python学习之【第十三篇】:Python中的生成器
1.为什么要有生成器?
在Python中,通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。那么此时聪明的你肯定会这么想:有没有一种机制,当我们想要创建列表时,不要直接先把列表中元素全部创建出来,而是把列表元素生成的方法给我,当我要使用哪几个元素的时候我再生成,现做现卖,用多少做多少,这样多好。其实,这些前人们早就替我们想到了,所以,生成器应运而生。
2.什么是生成器?
如果列表元素可以按照某种算法推算出来,这样我们就不必创建出完整的列表,而是在循环的过程中不断推算出后续的元素,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器generator。
3.如何创建生成器?
要创建一个生成器generator,有很多种方法。我们介绍两种常用的方法:
- 简单生成器。第一种方法很简单,只要把一个列表生成式的
[]改成(),就创建了一个生成器generator; - 生成器函数。如果推算的算法比较复杂,用类似列表生成式无法实现的时候,还可以用函数来实现,这就是生成器函数。
4. 生成器表达式
只要把一个列表生成式的[ ]改成( ),就创建了一个生成器表达式generator。
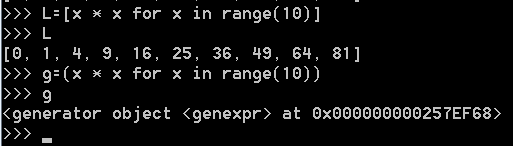
创建L和g的区别仅在于最外层的[ ]和( ),L是一个list,而g是一个generator。
我们可以直接打印出list的每一个元素,但我们怎么打印出generator的每一个元素呢?
如果要一个一个打印出来,可以通过next()函数获得generator的下一个返回值:
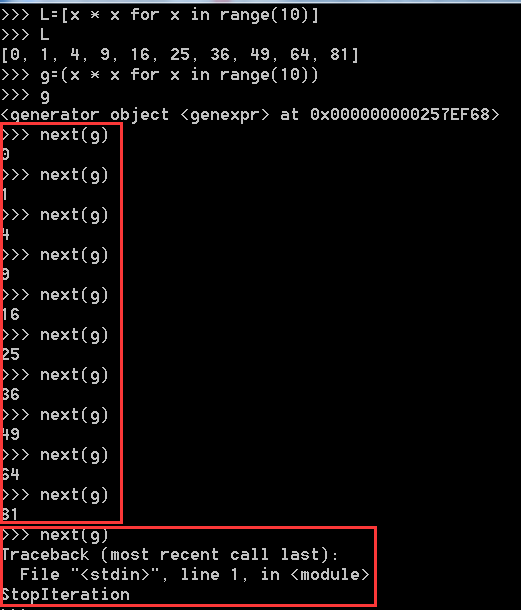
generator保存的是算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
因为generator也是可迭代对象,所以可以使用for循环来迭代:
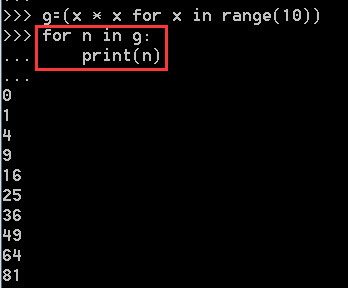
我们创建了一个generator后,基本上永远不会调用next(),而是通过for循环来迭代它,并且不需要关心StopIteration的错误。
5. 生成器函数
在上述的简单生成器中,元素推算的算法仅仅是x*x,比较简单。但是如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,我们可以用函数来实现。这个定义元素推算算法的函数我们称之为生成器函数。
生成器函数与普通函数有一个很重要的区别,那就是:生成器函数中需要return的地方通通使用yield来替换。
yield关键字
yield关键字,其作用和return的功能差不多,就是返回一个值给调用者,只不过有yield的函数返回值后函数依然保持调用yield时的状态,当下次调用的时候,在原先的基础上继续执行代码,直到遇到下一个yield或者满足结束条件结束函数为止。
我们可以看以下例子:

首先定义一个生成器函数,调用该生成器函数时,返回一个生成器对象generator,然后用next()函数不断获得下一个返回值,在执行过程中,遇到yield就中断,下次又继续执行。执行3次yield后,已经没有yield可以执行了,所以,第4次调用next(g)就报错。
同样的,使用生成器函数,我们基本上也不会用next()来获取下一个返回值,而是直接使用for循环来迭代:
def test():
print('step1')
yield 1
print('step2')
yield 2
print('step3')
yield 3
g = test()
for i in g:
print(i)
# 输出
# step1
# 1
# step2
# 2
# step3
# 3
6.生成器函数与普通函数的区别
生成器函数与普通函数主要有以下不同:
- 生成器函数包含一个或者多个
yield; - 当调用生成器函数时,函数将返回一个对象,但是不会立刻向下执行;
- 像
__iter__()和__next__()方法等是自动实现的,所以我们可以通过next()方法对对象进行迭代; - 一旦函数被
yield,函数会暂停,控制权返回调用者; - 局部变量和它们的状态会被保存,直到下一次调用;
- 函数终止的时候,
StopIteraion会被自动抛出;
7.应用
咋一看,生成器好像没有什么用啊,其实不然,很多情况下元素是无穷无尽的,例如斐波那契数列,杨辉三角等,这些元素都是不能被穷举的,所以我们无法将所有元素都放到一个列表里,只能是保存元素推算的算法,再进行逐个推算,这就是生成器的好处。
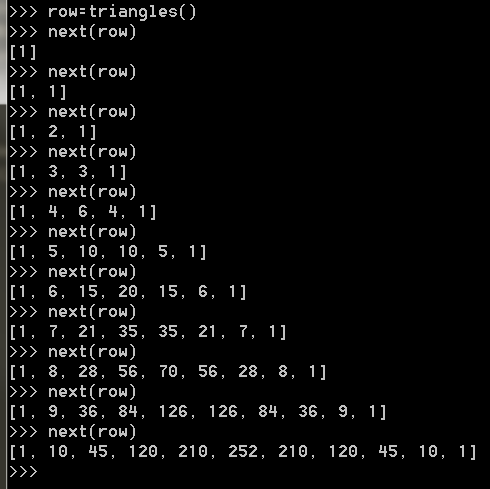
例如生成杨辉三角的代码,把每一行看做一个list,试写一个generator,不断输出下一行的list:
1
/ \
1 1
/ \ / \
1 2 1
/ \ / \ / \
1 3 3 1
/ \ / \ / \ / \
1 4 6 4 1
/ \ / \ / \ / \ / \
1 5 10 10 5 1
# 杨辉三角
def triangles():
old_list = []
new_list = []
while True:
length = len(old_list)
if length == 0:
new_list.append(1)
else:
for item in range(length + 1):
if item == 0:
new_list.append(1)
elif item == length:
new_list.append(1)
else:
tmp = old_list[item - 1] + old_list[item]
new_list.append(tmp)
yield new_list
old_list = new_list.copy()
new_list.clear()
(完)
python学习之【第十三篇】:Python中的生成器的更多相关文章
- Python 学习笔记(十三)Python函数(二)
参数和变量 >>> def foo(a,b): #函数是一个对象 return a+b >>> p =foo #对象赋值语句.将foo函数赋值给p这个变量 > ...
- Python 学习笔记(十三)Python函数(一)
函数基础 函数:函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段. 函数能提高应用的模块性,和代码的重复利用率.Python提供了许多内建函数,比如print().可以自己创建函数,这 ...
- Python开发【第二十三篇】:持续更新中...
Python开发[第二十三篇]:持续更新中...
- Python学习笔记(十三)
Python学习笔记(十三): 模块 包 if name == main 软件目录结构规范 作业-ATM+购物商城程序 1. 模块 1. 模块导入方法 import 语句 import module1 ...
- Python学习笔记之基础篇(-)python介绍与安装
Python学习笔记之基础篇(-)初识python Python的理念:崇尚优美.清晰.简单,是一个优秀并广泛使用的语言. python的历史: 1989年,为了打发圣诞节假期,作者Guido开始写P ...
- Python开发【第十三篇】:jQuery--无内容点击-不进去(一)
Python开发[第十三篇]:jQuery--无内容点击-不进去(一)
- openresty 学习笔记番外篇:python的一些扩展库
openresty 学习笔记番外篇:python的一些扩展库 要写一个可以使用的python程序还需要比如日志输出,读取配置文件,作为守护进程运行等 读取配置文件 使用自带的ConfigParser模 ...
- openresty 学习笔记番外篇:python访问RabbitMQ消息队列
openresty 学习笔记番外篇:python访问RabbitMQ消息队列 python使用pika扩展库操作RabbitMQ的流程梳理. 客户端连接到消息队列服务器,打开一个channel. 客户 ...
- Python学习系列(四)Python 入门语法规则2
Python学习系列(四)Python 入门语法规则2 2017-4-3 09:18:04 编码和解码 Unicode.gbk,utf8之间的关系 2.对于py2.7, 如果utf8>gbk, ...
- Python学习入门基础教程(learning Python)--5.6 Python读文件操作高级
前文5.2节和5.4节分别就Python下读文件操作做了基础性讲述和提升性介绍,但是仍有些问题,比如在5.4节里涉及到一个多次读文件的问题,实际上我们还没有完全阐述完毕,下面这个图片的问题在哪呢? 问 ...
随机推荐
- Pycharm 快捷键大全 2019.2.3
在Pycharm中打开Help->Keymap Reference可查看默认快捷键帮助文档,文档为PDF格式,位于安装路径的help文件夹中,包含MAC操作系统适用的帮助文档. 下图为2019. ...
- 2.1实现简单基础的vector
2.1实现简单基础的vector 1.设计API 我们参考下C++ <std> 库中的vector, vector中的api很多,所以我们把里面用的频率很高的函数实现; 1.1 new&a ...
- Qt+VC2010+glew环境安装配置
Qt的源码及预编译安装包在 Qt Archive下载,http://download.qt.io/archive/qt/, 目前最新的是Qt5,其中和Qt4不同的是,Qt5多了个QOpenGLWidg ...
- [UWP]使用CompositionLinearGradientBrush实现渐变画笔并制作动画
1. 什么是 CompositionBrush CompositionBrush(合成画笔)是操作可视化层时用于绘制 SpriteVisual 区域的画笔. 使UWP 应用时可以选择使用 XAML 画 ...
- 移动端真机调试--weinre
一.安装 首先确保你的电脑上有node环境,然后使用cnpm或npm 安装 windows下 npm install weinre -g --registry=https://registry.npm ...
- 03 Node.js学习笔记之根据http请求路径返回不同数据
在Nodejs中,当客户端请求的路径不同时,NodeJS处理返回不同的数据 步骤: //1.载入http模块 var http=require('http'); //2.创建一个http服务 var ...
- PostgreSQL使用安装
PostgreSQL使用安装 一. 安装 ubuntu安装: # 安装客户端 sudo apt-get install postgresql-client # 安装服务器 sudo apt-get i ...
- ES和zookeeper选取帮主之江湖秘闻
ES帮会 某日,ES帮会中决定选取老大统领帮会走向辉煌.大家七嘴八舌,讨论方案,场面一顿混乱.傻牛站起来大喊一声:谁比俺力气大,谁就当老大.(ES集群在启动时,选取集群master,按照nodeId进 ...
- jQuery选择器 大于 空格 波浪线 加号
JQuery选择器 大于 空格 波浪线 加号的区别 元素遍历 符号 说明 空格 $(‘parent child’)表示获取parent下的所有的child节点(所有的子孙). 大于号 $(‘paren ...
- Unity修改脚本后调试
修改脚本后调试有时候需要运行,为了提高效率可以设置编辑器中执行,同时也可以开启有效性检查(即更改面板变量即可刷新代码) [ExecuteInEditMode] public class XXXX: M ...