初学Hadoop之中文词频统计
1、安装eclipse
准备
eclipse-dsl-luna-SR2-linux-gtk-x86_64.tar.gz
安装
1、解压文件。
2、创建图标。
ln -s /opt/eclipse/eclipse /usr/bin/eclipse #使符号链接目录
vim /usr/share/applications/eclipse.desktop #创建一个 Gnome 启动

添加如下代码:
[Desktop Entry]
Encoding=UTF-8
Name=Eclipse 4.4.2
Comment=Eclipse Luna
Exec=/usr/bin/eclipse
Icon=/opt/eclipse/icon.xpm
Categories=Application;Development;Java;IDE
Version=1.0
Type=Application
Terminal=0

完成以后则会出现下图中的图标。

至此,eclipse安装完成。
2、安装hadoop插件
1、下载插件http://pan.baidu.com/s/1ydUEy 。
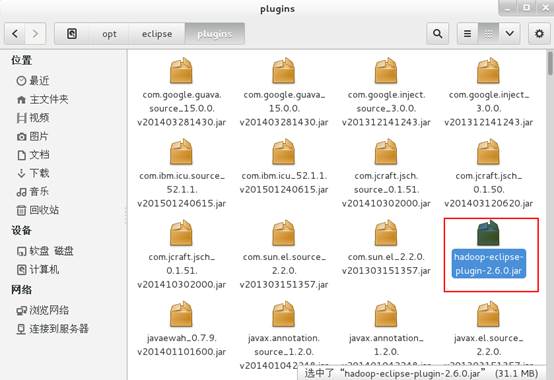
2、将插件放到/opt/eclipse/plugins文件夹下。
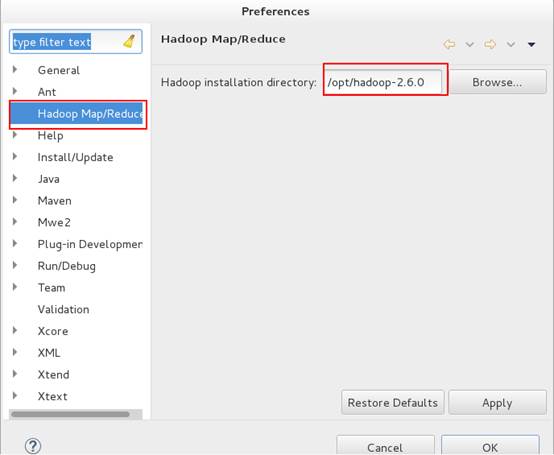
3、在eclipse->Windows->preferences设置Hadoop路径。
至此,插件安装完成。
3、ChineseWordCount源码
package com.example.test; import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.Reader;
import java.io.ByteArrayInputStream; import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class ChineseWordCount { public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context)
throws IOException, InterruptedException { byte[] bt = value.getBytes();
InputStream ip = new ByteArrayInputStream(bt);
Reader read = new InputStreamReader(ip);
IKSegmenter iks = new IKSegmenter(read, true);
Lexeme t;
while ((t = iks.next()) != null) {
word.set(t.getLexemeText());
context.write(word, one);
}
}
} public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(ChineseWordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4、创建Hadoop工程
1、创建一个Map/Reduce Project,名称为ChineseWordCount。
2、创建包com.example.test,创建ChineseWordCount类文件。
3、导入IkAnalyzer包。
下载地址:http://code.google.com/p/ik-analyzer/
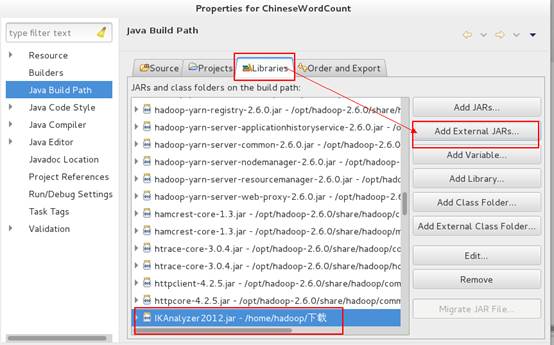
至此,Hadoop工程新建完成。
5、运行工程
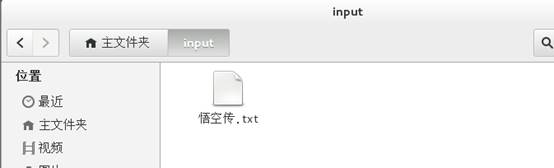
1、在/home/hadoop/目录下新建一个input文件夹,将中文文本"悟空传.txt"复制到里面。

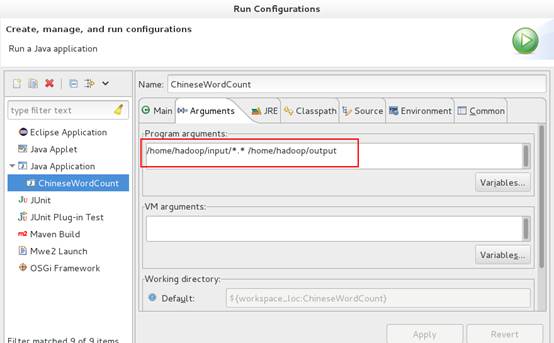
2、在eclipse中设置运行参数。
操作时遇到一个问题,当运行参数设置成/opt/hadoop-2.6.0/input/*.* /opt/hadoop-2.6.0/output时,无法运行成功,我想会不会是访问权限的问题,这个下次再解决。
3、点击运行。
6、查看结果

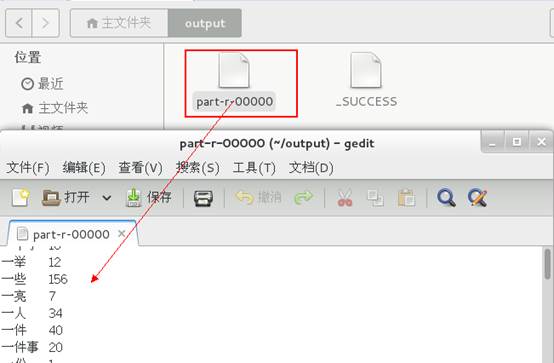
至此,中文词频统计运行成功。
7、总结
这次的中文词频统计只是一个简单的实验,还需要继续完善统计功能,比如词频数量的排序,去除单字统计等等。这方面我接触的还不深,希望有经验的朋友能给我一些学习建议和意见,谢谢。
初学Hadoop之中文词频统计的更多相关文章
- 初学Hadoop之WordCount词频统计
1.WordCount源码 将源码文件WordCount.java放到Hadoop2.6.0文件夹中. import java.io.IOException; import java.util.Str ...
- Python中文词频统计
以下是关于小说的中文词频统计 这里有三个文件,分别为novel.txt.punctuation.txt.meaningless.txt. 这三个是小说文本.特殊符号和无意义词 Python代码统计词频 ...
- 如何用java完成一个中文词频统计程序
要想完成一个中文词频统计功能,首先必须使用一个中文分词器,这里使用的是中科院的.下载地址是http://ictclas.nlpir.org/downloads,由于本人电脑系统是win32位的,因此下 ...
- Java实现中文词频统计
昨日有个中文词频统计的需求, 百度一番后, 发现一大堆标题党文章, 讲的与内容严重不符, 这里就简单记录下自己实现的流程吧! 与英文单词的词频统计不同, 中文的难点在于如何分词, 不过好在有许多优秀的 ...
- jieba (中文词频统计) 、collections (字频统计)、WordCloud (词云)
py库: jieba (中文词频统计) .collections (字频统计).WordCloud (词云) 先来个最简单的: # 查找列表中出现次数最多的值 ls = [1, 2, 3, 4, 5, ...
- py库: jieba (中文词频统计) 、collections (字频统计)、WordCloud (词云)
先来个最简单的: # 查找列表中出现次数最多的值 ls = [1, 2, 3, 4, 5, 6, 1, 2, 1, 2, 1, 1] ls = ["呵呵", "呵呵&qu ...
- Python实现简单中文词频统计示例
简单统计一个小说中哪些个汉字出现的频率最高: import codecs import matplotlib.pyplot as plt from pylab import mpl mpl.rcPar ...
- Programming | 中/ 英文词频统计(MATLAB实现)
一.英文词频统计 英文词频统计很简单,只需借助split断句,再统计即可. 完整MATLAB代码: function wordcount %思路:中文词频统计涉及到对"词语"的判断 ...
- Hadoop上的中文分词与词频统计实践 (有待学习 http://www.cnblogs.com/jiejue/archive/2012/12/16/2820788.html)
解决问题的方案 Hadoop上的中文分词与词频统计实践 首先来推荐相关材料:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-c ...
随机推荐
- java处理中国气象数据,提取汇总陕西地区24小时各观测点的数据(csv格式)
1.先贴一下气象数据的csv源格式,由于数据内容较多,就放一部分(china_sites_20150102.csv) date,hour,type,1001A,1002A,1003A,1004A,10 ...
- ubuntu 16.4安装toolsbelt heroku
https://devcenter.heroku.com/articles/getting-started-with-python#set-up # Run this from your termin ...
- P2407 [SDOI2009]地图复原
$ \color{#0066ff}{ 题目描述 }$ 很久以前,有一个传说中的"EWF"部族,他们世代生活在一个N×M的矩形大地上.虽然,生活的地区有高山.有沼泽,但通过勤劳勇敢, ...
- sql 面试题记录
一张学生表,字段 :学生ID,学生课程,学生成绩 问:每门课程前三名的学生信息? create table student ( id ), --编号 class ),--课程 soure int -- ...
- win10系统常用操作
1.打开控制面板 (1)选中“此电脑”,右键选择“属性”. (2)可见 控制面板主页 2.设置环境变量和系统变量 (1)选中“此电脑”,右键选择“属性”. (2)可见 控制面板主页 (3)点击高级系统 ...
- SQL数据库“单个用户”不能访问,设置为多个用户的解决方法
USE master; GO DECLARE @SQL VARCHAR(MAX); SET @SQL='' SELECT @SQL=@SQL+'; KILL '+RTRIM(SPID) FROM ma ...
- 【算法笔记】B1007 素数对猜想
1007 素数对猜想 (20 分) 让我们定义dn为:dn=pn+1−pn,其中pi是第i个素数.显然有d1=1,且对于n>1有dn是偶数.“素数对猜想 ...
- bzoj1221软件开发 费用流
题目传送门 思路: 网络流拆点有的是“过程拆点”,有的是“状态拆点”,这道题应该就属于状态拆点. 每个点分需要用的,用完的. 对于需要用的,这些毛巾来自新买的和用过的毛巾进行消毒的,流向终点. 对于用 ...
- SPOJ - LOCKER 数论 贪心
题意:求出\(n\)拆分成若干个数使其连乘最大的值 本题是之江学院网络赛的原题,计算规模大一点,看到EMAXX推荐就做了 忘了大一那会是怎么用均值不等式推出结果的(还给老师系列) 结论倒还记得:贪心分 ...
- Apache Shiro(六)-基于URL配置权限
数据库 先准备数据库啦. DROP DATABASE IF EXISTS shiro; CREATE DATABASE shiro DEFAULT CHARACTER SET utf8; USE sh ...