spark-groupByKey
一般来说,在执行shuffle类的算子的时候,比如groupByKey、reduceByKey、join等。 其实算子内部都会隐式地创建几个RDD出来。那些隐式创建的RDD,主要是作为这个操作的一些中间数据的表达,以及作为stage划分的边界。 因为有些隐式生成的RDD,可能是ShuffledRDD,dependency就是ShuffleDependency,DAGScheduler的源码,就会将这个RDD作为新的stage的第一个rdd,划分出来。
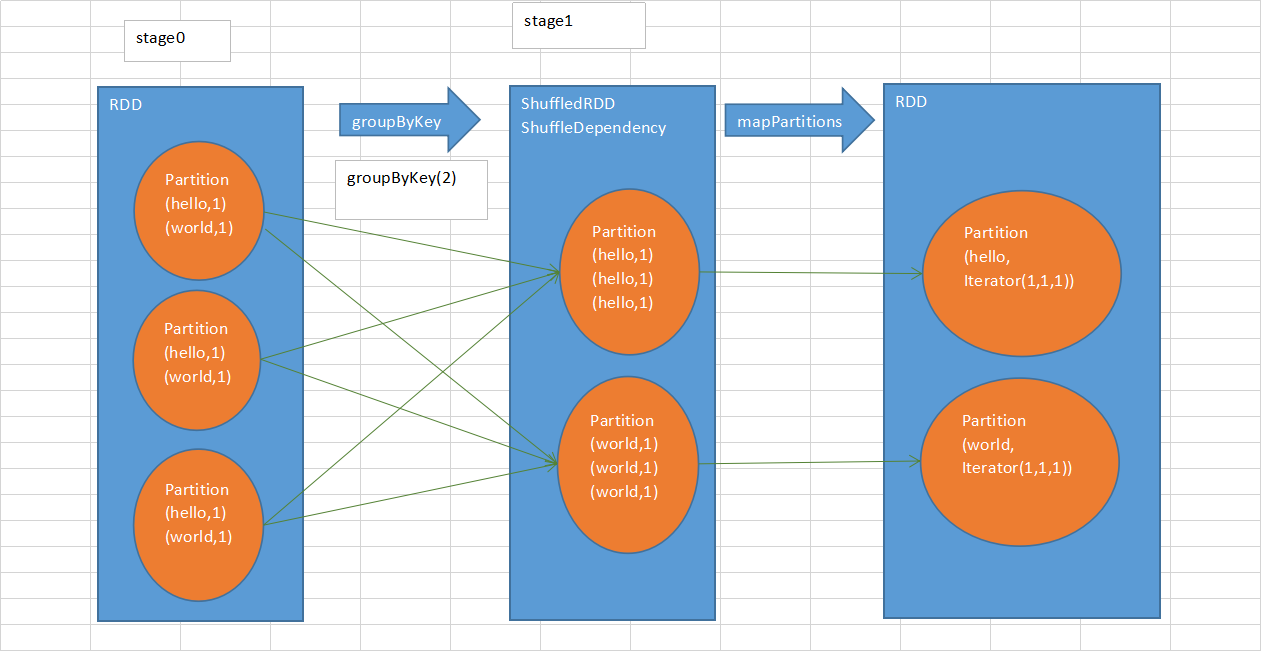
groupByKey等shuffle算子,都会创建一些隐式RDD。比如说这里,ShuffledRDD,作为一个shuffle过程中的中间数据的代表。 依赖这个ShuffledRDD创建出来一个新的stage(stage1)。ShuffledRDD会去触发shuffle read操作。从上游stage的task所在节点,拉取过来相同的key,做进一步的聚合。 对ShuffledRDD中的数据执行一个map类的操作,主要是对每个partition中的数据,都进行一个映射和聚合。这里主要是将每个key对应的数据都聚合到一个Iterator集合中。
spark-groupByKey的更多相关文章
- spark groupByKey().mapValues
>>> rdd = sc.parallelize([("bone", 231), ("bone", 21213), ("jack&q ...
- spark groupByKey 也是可以filter的
>>> v=sc.parallelize(["one", "two", "two", "three", ...
- 【Spark调优】:如果实在要shuffle,使用map侧预聚合的算子
因业务上的需要,无可避免的一些运算一定要使用shuffle操作,无法用map类的算子来替代,那么尽量使用可以map侧预聚合的算子. map侧预聚合,是指在每个节点本地对相同的key进行一次聚合操作,类 ...
- Spark程序使用groupByKey后数据存入HBase出现重复的现象
最近在一个项目中做数据的分类存储,在spark中使用groupByKey后存入HBase,发现数据出现双份( 所有记录的 rowKey 是随机 唯一的 ) .经过不断的测试,发现是spark的运行参 ...
- (九)groupByKey,reduceByKey,sortByKey算子-Java&Python版Spark
groupByKey,reduceByKey,sortByKey算子 视频教程: 1.优酷 2. YouTube 1.groupByKey groupByKey是对每个key进行合并操作,但只生成一个 ...
- Spark RDD/Core 编程 API入门系列 之rdd案例(map、filter、flatMap、groupByKey、reduceByKey、join、cogroupy等)(四)
声明: 大数据中,最重要的算子操作是:join !!! 典型的transformation和action val nums = sc.parallelize(1 to 10) //根据集合创建RDD ...
- Spark RDD/Core 编程 API入门系列之map、filter、textFile、cache、对Job输出结果进行升和降序、union、groupByKey、join、reduce、lookup(一)
1.以本地模式实战map和filter 2.以集群模式实战textFile和cache 3.对Job输出结果进行升和降序 4.union 5.groupByKey 6.join 7.reduce 8. ...
- spark中groupByKey与reducByKey
[译]避免使用GroupByKey Scala Spark 技术 by:leotse 原文:Avoid GroupByKey 译文 让我们来看两个wordcount的例子,一个使用了reduceB ...
- Spark DataFrame的groupBy vs groupByKey
在使用Spark SQL的过程中,经常会用到groupBy这个函数进行一些统计工作.但是会发现除了groupBy外,还有一个groupByKey(注意RDD也有一个groupByKey,而这里的gro ...
- spark RDD,reduceByKey vs groupByKey
Spark中有两个类似的api,分别是reduceByKey和groupByKey.这两个的功能类似,但底层实现却有些不同,那么为什么要这样设计呢?我们来从源码的角度分析一下. 先看两者的调用顺序(都 ...
随机推荐
- python基础实践(四)
# -*- coding:utf-8 -*-# Author:sweeping-monkwhy = "为什么要组织列表?"print(why)Chicken_soup = &quo ...
- Ubuntu系列问题
一.Ubuntu16.04 intel_rapl : no valid rapl domains found in packge0 echo 'blacklist intel_rapl' >&g ...
- ssh-centos74.sh
#!/bin/bash sed -i 's/#PermitRootLogin yes/PermitRootLogin yes/g' /etc/ssh/sshd_config sed -i 's/#Us ...
- cloud.cfg_for_ubuntu
user: default disable_root: false preserve_hostname: false cloud_init_modules: - bootcmd - resizefs ...
- OpenFlow-Enaling innvation in Campus Networks
OpenFlow-Enaling innvation in Campus Networks 出现问题 背景 Networks have become part of the critical infr ...
- (总结)Nginx使用的php-fpm的两种进程管理方式及优化
PS:前段时间配置php-fpm的时候,无意中发现原来它还有两种进程管理方式.与Apache类似,它的进程数也是可以根据设置分为动态和静态的. php-fpm目前主要又两个分支,分别对应于php-5. ...
- 安装JDK以及配置Java运行环境
安装JDK以及配置Java运行环境 1.JDK下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2 ...
- [洛谷P4656][CEOI2017]Palindromic Partitions
题目大意:一个长度为$n$的字符串,要求把它分成尽可能多的小块,使得这些块构成回文串 题解:贪心,从两边从找尽可能小的块使得左右的块相等,判断相等可以用$hash$ 卡点:无 C++ Code: #i ...
- freemarker的简单入门程序
本文主要介绍了freemarker的常用标签<#list> <#import> <#assign> <#if> <#else> &l ...
- 解决PKIX path building failed
起因 上周在生产环境部署时,把安全证书加到k8s-ingress中时发现报该错误 解决 找网上解决方案,因为这种问题相对比较少见,也没百度,直接谷歌,找到解决方案如下:https://stackove ...