Spark源码剖析 - SparkContext的初始化(三)_创建并初始化Spark UI
3. 创建并初始化Spark UI
任何系统都需要提供监控功能,用浏览器能访问具有样式及布局并提供丰富监控数据的页面无疑是一种简单、高效的方式。SparkUI就是这样的服务。
在大型分布式系统中,采用事件监听机制是最常见的。为什么要使用事件监听机制?假如SparkUI采用Scala的函数调用方式,那么随着整个集群规模的增加,对函数的调用会越来越多,最终会受到Driver所在JVM的线程数量限制而影响监控数据的更新,甚至出现监控数据无法及时显示给用户的情况。由于函数调用多数情况下是同步调用,这就导致线程被阻塞,在分布式环境中,还可能因为网络问题,导致线程被长时间占用。将函数调用更换为发送事件,事件的处理是异步的,当前线程可以继续执行后续逻辑,线程池中的线程还可以被重用,这样整个系统的并发度会大大增加。发送的事件会存入缓存,由定时调度器取出后,分配给监听此事件的监听器对监控数据进行更新。Spark UI的架构如下:
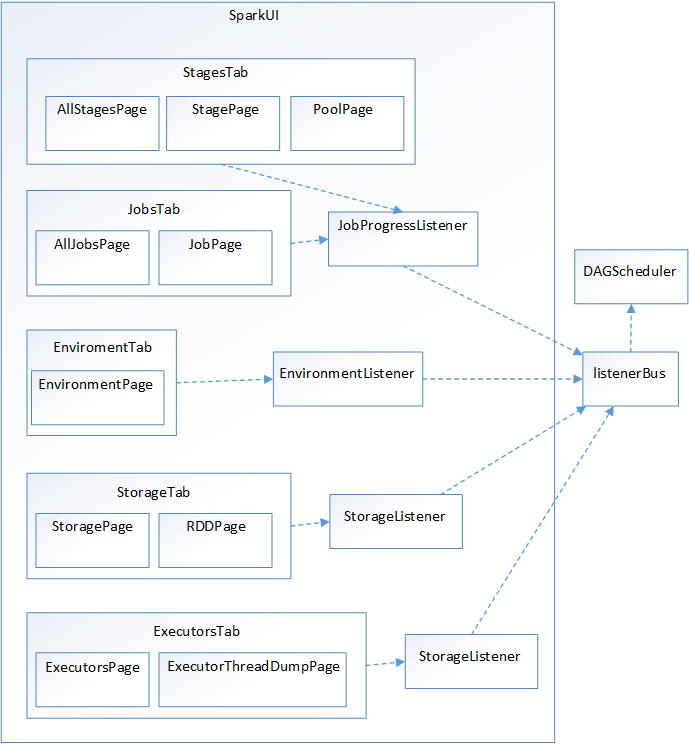
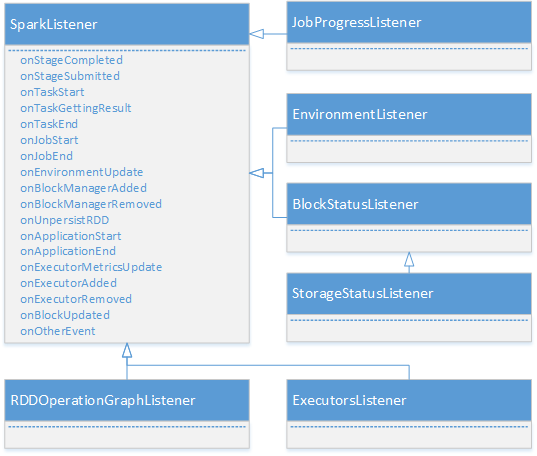
DAGScheduler是主要的产生各类SparkListenerEvent的源头,它将各种SparkListenerEvent发送到listenerBus的事件队列中,listenerBus通过定时器将SparkListenerEvent事件匹配到具体的SparkListener,改变SparkListener中的统计监控数据,最终由SparkUI的界面展示。从上图中可以看到Spark里定义了很多监听器SparkListener的实现,包括JobProgressListener、EnvironmentListener、StorageListener、ExecutorsListener,它们的类继承体系如图:
3.1 listenerBus详解
listenerBus的类型是LiveListenerBus,继承listenerBus类。LiveListenerBus实现了监听器模型,通过监听事件触发对各种监听器监听状态信息的修改,达到UI界面的数据刷新效果。LiveListenerBus由以下部分组成:
- 事件阻塞队列:类型为LinkedBlockingQueue[SparkListenerEvent],固定大小是10000;
- 监听器数组:类型为CopyOnWriteArrayList[SparkListener],存放各类监听器SparkListener。
- 事件匹配监听器的线程:此listenerThread不断拉取LinkedBlockingQueue中的事件,遍历监听器,调用监听器的方法。任何事件都会在LinkedBlockingQueue中存在一段时间,然后listenerThread处理了此事件后,会将其清除。因此使用listenerBus这个名字再合适不过了,到站就下车。listenerBus的实现见代码如下:
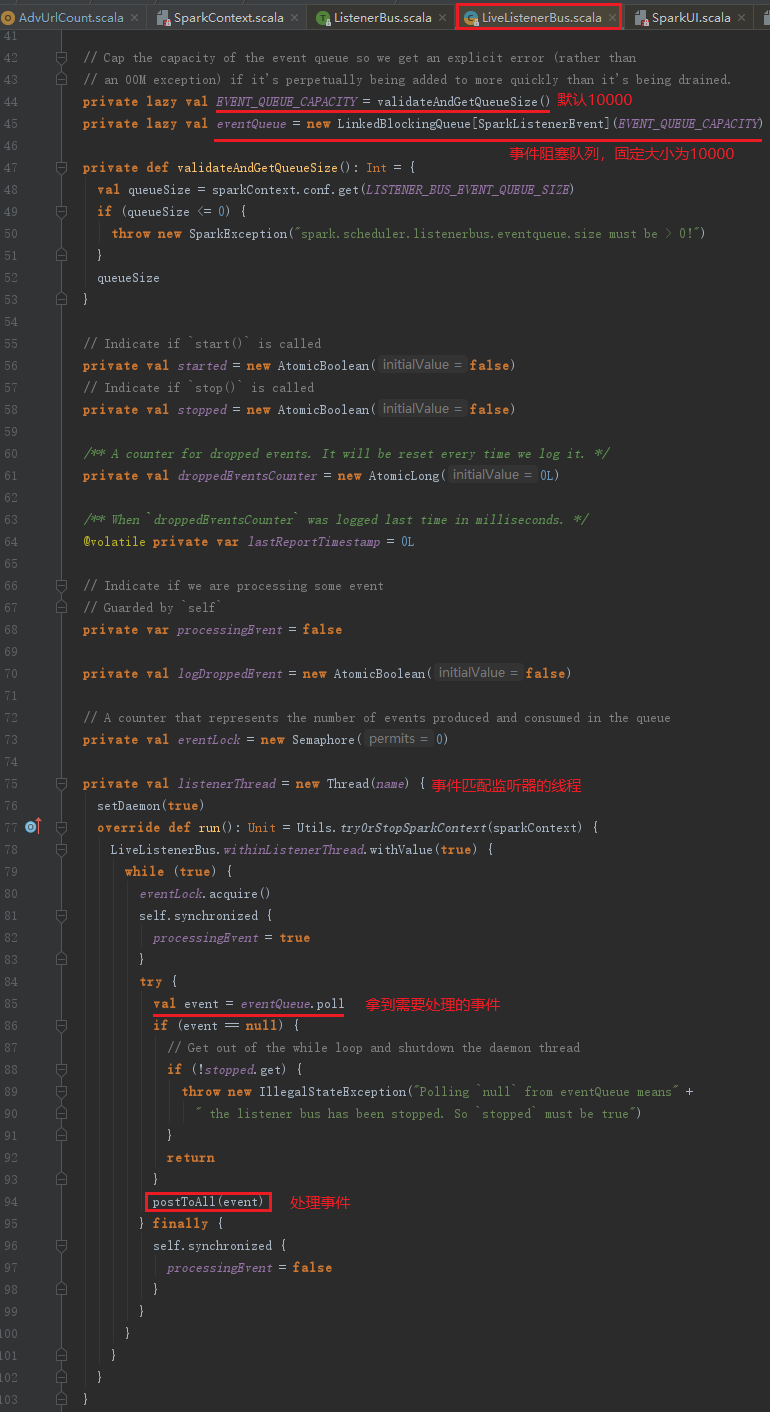
LiveListenerBus中调用的postToAll方法实际定义在父类SparkListenerBus的父类ListenerBus中,SparkListenerBus继承ListenerBus,而LiveListenerBus继承SparkListenerBus,ListenerBus的postToAll方法代码如下:
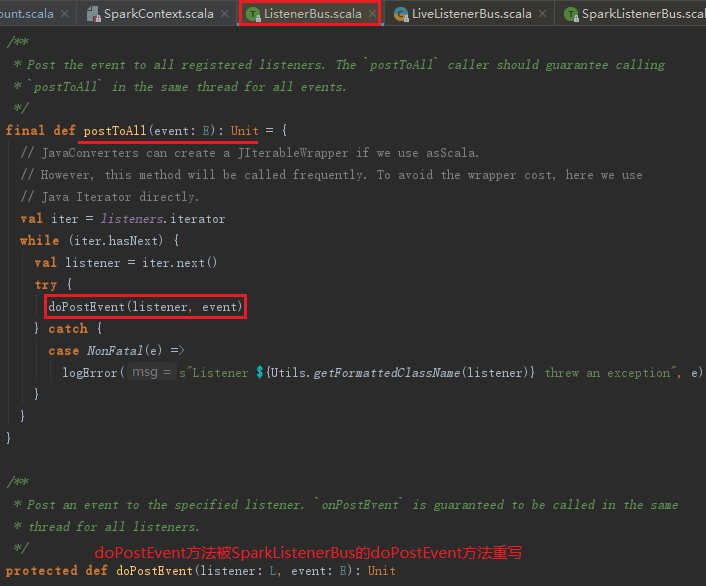
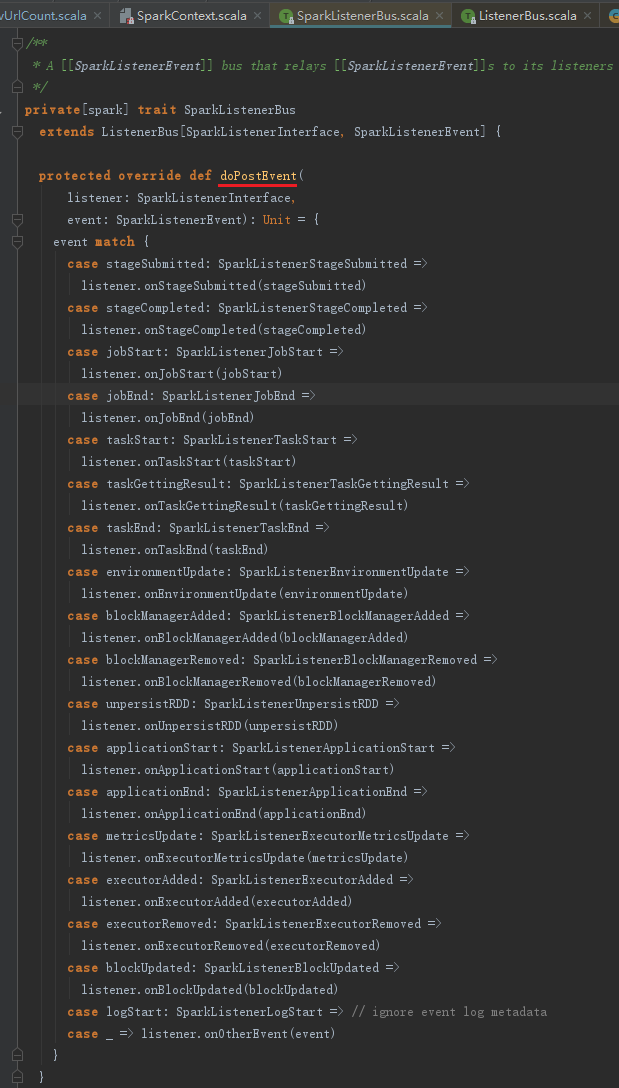
doPostEvent方法在SparkListenerBus中被重写,代码如下:
3.2 构造JobProgressListener
我们以JobProgressListener为例来讲解SparkListener。JobProgressListener是SparkContext中一个重要的组成部分,通过监听listenerBus中的事件更新任务进度。SparkUI实际上也是通过JobProgressListener来实现任务状态跟踪的。创建JobProgressListener的代码如下:

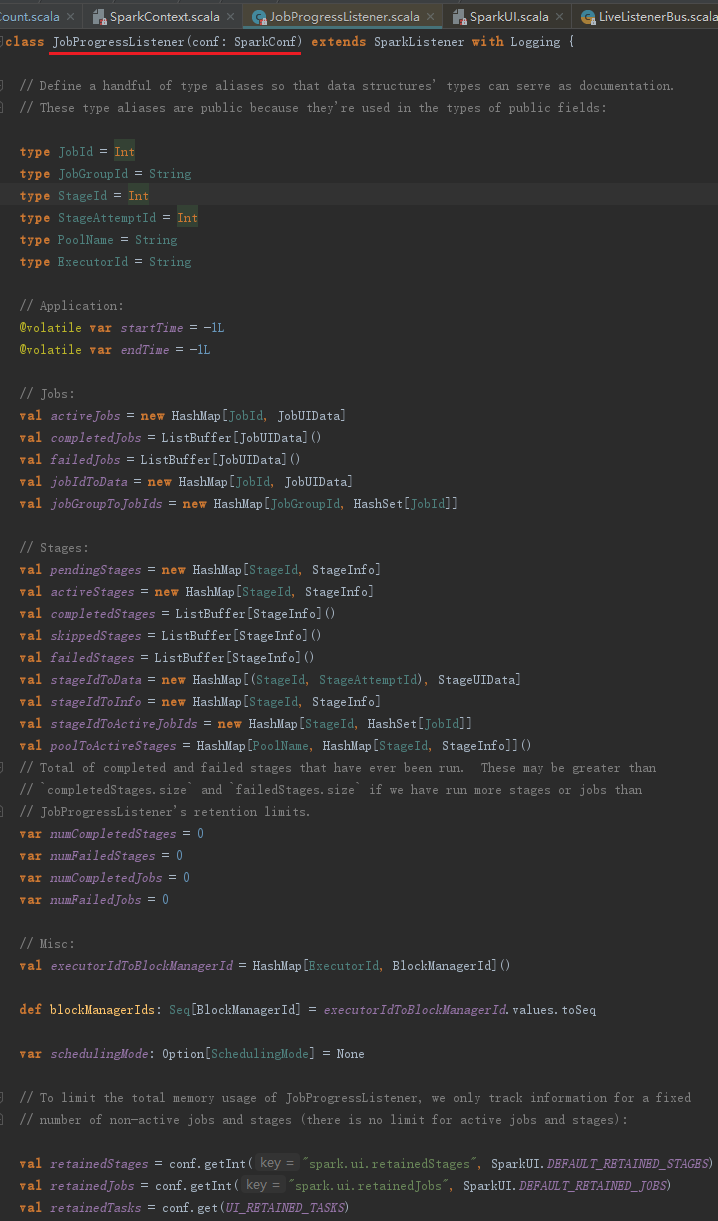
JobProgressListener的作用是通过HashMap、ListBuffer等数据结构存储JobId及对应的JobUIDate信息,并按照激活、完成、失败等job状态统计。对于StageId、StageInfo等信息按照激活、完成、忽略、失败等Stage状态统计,并且存储StageId与JobId的一对多关系。这些统计信息最终会被JobPage和StagePage等页面访问和渲染。JobProgressListener的数据结构见代码如下:
JobProgressListener实现了onJobStart、onJobEnd、onStageCompleted、onStageSubmitted、onTaskStart、onTaskEnd等方法,这些方法正是在listenerBus的驱动下,改变JobProgressListener中的各种Job、Stage相关的数据。
3.3 SparkUI的创建与初始化
SparkUI的创建,见代码:
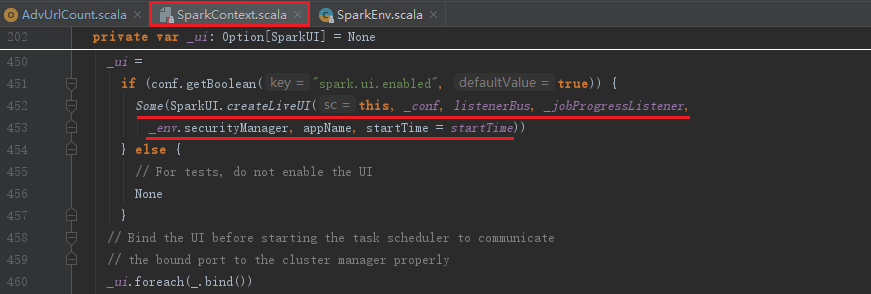
可以看到如果不需要提供SparkUI服务,可以将属性spark.ui.enabled修改为false。其中createLiveUI实际是调用了create方法,见代码:

create方法的实现见代码:
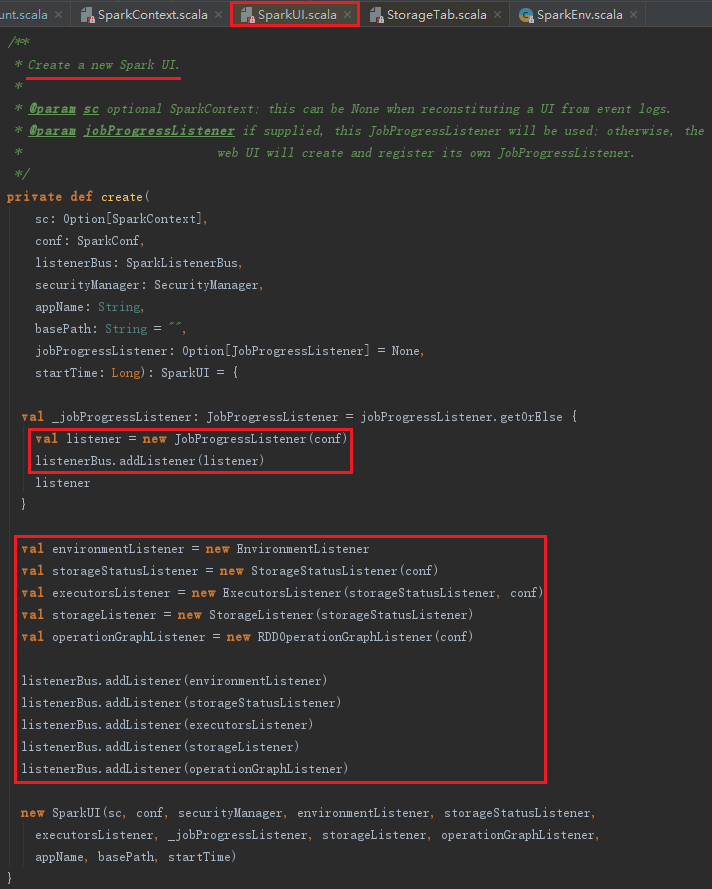
根据上述代码,可以知道在create方法里除了JobProgressListener是外部出入的之外,又增加了一些SparkListener。例如,用于对JVM参数、Spark属性、Java系统属性、classpath等进行监控的EnvironmentListener;用于维护Executor的存储状态的 StorageStatusListener;用于准备将Executor的信息展示在ExecutorsTab的ExecutorsListener;用于准备将Executor相关存储信息展示在BlockManagerUI的StorageListener等。最后创建SparkUI,SparkUI服务默认是可以被杀掉的,通过修改属性spark.ui.killEnabled为false可以保证不被杀死。initialize方法会组织前端页面各个Tab和Page的展示及布局,代码如下:
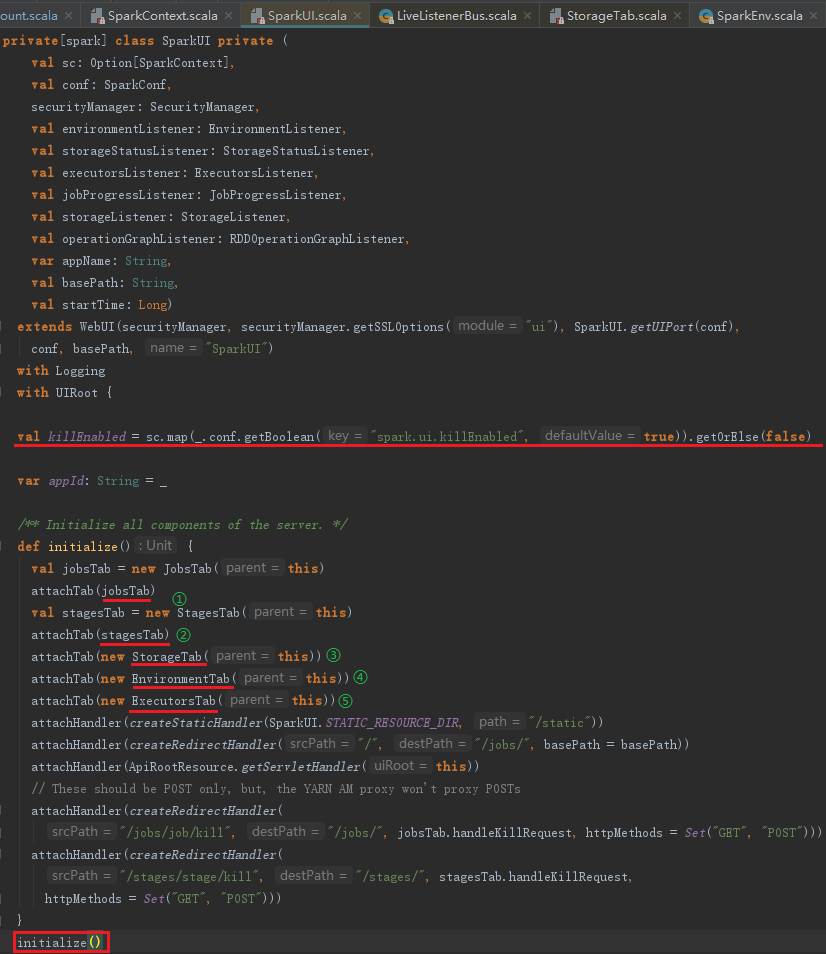
3.4 Spark UI的页面布局与展示
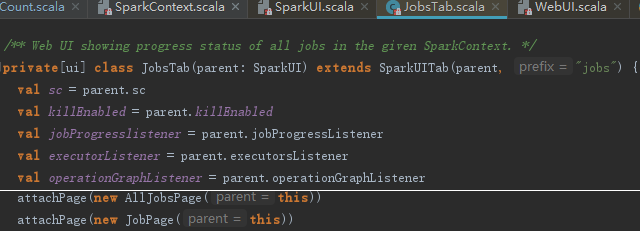
SparkUI究竟是如何实现页面布局及展示的?JobsTab展示所有Job的进度、状态信息,这里我们以它为例来说明。JobsTab会复用SparkUI的killEnabled、SparkContext、jobProressListener,包括AllJobsPage和JobPage两个页面,jobsTab的实现见代码:
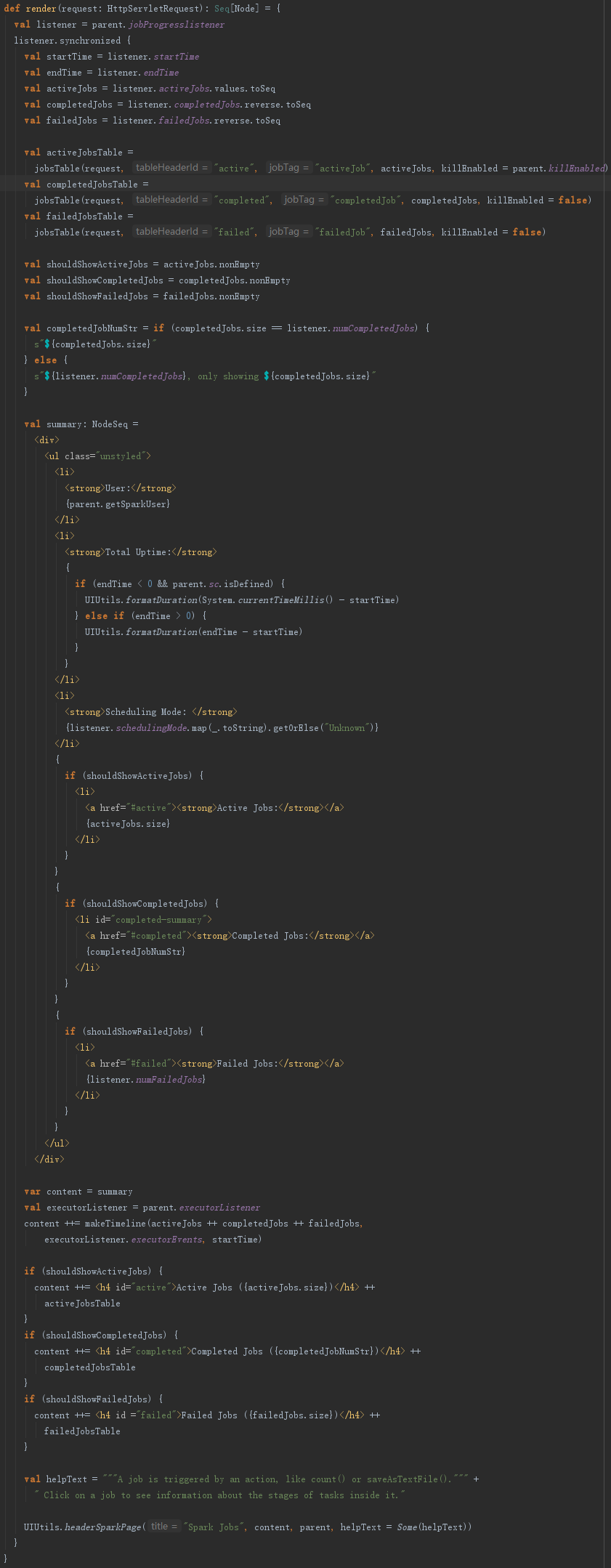
AllJobsPage由render方法渲染,利用jobProgressListener中的统计监控数据生成激活、完成、失败等状态的Job摘要信息,并调用jobsTable方法生成表格等html元素,最终使用UIUtils的headerSparkPage封装好css、js、header及页面布局等,AllJobsPage的render方法见代码如下:
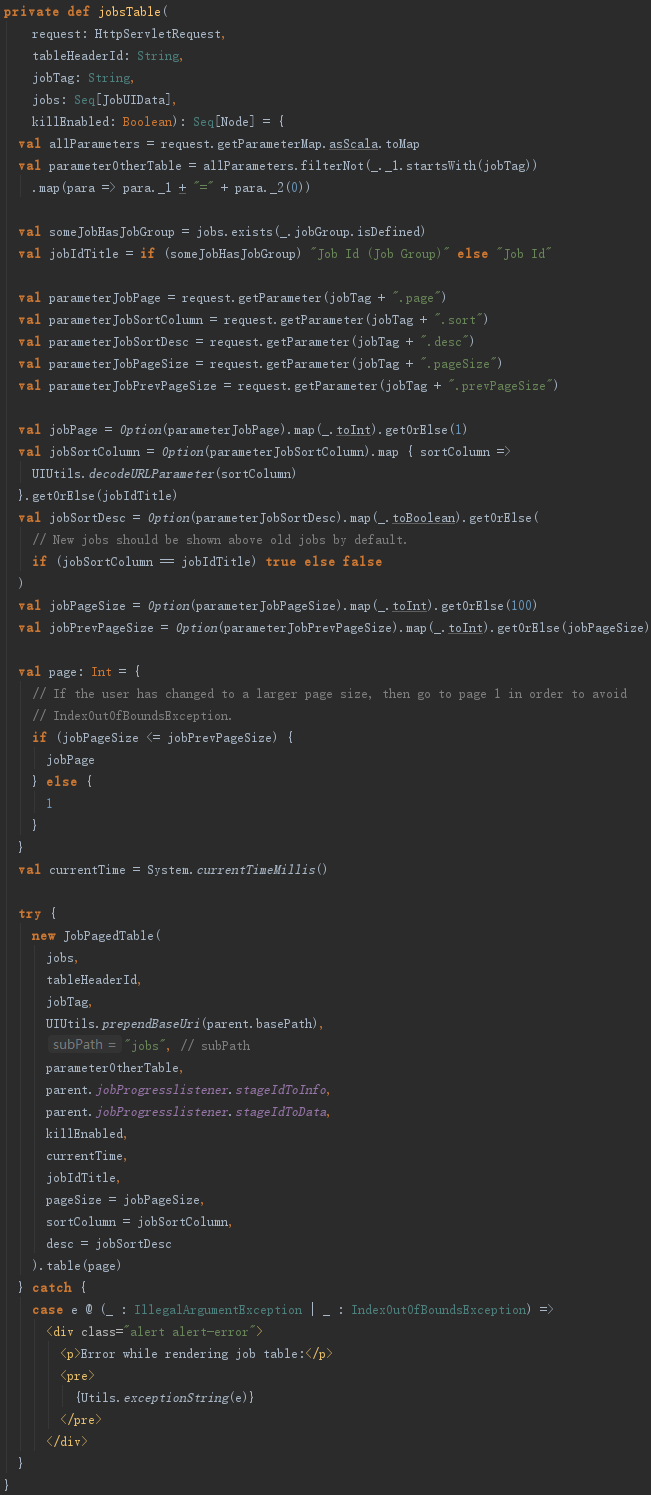
jobsTable用来生成表格数据,见代码如下:
JobsTab创建之后,将被方法attachTab方法加入SparkUI的ArrayBuffer[WebUITab]中,并且通过attachPage方法,给每一个page生成org.eclipse.jetty.servlet.ServletContextHandler,最后调用attachHandler方法将ServletContextHandler绑定到SparkUI,即加入到handlers:ArrayBuffer[ServletContextHandler]和样例类ServerInfo的rootHandler(ContextHandlerCollection)中。SparkUI继承自WebUI,attachTab方法在WebUI中实现,代码如下:
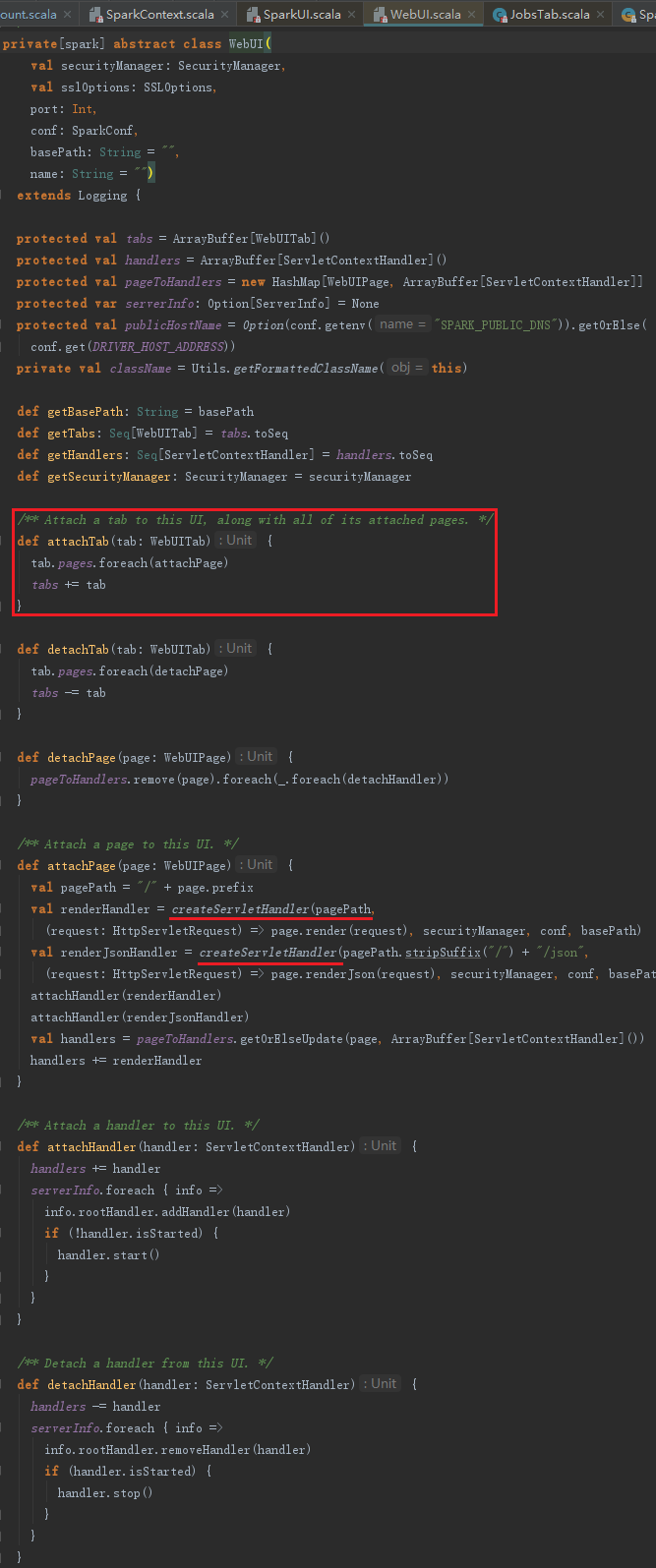
上述代码所在的类中使用import org.apache.spark.ui.JettyUtils._导入了JettyUtils的静态方法,所以createServletHandler方法实际是JettyUtils的静态方法createServletHandler。createServletHandler实际创建了javax.servlet.http.HttpServlet的匿名内部类实例,此实例实际使用(request: HttpServletRequest)=>page.render(request)函数参数来处理请求,进而渲染页面呈现给用户。
3.5 SparkUI的启动
SparkUI创建好后,需要调用父类WebUI的bind方法,绑定服务和端口,bind方法中主要的代码实现如下:
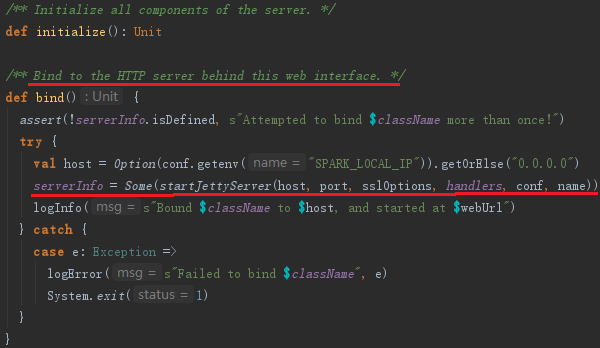
通过JettyUtils的静态方法startJettyServer启动了Jetty提供的服务,默认端口是4040。
查看:Spark源码剖析——SparkContext的初始化
参考资料:
《深入理解Spark核心思想与源码分析》
Spark源码剖析 - SparkContext的初始化(三)_创建并初始化Spark UI的更多相关文章
- Spark源码剖析 - SparkContext的初始化(二)_创建执行环境SparkEnv
2. 创建执行环境SparkEnv SparkEnv是Spark的执行环境对象,其中包括众多与Executor执行相关的对象.由于在local模式下Driver会创建Executor,local-cl ...
- Spark源码剖析 - SparkContext的初始化(一)
1. SparkContext概述 注意:SparkContext的初始化剖析是基于Spark2.1.0版本的 Spark Driver用于提交用户应用程序,实际可以看作Spark的客户端.了解Spa ...
- Spark源码剖析 - SparkContext的初始化(十)_Spark环境更新
12. Spark环境更新 在SparkContext的初始化过程中,可能对其环境造成影响,所以需要更新环境,代码如下: SparkContext初始化过程中,如果设置了spark.jars属性,sp ...
- Spark源码剖析 - SparkContext的初始化(五)_创建任务调度器TaskScheduler
5. 创建任务调度器TaskScheduler TaskScheduler也是SparkContext的重要组成部分,负责任务的提交,并且请求集群管理器对任务调度.TaskScheduler也可以看作 ...
- Spark源码剖析 - SparkContext的初始化(八)_初始化管理器BlockManager
8.初始化管理器BlockManager 无论是Spark的初始化阶段还是任务提交.执行阶段,始终离不开存储体系.Spark为了避免Hadoop读写磁盘的I/O操作成为性能瓶颈,优先将配置信息.计算结 ...
- Spark源码剖析 - SparkContext的初始化(九)_启动测量系统MetricsSystem
9. 启动测量系统MetricsSystem MetricsSystem使用codahale提供的第三方测量仓库Metrics.MetricsSystem中有三个概念: Instance:指定了谁在使 ...
- Spark源码剖析 - SparkContext的初始化(七)_TaskScheduler的启动
7. TaskScheduler的启动 第五节介绍了TaskScheduler的创建,要想TaskScheduler发挥作用,必须要启动它,代码: TaskScheduler在启动的时候,实际调用了b ...
- Spark源码剖析 - SparkContext的初始化(四)_Hadoop相关配置及Executor环境变量
4. Hadoop相关配置及Executor环境变量的设置 4.1 Hadoop相关配置信息 默认情况下,Spark使用HDFS作为分布式文件系统,所以需要获取Hadoop相关配置信息的代码如下: 获 ...
- Spark源码剖析 - SparkContext的初始化(六)_创建和启动DAGScheduler
6.创建和启动DAGScheduler DAGScheduler主要用于在任务正式交给TaskSchedulerImpl提交之前做一些准备工作,包括:创建Job,将DAG中的RDD划分到不同的Stag ...
随机推荐
- Linux查看实时网卡流量的几种方式
Linux查看实时网卡流量的几种方式 来源 https://www.jianshu.com/p/b9e942f3682c 在工作中,我们经常需要查看服务器的实时网卡流量.通常,我们会通过这几种方式查 ...
- 【BZOJ2618】[CQOI2006]凸多边形(半平面交)
[BZOJ2618][CQOI2006]凸多边形(半平面交) 题面 BZOJ 洛谷 题解 这个东西就是要求凸多边形的边所形成的半平面交. 那么就是一个半平面交模板题了. 这里写的是平方的做法. #in ...
- IP地址等价类测试用例
下面是一个比较完善的设计方案,这个方案中,首先把IP地址分成有效可用的IP地址和有效但不可用的IP地址两个等价类:其中有效可用的IP地址中包括IP地址的A,B,C三类地址,有效但不可用的IP地址包括D ...
- 【原创】hdu 1166 敌兵布阵(线段树→单点更新,区间查询)
学习线段树的第三天...真的是没学点啥好的,又是一道水题,纯模板,我个人觉得我的线段树模板还是不错的(毕竟我第一天相当于啥都没学...找了一整天模板,对比了好几个,终于找到了自己喜欢的类型),中文题目 ...
- 【Linux】Linux系统硬链接和软链接
在linux系统中有种文件是链接文件,可以为解决文件的共享使用.链接的方式可以分为两种,一种是硬链接(Hard Link),另一种是软链接或者也称为符号链接(Symbolic Link). 查看lin ...
- 对于submit text3运行Python脚本的解决方法
先抛出一些配置信息吧 电脑安装了Python2和Python3两种版本,并且还改了exe文件的名字,可能这与默认的submit text3配置不同了吧,导致错误. 先抛出一些错误吧 首先,自动CTRL ...
- LinkedList(JDK1.8)源码分析
双向循环链表 双向循环链表和双向链表的不同在于,第一个节点的pre指向最后一个节点,最后一个节点的next指向第一个节点,也形成一个"环".而LinkedList就是基于双向循环链 ...
- iview 模态框点击确定按钮不消失
<div slot="footer"> <Button type="text" size="large" @click=& ...
- 洛谷P1731 生日蛋糕
李煜东太神了啊啊啊啊啊! 生日蛋糕,著名搜索神题(还有虫食算). 当年的我30分.... 这哥们的程序0ms... 还有他的树网的核也巨TM神. 疯狂剪枝! DFS(int d, int s, int ...
- 爬虫 写入文件时遇到gbk编码错误
#获取视频地址 # 每次请求一次,然后写文件,这样可以规避多次请求触发反爬虫 r = requests.get('https://www.pearvideo.com/video_1522192') h ...