=C))
]) poly_svc = PolynomialSVC(degree=3)
poly_svc.fit(X, y) plot_decision_boundary(poly_svc, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()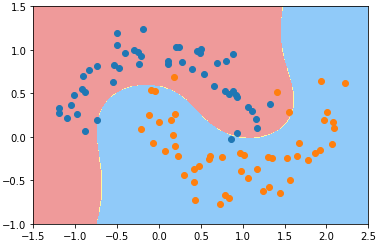
- 改变参数:degree、C,模型的决策边界也跟着改变;
4)方法二:使用核函数 SVC()
- 对于SVM算法,在scikit-learn的封装中,可以不使用 PolynomialFeatures的方式先将数据转化为高维的具有多项式特征的数据,在将数据提供给算法;
- SVC() 算法:直接使用多项式特征;
from sklearn.svm import SVC # 当算法SVC()的参数 kernel='poly'时,SVC()能直接打到一种多项式特征的效果;
# 使用 SVC() 前,也需要对数据进行标准化处理
def PolynomialKernelSVC(degree, C=1.0):
return Pipeline([
('std_scaler', StandardScaler()),
('kernelSVC', SVC(kernel='poly', degree=degree, C=C))
]) poly_kernel_svc = PolynomialKernelSVC(degree=3)
poly_kernel_svc.fit(X, y) plot_decision_boundary(poly_kernel_svc, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()
- 调整 PolynomialkernelSVC() 的参数:degree、C,可改决策边界;
机器学习:SVM(非线性数据分类:SVM中使用多项式特征和核函数SVC)的更多相关文章
- 【笔记】sklearn中的SVM以及使用多项式特征以及核函数
sklearn中的SVM以及使用多项式特征以及核函数 sklearn中的SVM的使用 SVM的理论部分 需要注意的是,使用SVM算法,和KNN算法一样,都是需要做数据标准化的处理才可以,因为不同尺度的 ...
- 【笔记】逻辑回归中使用多项式(sklearn)
在逻辑回归中使用多项式特征以及在sklearn中使用逻辑回归并添加多项式 在逻辑回归中使用多项式特征 在上面提到的直线划分中,很明显有个问题,当样本并没有很好地遵循直线划分(非线性分布)的时候,其预测 ...
- 吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 在opencv3中实现机器学习之:利用svm(支持向量机)分类
svm分类算法在opencv3中有了很大的变动,取消了CvSVMParams这个类,因此在参数设定上会有些改变. opencv中的svm分类代码,来源于libsvm. #include "s ...
- 机器学习经典算法之SVM
SVM 的英文叫 Support Vector Machine,中文名为支持向量机.它是常见的一种分类方法,在机器学习中,SVM 是有监督的学习模型. 什么是有监督的学习模型呢?它指的是我们需要事先对 ...
- 【机器学习具体解释】SVM解二分类,多分类,及后验概率输出
转载请注明出处:http://blog.csdn.net/luoshixian099/article/details/51073885 CSDN−勿在浮沙筑高台 支持向量机(Support Vecto ...
- 机器学习笔记——支持向量机 (SVM)
声明: 机器学习系列主要记录自己学习机器学习算法过程中的一些参考和总结,其中有部分内容是借鉴参考书籍和参考博客的. 目录: 什么支持向量机(SVM) SVM中必须知道的概念 SVM实现过程 SVM核心 ...
- 【机器学习】支持向量机(SVM)
感谢中国人民大学胡鹤老师,课程深入浅出,非常好 关于SVM 可以做线性分类.非线性分类.线性回归等,相比逻辑回归.线性回归.决策树等模型(非神经网络)功效最好 传统线性分类:选出两堆数据的质心,并做中 ...
- 基于SVM的数据分类预測——意大利葡萄酒种类识别
update:把程序源代码和数据集也附上http://download.csdn.net/detail/zjccoder/8832699 2015.6.24 --------------------- ...
随机推荐
- Windows系统 PHPstudy Apache无法启动的解决办法
最近在配置phpstudy的时候,出现是phpstudy apache无法启动的情况,其实也不是一点也不能启动,而且apache的启动状态亮一下就自动关闭了. 这样情况大部分小伙伴应该都遇到过,以前看 ...
- 把已安装的wampserver移动到不同目录使用应注意的问题
很多时候需要把已安装的wampserver移动到不同目录使用,此时应注意几个问题: 1.修改D:\wamp64\bin\apache\apache2.4.9\conf目录下的httpd.conf文件( ...
- LeetCode——sum-root-to-leaf-numbers
Question Given a binary tree containing digits from0-9only, each root-to-leaf path could represent a ...
- UVA 11181 Probability|Given (离散概率)
题意:有n个人去商场,其中每个人都有一个打算买东西的概率P[i].问你最后r个人买了东西的情况下每个人买东西的概率 题解:一脸蒙蔽的题,之前的概率与之后的概率不一样??? 看了白书上的题解才知道了,其 ...
- web.xml里报错:Multiple annotations found at this line:
在web.xml 中添加错误页面配置,出现了这个报错 具体情况是这样的: 错误信息: Multiple annotations found at this line: - cvc-complex-ty ...
- UvaLive 5811 概率DP
题意 : 有54张牌 问抽多少张牌能使每种花色都至少是给定的数字 两张王牌可以被选择为任何花色 高放学长真是太腻害辣! 设置dp[][][][][x][y] 前四维代表四种真的花色的数量 后两维xy代 ...
- Qt中使用setStyleSheet对QPushButton按钮进行外观设置
Qt中使用setStyleSheet对按钮进行外观设置 字体颜色的设置一般时以下两种方案: (1)属于QWidget子类的一些控件 可以直接使用样式表,例如label->setStyleShee ...
- 初识Django---视图
MTV模型 一.Django的MTV分别代表: Model(模型):负责业务对象与数据库的对象 Template(模板):负责如何把页面展示给用户 View(视图 ...
- DH02-策略模式
模式简介 面向对象的编程,并不是类越多越好,类的划分是为了封装,但分类的基础是抽象,具有相同属性和功能的对象的抽象集合才是类. 策略模式(Strategy)定义了算法家族,分别封装起来,让他们相互间可 ...
- poj2135最小费用流
裸题,就是存个模板 最小费用流是用spfa求解的,目的是方便求解负环,spfa类似于最大流中的bfs过程 #include<map> #include<set> #includ ...