使用Flame Graph进行系统性能分析
关键词:Flame Graph、perf、perl。
FlameGraph是由BrendanGregg开发的一款开源可视化性能分析工具,形象的成为火焰图。
从底向上像火苗一样逐渐变小,也反映了相互之间的包含关系,下面的框条包含上面内容。
经过FlameGraph.git处理,最终生成矢量SVG图形,可以形象的看出不同部分占用情况,以及包含与被包含情况。
除了反应CPU使用情况的CPU FlameGraph,还有几种Flame Graph:Memory Flame Graph、Off-CPU Flame Graph、Hot/Cold Flame Graph、Differential Flame Graph。
本文目的是记录如何使用Flame Graph;然后对其流程进行简单分析,了解其数据来龙去脉;最后分析测试结果。
基本上做到知其然知其所以然。
1. Flame Graph使用
构造测试程序如下,可以启动5个线程。
每个线程都有自己的thread_funcx(),while(1)里面再调用函数。
在8核CPU上执行,预测应该每个thread_funcx()都会占用相同的比例,因为都是100%占用CPU,然后里面的函数比例呈现阶梯形。
#include <stdio.h>
#include <pthread.h> #define LOOP_COUNT 1000000 void func_a(void)
{
int i;
for(i=; i<LOOP_COUNT; i++);
} void func_b(void)
{
int i;
for(i=; i<LOOP_COUNT; i++);
func_a();
} void func_c(void)
{
int i;
for(i=; i<LOOP_COUNT; i++);
func_b();
} void func_d(void)
{
int i;
for(i=; i<LOOP_COUNT; i++);
func_c();
} void func_e(void)
{
int i;
for(i=; i<LOOP_COUNT; i++);
func_d();
} void* thread_fun1(void* param)
{
while() {
int i;
for(i=;i<LOOP_COUNT;i++);
func_a();
}
} void* thread_fun2(void* param)
{
while() {
int i;
for(i=;i<LOOP_COUNT;i++);
func_b();
}
} void* thread_fun3(void* param)
{
while() {
int i;
for(i=;i<LOOP_COUNT;i++);
func_c();
}
} void* thread_fun4(void* param)
{
while() {
int i;
for(i=;i<LOOP_COUNT;i++);
func_d();
}
} void* thread_fun5(void* param)
{
while() {
int i;
for(i=;i<LOOP_COUNT;i++);
func_e();
}
}
int main(void)
{
int ret;
pthread_t tid1, tid2, tid3, tid4, tid5; ret=pthread_create(&tid1, NULL, thread_fun1, NULL);
if(ret==-){
printf("Create pthread failed.\n");
return -;
} ret=pthread_create(&tid2, NULL, thread_fun2, NULL);
if(ret==-){
printf("Create pthread failed.\n");
return -;
} ret=pthread_create(&tid3, NULL, thread_fun3, NULL);
if(ret==-){
printf("Create pthread failed.\n");
return -;
} ret=pthread_create(&tid4, NULL, thread_fun4, NULL);
if(ret==-){
printf("Create pthread failed.\n");
return -;
} ret=pthread_create(&tid5, NULL, thread_fun5, NULL);
if(ret==-){
printf("Create pthread failed.\n");
return -;
} if(pthread_join(tid1,NULL)!=){
printf("pthrad join failed.\n");
return -;
} if(pthread_join(tid2,NULL)!=){
printf("pthrad join failed.\n");
return -;
} if(pthread_join(tid3,NULL)!=){
printf("pthrad join failed.\n");
return -;
}
if(pthread_join(tid4,NULL)!=){
printf("pthrad join failed.\n");
return -;
}
if(pthread_join(tid5,NULL)!=){
printf("pthrad join failed.\n");
return -;
} return ;
}
编译然后执行结果:
gcc createFlame.c -o createFlame -pthread
./createFlame
在sudo su权限中进行perf record和FlameGraph生成;-F 999采样率999Hz,-a包括所有CPU,-g使能call-graph录制,-- sleep 60记录60秒时长。
perf record -F -a -g -- sleep
perf script | ./stackcollapse-perf.pl | ./flamegraph.pl > out.svg
在浏览器中查看结果如下:
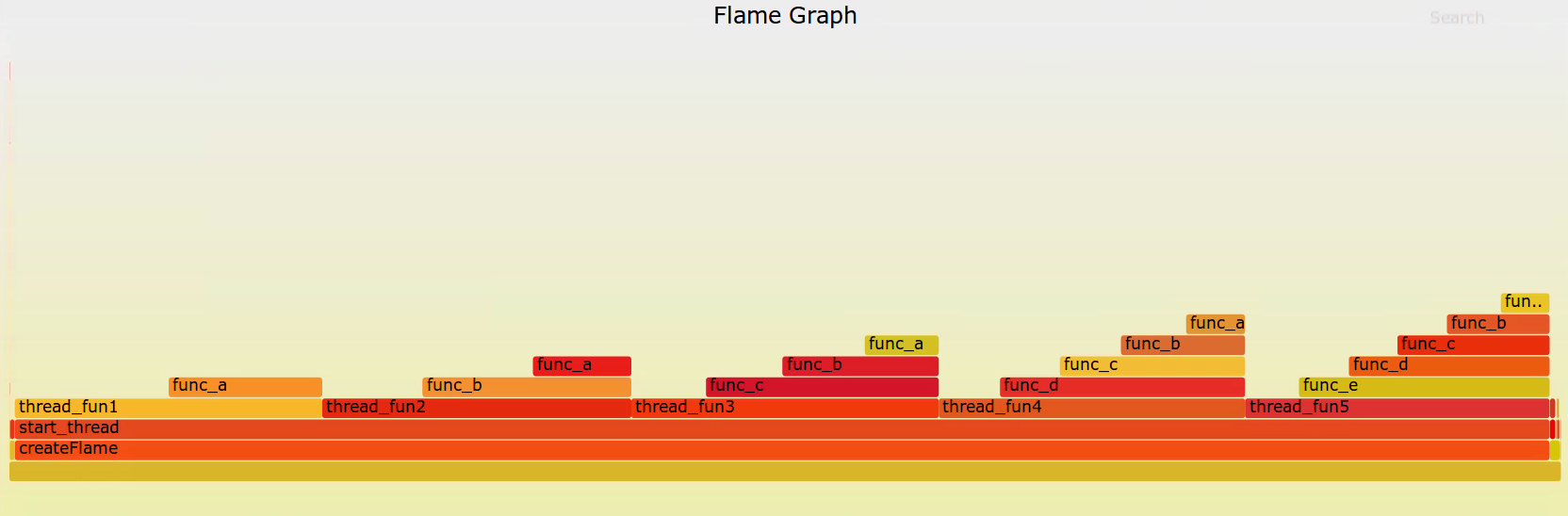
可以看出createFlame应用,调用start_thread创建线程,五个线程函数占用相等宽度。
线程函数以下的层级调用宽度相差基本一致。
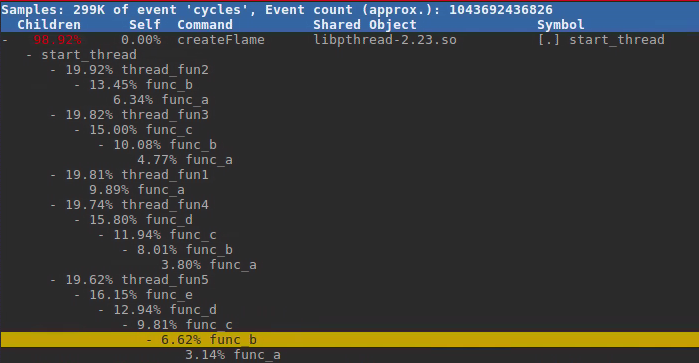
使用perf report -g查看start_thread,然后逐级展开调用及其占比。
整个start_thread占据99%,然后5个线程均分,因为每个都独占一个CPU。
每个线程里面函数占比,与FlameGraph中一致。
1.1 查看细节
鼠标移动到FlameGraph框图上时,会显示对应进程或函数的被采样信息。
如果点击框图,则以其为基础展开,放大显示后面的找关系。已达到缩放,显示细节和整体。
1.2 查找
在右上角Search或者Ctrl+F,可以在FlameGraph中查找相应符号的框图。
2. Flame Graph流程分析
从perf record输出的perf.data,到最终生成out.svg文件,可以分为三步:1.perf script、2.stackcollapse-perf.pl、3.flamegraph.pl。
如果要详细了解其如何一步一步解析字符串,到最终生成svg矢量图形可以阅读stackcollapse-perf.pl和flamegraph.pl两个perl脚本。
下面借助构造伪数据,来理解其流程。
2.1 perf script
perf script将perf record的记录转换成可读的采样记录,每一个下采样记录包含应用名称、以及采样到的stack信息。
进程名后的进程ID、CPU号、时间戳、cycles数目都是无用信息,下面的stack也只有函数名有效。
createFlame [] 0.0: cycles:
func_a (xxx)
func_b (xxx)
func_c (xxx)
func_d (xxx)
func_e (xxx)
thread_fun5 (xxx)
start_thread (xxx)
构造一份perf script生成的伪数据,来分析流程以及明白FlameGraph的含义。
createFlame [] 0.0: cycles:
thread_fun1 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
func_a (xxx)
thread_fun1 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
thread_fun2 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
func_b (xxx)
thread_fun2 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
func_a (xxx)
func_b (xxx)
thread_fun2 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
thread_fun3 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
func_c (xxx)
thread_fun3 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
func_b (xxx)
func_c (xxx)
thread_fun3 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
func_a (xxx)
func_b (xxx)
func_c (xxx)
thread_fun3 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
thread_fun4 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
func_d (xxx)
thread_fun4 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
func_c (xxx)
func_d (xxx)
thread_fun4 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
func_b (xxx)
func_c (xxx)
func_d (xxx)
thread_fun4 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
func_a (xxx)
func_b (xxx)
func_c (xxx)
func_d (xxx)
thread_fun4 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
thread_fun5 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
func_e (xxx)
thread_fun5 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
func_d (xxx)
func_e (xxx)
thread_fun5 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
func_c (xxx)
func_d (xxx)
func_e (xxx)
thread_fun5 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
func_b (xxx)
func_c (xxx)
func_d (xxx)
func_e (xxx)
thread_fun5 (xxx)
start_thread (xxx) createFlame [] 0.0: cycles:
func_a (xxx)
func_b (xxx)
func_c (xxx)
func_d (xxx)
func_e (xxx)
thread_fun5 (xxx)
start_thread (xxx)
2.2 stackcollapse-perf.pl
stackcollapse-perf.pl将perf script生成的多行stack记录转换成一行,函数之间用逗号隔开,最后的记录采样次数用空格隔开。
可以通过./stackcollapse-perf.pl -h查看帮助,查看cat perf_fake.txt | ./stackcollapse-perf.pl输出。
可以清晰地看出栈的关系和采样到的次数。
createFlame;start_thread;thread_fun1
createFlame;start_thread;thread_fun1;func_a
createFlame;start_thread;thread_fun2
createFlame;start_thread;thread_fun2;func_b
createFlame;start_thread;thread_fun2;func_b;func_a
createFlame;start_thread;thread_fun3
createFlame;start_thread;thread_fun3;func_c
createFlame;start_thread;thread_fun3;func_c;func_b
createFlame;start_thread;thread_fun3;func_c;func_b;func_a
createFlame;start_thread;thread_fun4
createFlame;start_thread;thread_fun4;func_d
createFlame;start_thread;thread_fun4;func_d;func_c
createFlame;start_thread;thread_fun4;func_d;func_c;func_b
createFlame;start_thread;thread_fun4;func_d;func_c;func_b;func_a
createFlame;start_thread;thread_fun5
createFlame;start_thread;thread_fun5;func_e
createFlame;start_thread;thread_fun5;func_e;func_d
createFlame;start_thread;thread_fun5;func_e;func_d;func_c
createFlame;start_thread;thread_fun5;func_e;func_d;func_c;func_b
createFlame;start_thread;thread_fun5;func_e;func_d;func_c;func_b;func_a
2.3 flamegraph.pl
那么stackcollapse-perf.pl的数据经过flamegraph.pl处理之后又是什么样子呢?
可以看出svg图形,就像stackcollapse-perf.pl每一行竖向显示。

那么简单修改一下,将thread_fun5的func_a的stack重复4次,图形会变成什么样子呢?
可以看出thread_fun5的func_a变得更宽了。

所以不难理解,Flame Graph纵向表示一次调用栈深度,调用关系从下到上;Flame Graph横向宽度表示被perf record采样到的次数。
3. Flame Graph结果分析
所有的FlameGraph都是统计采样结果,根据进程、函数栈进行匹配,同样栈的采样计数累加。
FlameGraph的实际应用除了查看CPU使用情况之外,还有通过监控内存分配/释放函数的MemoryFlameGraph;
记录进程因为IO、唤醒等耗费时间的Off-CPU FlameGraph;
以及将CPU FlameGraph和Off-CPU FlameGraph进行合并的Hot/Cold FlameGraph;
对两次不同测试进行比较的DifferentialFlameGraph。
之前对CPU FlameGraph进行了介绍,下面详细介绍其余四种FlameGraph的使用。
3.1 MemoryFlameGraph
《Memory Leak (and Growth) Flame Graphs》关于内存的FlameGraph和CPU FlameGraph的区别在于CPU是采样,Memory跟踪内存trace events,比如malloc()/free()/realloc()/calloc()/brk()/mmap()。
然后在对调用栈进行统计,显示FlameGraph。其本质上是一样的。
perf record -e syscalls:sys_enter_mmap -a -g -- sleep
perf script | ./stackcollapse-perf.pl | ./flamegraph.pl --color=mem \ --title="Heap Expansion Flame Graph" --countname="calls" > out_mmap.svg
结果如下:

但从实际来看这张图并不能反映Memory Leak,也不能准确反映Memory Grouth。
因为只是记录mmap()的次数,没有记录每次大小;同时没有记录munmap()的次数。
3.1.1 一个通过trace events定位内存泄漏的案例
记得之前Debug过内存泄漏问题:运行过一段时间,发现总的内存在增加。查看/proc/meminfo大概是slab内存泄漏,然后查看一下/proc/slabinfo看出是kmalloc-64在不停增加。
所以借助tracing/events/kmem/kmalloc和kfree两个events,观察是哪个进程在泄漏内存,同时修改call_site从显示地址编程显示符号。
如何确定内存泄漏呢?
以进程作为组,kmalloc()分配大小累加;如果有kfree(),通过ptr匹配从累计值中减去对应kmalloc()大小。
这样在运行一段时间过后,每个进程的累计值就是增量,可以很轻松的确定增量是多少,以及每个增量的符号表。
3.2 Off-CPU FlameGraph
和CPU FlameGraph相反,Off-CPU FlameGraph反映的是进程没有在CPU上运行的时间都在干嘛,这也是影响进程性能的关键因素。
比如进程时间片用完导致的进程切换、映射到内存的IO操作、调度延迟等。
《Off-CPU Flame Graphs》循序渐进的介绍了IO造成的Off-CPU时间、包括IO延迟的Off-CPU时间、进程唤醒延时,以及展示进程之间唤醒点栈关系的Chain Graphs。
比如查看Block I/O次数的FlameGraph,这个只能做个参考。如果想要更准确的看IO延迟时间,还需要借助文中提到的biostacks、fileiostacks等工具。
sudo perf record -e block:block_rq_insert -a -g -- sleep
sudo perf script --header | ./stackcollapse-perf.pl | ./flamegraph.pl --color=io --title="Block I/O Flame Graph" --countname="I/O" > out.svg
结果如下:

3.3 Hot/Cold FlameGraph
《Hot/Cold FlameGraph》将On-CPU FlameGraph和Off-CPU FlameGraph融合到一张图中,这样就可以一目了然时间都耗费在哪里了。
但是目前生成的结果分析起来仍然比较困难,还处在实验阶段。
3.4 Differential FlameGraph
《Differential FlameGraph》比较两份FlameGraph,用于比较两个版本差异,更好地确定性能regression。
实际环境中的Differential FlameGraph较难分析,这里构造两个FlameGraph然后进行Differential比较。
分别构造伪数据out.folded1和out.folded2如下:
out.folded1
createFlame;start_thread;thread_fun1
createFlame;start_thread;thread_fun1;func_a
createFlame;start_thread;thread_fun2
createFlame;start_thread;thread_fun2;func_b
createFlame;start_thread;thread_fun2;func_b;func_a
createFlame;start_thread;thread_fun3
createFlame;start_thread;thread_fun3;func_c
createFlame;start_thread;thread_fun3;func_c;func_b
createFlame;start_thread;thread_fun3;func_c;func_b;func_a
createFlame;start_thread;thread_fun4
createFlame;start_thread;thread_fun4;func_d
createFlame;start_thread;thread_fun4;func_d;func_c
createFlame;start_thread;thread_fun4;func_d;func_c;func_b
createFlame;start_thread;thread_fun4;func_d;func_c;func_b;func_x
createFlame;start_thread;thread_fun4;func_d;func_c;func_b;func_a
createFlame;start_thread;thread_fun5
createFlame;start_thread;thread_fun5;func_e
createFlame;start_thread;thread_fun5;func_e;func_d
createFlame;start_thread;thread_fun5;func_e;func_d;func_c
createFlame;start_thread;thread_fun5;func_e;func_d;func_c;func_b
createFlame;start_thread;thread_fun5;func_e;func_d;func_c;func_b;func_a
out.folded2
createFlame;start_thread;thread_fun1
createFlame;start_thread;thread_fun1;func_a
createFlame;start_thread;thread_fun2
createFlame;start_thread;thread_fun2;func_b
createFlame;start_thread;thread_fun2;func_b;func_a
createFlame;start_thread;thread_fun3
createFlame;start_thread;thread_fun3;func_c
createFlame;start_thread;thread_fun3;func_c;func_b
createFlame;start_thread;thread_fun3;func_c;func_b;func_a
createFlame;start_thread;thread_fun4
createFlame;start_thread;thread_fun4;func_d
createFlame;start_thread;thread_fun4;func_d;func_c
createFlame;start_thread;thread_fun4;func_d;func_c;func_b
createFlame;start_thread;thread_fun4;func_d;func_c;func_b;func_a
createFlame;start_thread;thread_fun5
createFlame;start_thread;thread_fun5;func_e
createFlame;start_thread;thread_fun5;func_e;func_d
createFlame;start_thread;thread_fun5;func_e;func_d;func_c
createFlame;start_thread;thread_fun5;func_e;func_d;func_c;func_b
createFlame;start_thread;thread_fun5;func_e;func_d;func_c;func_b;func_x
createFlame;start_thread;thread_fun5;func_e;func_d;func_c;func_b;func_a
分别生成两者FlameGraph及Differential FlameGraph。
./flamegraph.pl < out.folded1 > out_1.svg
./flamegraph.pl < out.folded2 > out_2.svg
./difffolded.pl out.folded1 out.folded2 | ./flamegraph.pl > diff.svg
./difffolded.pl out.folded2 out.folded1 | ./flamegraph.pl > diff2.svg

图1

图2
图1和图2反映了两组数据的差异,图2相比图1thread_fun4少了func_x,减小了func_a;thread_fun5的func_a增大了,多了func_x。
下面是图1相对于图2的Differential FlameGraph,可以看出轮廓基本和图2一致。
图2丢掉的thread_fun4的func_x,不显示;func_a变小用蓝色标识。图2新增的thread_fun5的fun_x,thread_fun5的func_a用红色标识。

图3
然后再以图1为基础进行查分,如下图:

图4
4. 小结
CPU FlameGraph用于查找程序执行的热点,找出性能瓶颈。Memory FlameGraph用于简单分析内存泄漏或者增长趋势。
相对于CPU FlameGraph,Off-CPU FlameGraph能找出进程好在CPU之外的时间,对于提高进程性能找出浪费时间有效。
Hot/Cold FlameGraph将CPU FlameGraph和Off-CPU FlameGraph两者融合到一张图中,更清晰的展示进程时间分配。
Differential FlameGraph可用于性能Regression对比。
参考文档:
《Flame Graphs》:关于FlameGraph的来龙去脉,及其详细介绍汇总。
《The Flame Graph》:发表在acm.org文章,This visualization of software execution is a new necessity for performance profiling and debugging。
使用Flame Graph进行系统性能分析的更多相关文章
- Linux系统性能分析
http://c.biancheng.net/cpp/html/2782.htmlLinux系统性能分析 这篇教程的目的是向大家介绍一些免费的系统性能分析工具(命令),使用这些工具可以监控系统资源使用 ...
- 通信原理实践(四)——模拟通信系统性能分析
一.模拟通信系统性能分析 1.系统框图 2.信噪比定义 (1)输入信噪比: (2)输出信噪比: (3)调制制度增益: 3.模拟通信系统分析等价模型 即自己产生一个高斯白噪声,加入到调制信号,然后在送入 ...
- 操作系统性能分析与优化V1.0
操作系统性能分析与优化V1.0 : http://www.docin.com/p-759561760.html
- 使用perf生成Flame Graph(火焰图)
具体的步骤参见这里: <flame graph:图形化perf call stack数据的小工具> 使用SystemTap脚本制作火焰图,内存较少时,分配存储采样的数组可能失败,需 ...
- perf + Flame Graph火焰图分析程序性能
1.perf命令简要介绍 性能调优时,我们通常需要分析查找到程序百分比高的热点代码片段,这便需要使用 perf record 记录单个函数级别的统计信息,并使用 perf report 来显示统计结果 ...
- Linux 系统性能分析工具 sar
sar(System Activity Reporter系统活动情况报告)是目前 Linux 上最为全面的系统性能分析工具之一,可以 从多方面对系统的活动进行报告,包括:文件的读写情况.系统调用的使用 ...
- JMeter—系统性能分析思路(十三)
参考<全栈性能测试修炼宝典JMeter实战>第九章 性能监控诊断 第二节 系统性能分析思路和第三节 定位分析 系统在工作负载中的性能受到许多因素影响,处理器速度.内存容量.网络或磁盘I/O ...
- linux系统分析工具续-SystemTap和火焰图(Flame Graph)
本文为网上各位大神文章的综合简单实践篇,参考文章较多,有些总结性东西,自认暂无法详细写出,建议读文中列出的参考文档,相信会受益颇多.下面开始吧(本文出自 “cclo的博客” 博客,请务必保留此出处ht ...
- nmon与nmonanalyser系统性能分析
nmon与nmonanalyser系统性能分析(图表) - [系统架构] 2011-05-15 版权声明:转载时请以超链接形式标明文章原始出处和作者信息及本声明http://www.blogbus.c ...
随机推荐
- shell从入门到精通进阶之一:Shell基础知识
1.1 简介 Shell是一个C语言编写的脚本语言,它是用户与Linux的桥梁,用户输入命令交给Shell处理,Shell将相应的操作传递给内核(Kernel),内核把处理的结果输出给用户. 下面是处 ...
- Java——重载和重写
前言 在程序设计中经常会遇到对对方法的重载或者重写,下面将介绍重载和重写. 重载(Overloade) 重载出现的原因 任何程序设计语言都具备的一项重要特性就是对名字的运用.当创建一个对象时,就给对象 ...
- ROS笔记3 理解nodes
http://wiki.ros.org/ROS/Tutorials/UnderstandingNodes 介绍几个命令行工具用法 roscore rosnode rosrun A node reall ...
- 一统江湖的大前端(2)—— Mock.js + Node.js 如何与后端潇洒分手
<一统江湖的大前端>系列是自己的前端学习笔记,旨在介绍javascript在非网页开发领域的应用案例和发现各类好玩的js库,不定期更新.如果你对前端的理解还是写写页面绑绑事件,那你真的是有 ...
- hive 中遇到的正则
1.提取科室中,"科"字前面的内容 regexp_extract(t1.doctor_department_format,'(.*)科') 2.去除字符串中的数字 第一种方式: S ...
- Java开发笔记(十八)上下求索的while循环
循环是流程控制的又一重要结构,“白天-黑夜-白天-黑夜”属于时间上的循环,古人“年复一年.日复一日”的“日出而作.日落而息”便是每天周而复始的生活.计算机程序处理循环结构时,给定一段每次都要执行的代码 ...
- WordPress在Centos下Apache设置伪静态方法
1.设置httpd.conf文件 1.1 添加或取消注释这段代码 LoadModule rewrite_module modules/mod_rewrite.so 1.2 运行httpd -M查看这个 ...
- 设计模式之一工厂方法模式(Factory Method)
工厂方法模式分为三种: 一.普通工厂模式,就是建立一个工厂类,对实现了同一接口的一些类进行实例的创建.首先看下关系图: 举例如下:(我们举一个发送邮件和短信的例子) 首先,创建二者的共同接口: pub ...
- Sublime 无法安装插件的解决办法
1,打开命令面板 Ctrl + Shift + P 输入:pi 回车 按回车后,出现异常如下图: 解决办法: 1,点击Preferences----Brows Packages ---会到安装目录 ...
- java框架之mybatis
一.简介 1.基本概念 mybatis 是一个半自动轻量级的一个 orm 框架 将 java 与 sql 分离,解决了 jdbc 的硬编码问题: sql 由开发人员控制,更加方便 sql 的修改调优: ...