Linear Regression with PyTorch
Linear Regression with PyTorch
Problem Description
初始化一组数据 \((x,y)\),使其满足这样的线性关系 \(y = w x + b\) 。然后基于反向传播法,用均方误差(mean squared error)
\]
去拟合这组数据。
衡量两个分布之间的距离,最直接的方法是用交叉熵。
我们用最简单的一元变量去拟合这组数据,其实一元线性回归的表达式 \(y = wx + b\) 用神经网络的形式可表示成如下图所示
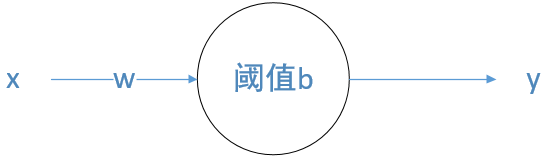
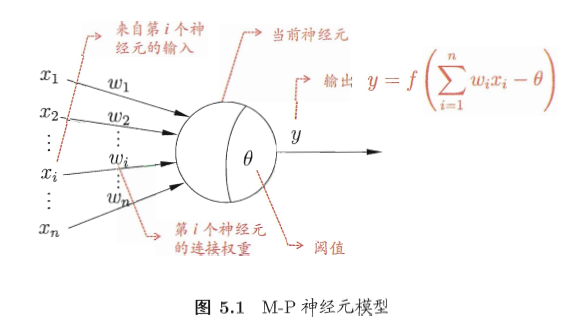
该神经网络有一个输入、一个输出、不使用任何激活函数。这就是一元线性回归的神经网络表示结果。相比较于下图这种神经网络的形式化表示,上图是一种简单的特例。
Key Points
torch.unsqueeze
重塑一个张量的 size,见下面代码
>>> x = torch.tensor([1, 2, 3, 4])
>>> torch.unsqueeze(x, 0)
tensor([[ 1, 2, 3, 4]])
>>> torch.unsqueeze(x, 1)
tensor([[ 1],
[ 2],
[ 3],
[ 4]])
torch.linspace
得到一个在 start 和 end 之间等距的一维张量,见下面代码
>>> torch.linspace(1, 6, steps=3)
tensor([ 1.0000, 3.5000, 6.0000])
torch.rand
返回一个满足 size 维度要求的随机数组,随机数服从0-1均匀分布。
torch.nn.Linear(1,1)
self.prediction = torch.nn.Linear(1, 1)
这一行代码,实际是维护了两个变量,其描述了这样的一种关系:
\]
其中,每个参数都是 \(1\times1\) 维的。
Code
import torch
epoch = 10000
lr = 0.01
w = 10
b = 5
x = torch.unsqueeze(torch.linspace(1, 10, 20), 1)
y = w*x + b + torch.rand(x.size())
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.prediction = torch.nn.Linear(1, 1)
def forward(self, x):
out = self.prediction(x)
return out
net = Net()
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
criticism = torch.nn.MSELoss()
for i in range(epoch):
y_pred = net(x)
loss = criticism(y_pred, y) # 先是 y_pred 然后是 y_true 参数顺序不能乱
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("%.5f" % loss.data)
print(net.state_dict()['prediction.weight'])
print(net.state_dict()['prediction.bias'])
输出:
0.08882
tensor([[ 9.9713]])
tensor([ 5.6524])
Results Analysis
输出显示:
- 均方误差(MSE)为 0.0882
- \(weight\) 的拟合结果为 9.9713
- \(bias\) 的拟合结果为 5.6524
分析:
- 因为我主动引入了误差(服从0-1均匀分布),而且是线性拟合,所以 MSE 几乎不能减小到零;
- 9.9713 的拟合值已经非常接近真实值 10 了;5.6524 的拟合值较真实值 5 的距离较大(距离约为自身的 10%)
Linear Regression with PyTorch的更多相关文章
- 线性回归、梯度下降(Linear Regression、Gradient Descent)
转载请注明出自BYRans博客:http://www.cnblogs.com/BYRans/ 实例 首先举个例子,假设我们有一个二手房交易记录的数据集,已知房屋面积.卧室数量和房屋的交易价格,如下表: ...
- 局部加权回归、欠拟合、过拟合(Locally Weighted Linear Regression、Underfitting、Overfitting)
欠拟合.过拟合 如下图中三个拟合模型.第一个是一个线性模型,对训练数据拟合不够好,损失函数取值较大.如图中第二个模型,如果我们在线性模型上加一个新特征项,拟合结果就会好一些.图中第三个是一个包含5阶多 ...
- Multivariance Linear Regression练习
%% 方法一:梯度下降法 x = load('E:\workstation\data\ex3x.dat'); y = load('E:\workstation\data\ex3y.dat'); x = ...
- Kernel Methods (3) Kernel Linear Regression
Linear Regression 线性回归应该算得上是最简单的一种机器学习算法了吧. 它的问题定义为: 给定训练数据集\(D\), 由\(m\)个二元组\(x_i, y_i\)组成, 其中: \(x ...
- Linear regression with multiple variables(多特征的线型回归)算法实例_梯度下降解法(Gradient DesentMulti)以及正规方程解法(Normal Equation)
,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, , ...
- Linear regression with one variable算法实例讲解(绘制图像,cost_Function ,Gradient Desent, 拟合曲线, 轮廓图绘制)_矩阵操作
%测试数据 'ex1data1.txt', 第一列为 population of City in 10,000s, 第二列为 Profit in $10,000s 1 6.1101,17.592 5. ...
- Matlab实现线性回归和逻辑回归: Linear Regression & Logistic Regression
原文:http://blog.csdn.net/abcjennifer/article/details/7732417 本文为Maching Learning 栏目补充内容,为上几章中所提到单参数线性 ...
- Stanford机器学习---第二讲. 多变量线性回归 Linear Regression with multiple variable
原文:http://blog.csdn.net/abcjennifer/article/details/7700772 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- Stanford机器学习---第一讲. Linear Regression with one variable
原文:http://blog.csdn.net/abcjennifer/article/details/7691571 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
随机推荐
- 一个简单的sel server 函数的自定义
创建自定义函数:use 数据库名gocreate function 函数名(@pno int)returns intasbegin declare @a int if not exists(se ...
- 函数 return
return 的作用 一.返回一个值给函数,主函数调用这个函数后能得到这个返回的值.二.结束函数,例如你运行到一个地方,虽然后面还有代码但是你不想再继续运行,这时就可以直接用 return:这条语句来 ...
- python SMTP
一.一开始,相信SMTP服务,所以在本机安装了一个 apt-get install sendmail apt-get install sendmail-cf apt-get install squir ...
- python list成员函数extend与append的区别
extend 原文解释,是以list中元素形式加入到列表中 extend list by appending elements from the iterable append(obj) 是将整个ob ...
- js重定向跳转页面
重定向方式: 1> window.location ='www.baidu.com'; window.location='/'; window.location='/logout/'; ...
- 答案在哪里?action config/Interceptor/class/servlet
项目已提测,这两天我们都集中精力梳理外包团队给我司研发的这个三方支付系统的代码逻辑.今天下午爱琴海会议室,开发组里一同学分享他对支付结果回调的梳理成果. 支付结果回调的整体时序是:支付渠道方处理完用户 ...
- 让bat以管理员权限运行
有的电脑是非管理员登录,运行程序时,需要提示是否运行运行.解决方法如下: @ echo off % % ver|find "5.">nul&&goto :Ad ...
- C#6.0中10大新特性的应用和总结
微软发布C#6.0.VS2015等系列产品也有一段时间了,但是网上的教程却不多,这里真对C#6.0给大家做了一些示例,分享给大家. 微软于2015年7月21日发布了Visual Studio 20 ...
- mysqladmin -u root password
ERROR : Error appeared during Puppet run: 192.77.108.242_mysql.ppError: mysqladmin -u root password ...
- 缓存 Memached
https://github.com/enyim/EnyimMemcached http://www.newasp.net/soft/63735.html#downloaded/ http://blo ...