用jTessBoxEditorFX训练字库
软件下载:https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
官方字库下载:https://github.com/tesseract-ocr/tesseract/wiki/Data-Files#format-of-traineddata-files
建议:普通版本和FX版本都下载,用普通版本调整坐标,用FX版本调整汉字识别。FX版本的坐标调整不能输入数字,一旦坐标偏移太大,简直就是反人类设计。
另外,也可以直接使用普通版本,虽然在Box Editor页面里看不到汉字,但是可以用Notepad++直接打开box文件进行文字编辑。
文中用的是FX2.0beta版,有些小问题,但是不影响使用,目前正式版应该是2.2。
1、点击tools后再点击Merge TIFF,将所需要的图片集转换成tif格式,源图片集格式支持jpg和tif两种。合成的图片集命名格式为[chi_sim].[test].[exp0].tif 第一个空是字典格式,第二个字体(自定义)名字,第三个空位exp[0]。

2、生成BOX文件,D:\jTessBoxEditorFX\tesseract-ocr\tesseract.exe chi_sim.test.exp0.tif chi_sim.test.exp0 -l chi_sim batch.nochop makebox
D:\temp\train2>D:\jTessBoxEditorFX\tesseract-ocr\tesseract.exe chi_sim.test.exp1.tif chi_sim.test.exp1 -l chi_sim batch.nochop makebox
Tesseract Open Source OCR Engine v4.00.00alpha with Leptonica
Page 1
Page 2
Page 3
Page 4
-l chi_sim参数是使用已经有的中文训练字库
这个字库是在tessdata目录里,可以自己拷贝进去

3、调整字体坐标,调整识别错误的汉字。使用open打开刚才生成的tif文件,根据刚才生成的box文件调整字库。这个步骤才是真正核心的步骤,也是最麻烦的地方。
调整坐标建议使用普通版本,FX版本无法手动调整坐标,不知道是不是故意设置还是BUG。

merge合并的时候有几个图片文件,这里就需要按page页分别调整。
4、调整完成box文件后,就需要生成tr文件
D:\jTessBoxEditorFX\tesseract-ocr\tesseract.exe chi_sim.test.exp0.tif chi_sim.test.exp0 nobatch box.train
5、生成unicharset文件
D:\jTessBoxEditorFX\tesseract-ocr\unicharset_extractor.exe chi_sim.test.exp0.box
6、新建font_properties文件 用记事本新建一个明文font_properties.txt
内容格式为test 0 0 0 0 0,test是新建tif中间的内容(chi_sim.test.exp0.tif)。
7、在分别运行三个命令对tr特征集合进行操作
生成shape文件
D:\jTessBoxEditorFX\tesseract-ocr\shapeclustering.exe -F font_properties.txt -U unicharset chi_sim.test.exp0.tr
生成聚集字符特征文件
D:\jTessBoxEditorFX\tesseract-ocr\Mftraining.exe -F font_properties.txt -U unicharset -O unicharset chi_sim.test.exp0.tr
生成字符正常化特征文件
D:\jTessBoxEditorFX\tesseract-ocr\cntraining.exe chi_sim.test.exp0.tr
8、重命名把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件前面都加上test.(就是你的tif中间的名字)
9、组合文件,成功后会生成test.traineddata训练库文件。
D:\jTessBoxEditorFX\tesseract-ocr\combine_tessdata test.(后面是有点的)
10、识别测试,把test.traineddata拷贝到D:\jTessBoxEditorFX\tesseract-ocr\tessdata目录下
D:\jTessBoxEditorFX\tesseract-ocr\tesseract chi_sim.test.exp0.tif output -l test
11、在代码中测试效果,可以全部识别出来,简单的代码之前发过(java 使用tess4j实现OCR的最简单样例)

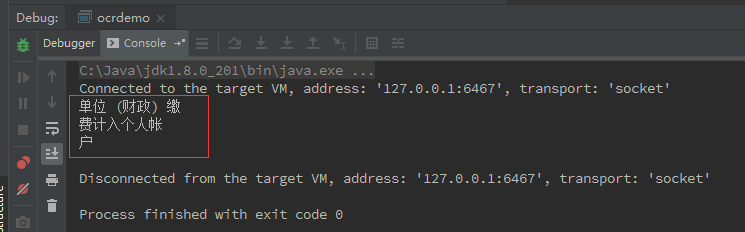
12、如果需要识别的图形比较复杂,一般情况下不能对整张图片进行识别,需要把图片分块识别,用代码也好实现,关键是准备阶段划分图片区域比较费事。
public static void main(String args[]) throws Exception {
ITesseract instance = new Tesseract();
instance.setDatapath("tessdata"); //相对目录,这个时候tessdata目录和src目录平级
instance.setLanguage("test");//选择字库文件(只需要文件名,不需要后缀名)
try {
File imageFile = new File("d:\\temp\\1.jpg");
BufferedImage bufferedImage = ImageIO.read(imageFile);
Rectangle rect = new Rectangle(2581,510,249,196);//按区域读取
String result2 = instance.doOCR(bufferedImage,rect);
System.out.println(result2);
} catch (Exception e) {
System.out.println(e.toString());
}
}
用jTessBoxEditorFX训练字库的更多相关文章
- 使用jTessBoxEditorFX训练Tesseract-OCR教程
使用jTessBoxEditorFX训练Tesseract-OCR教程 注:1,工具是JAVA编写的,所以在使用工具之间,需要安装JAVA环境. 2,安装Tesseract-OCR应用程序,并将目录添 ...
- Tesseract-OCR识别中文与训练字库实例
关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试用一下,分享到博客让有同样兴趣的人少走弯路. 文中所用到的身份证图片资源是百度找的,如有侵权可联系我删除. 一. ...
- Tesseract-OCR4.0识别中文与训练字库实例
关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试用一下,分享到博客让有同样兴趣的人少走弯路. 文中所用到的身份证图片资源是百度找的,如有侵权可联系我删除. 一. ...
- 深入学习Tesseract-ocr识别中文并训练字库的方法
上篇文章简单的学习了tesseract-ocr识别图片中的英文(链接地址如下:https://www.cnblogs.com/wj-1314/p/9428909.html),看起来效果还不错,所以这篇 ...
- Tesseract5.0训练字库,提高OCR特殊场景识别率(一)
0.目标 很多特殊场景,原生的字库识别率不高,这时候就需要根据需求自己训练字库生成traineddata文件. 一.前期准备工作 1.安装jdk 用于运行jTessBoxEditor 2.安装jT ...
- Tesseract-OCR识别中文与训练字库
转自:https://www.cnblogs.com/lcawen/articles/7040005.html 关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试 ...
- Tesseract_ocr 字符识别基础及训练字库、合并字库
字符训练网上一搜一大堆,但作为一个初学者而言,字符合并网上却写的很笼统 首先,需要 生成的字符集.tif文件,位置文件 .box ,只要有这两个文件在,就可以合并字典(这个说的很有道理的样子) 好了, ...
- Tesseract5.0训练字库,提高OCR特殊场景识别率,合并字库(二)
一.准备工作 需要的文件 tif文件和box文件. 如果你打标打好了,但是是分批次打标的,那么可以合并字库,我们最初只需要 tif 和 box 文件,如下: 二.生成对应的 .tr 训练文件 根据不同 ...
- tesseract-ocr字库训练图文讲解
第一步合成图片集 你需要把使用jTessBoxEditor工具把你的训练素材及多张图片合并成一张tif格式的图片集 第二步 生成box文件 运行tesseract命令,tesseract mjorc ...
随机推荐
- 201871020225-牟星源《面向对象程序设计(java)》第十六周学习总结
201871020225-牟星源<面向对象程序设计(java)>第十六周学习总结 项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ ...
- Vue (表单、斗篷、条件、循环指令,分隔符成员、计算属性成员、属性的监听、vue组件、子组件、各个常见的钩子函数)
表单指令 <!DOCTYPE html> <html lang="zh"> <head> <meta charset="UTF- ...
- 洛谷 U86501 趣味擂台
洛谷 U86501 趣味擂台 题目传送门 题目背景 \(JDFZ\)\(2019\)秋季运动会开始辣!运动会中有一个叫做"趣味擂台"的游戏...... 题目描述 游戏内容是这样的: ...
- 字段加密实践(django-fernet-fields)
一.fernet介绍 Fernet 用于django模型字段对称加密,使用 crytography 库. 官网帮助文档 1.先决条件 django-fernet-fields 支持Django 1.8 ...
- 7.29 NOIP模拟测试10 辣鸡(ljh)+模板(ac)+大佬(kat)
T1 辣鸡(ljh) 就是一道分类讨论的暴搜,外加一丢丢的减枝,然而我挂了,为啥呢,分类讨论变量名打错,大于小于号打反,能对才怪,写了sort为了调试就注释了,后来忘了解开,小减枝也没打.但是这道题做 ...
- Django-Debug-Toolbar插件
目录 django配置插件: 介绍: 安装及配置: 优化ORM: django配置插件: ---配置Django-Debug-Toolbar 介绍: Django-Debug-Toolbar是项目开发 ...
- [LeetCode] 83. Remove Duplicates from Sorted List 移除有序链表中的重复项
Given a sorted linked list, delete all duplicates such that each element appear only once. Example 1 ...
- 2019年上-C语言程序设计-第1次blog作业
准备工作(20分) 1.在博客园申请个人博客,以真实姓名和学号加入班级博客(链接地址) 2.关注邹欣老师博客(并寻找答案:邹欣老师是谁?是做什么的?).关注任课老师博客 3.注册登录中国大学MOOC网 ...
- 去掉DataGridView最后一行的空白行,删除空白行
//不显示出dataGridView1的最后一行空白 dataGridView1.AllowUserToAddRows = false; 直接在LODE事件
- Java连载17-赋值类运算符&字符串的连接运算符
一.赋值运算符 1.赋值类运算符包括两种: (1)基本赋值运算符:= (2)扩展的赋值运算符: += -= *= /= &= 赋值类的运算符优先级:先执行等号右边的表 ...