WebSplider在线爬虫
WebSplider是什么?
- WebSplider在线爬虫是一个结合Web技术与爬虫技术的项目。
- WebSplider支持Web页面进行爬虫配置,提交配置到服务器后,服务器端爬虫程序进行数据抓取,最后将结果返回给用户。
- WebSplider支持多种代理模式,有效保证了IP不被ban掉
- WebSplider支持生成数据接口API,方便用户调用爬虫爬到的数据
- WebSplider基于Node.js,使用superagent与cheerio进行数据请求分析
- 爬虫不能解决Ajax动态加载内容
WebSplider长得什么样?
WebSplider原理是什么?
动态网站中相似网页的网页结构都是有规律的。以京东为例,京东网站的每个产品详情页中,分析页面结构,可以看到产品名称的类名为sku-name。那么,如果想获得该产品的相关数据,用户只需给出目标网址,目标网页中数据所在的标签,使用标签选择器与属性选择器就可以得到该类名标签中的数据。根据这个特点,可以设计让用户自行观察网页结构,提供标签选择器与属性选择器,指定目标网页URL即可让爬虫抓取数据。
Web在线爬虫主要分为Web应用与爬虫程序两大模块。Web应用是用户与爬虫程序之间“联络人”,负责中转用户调用爬虫的请求与返回爬虫处理后的数据结果。
爬虫基于Node.js平台,使用Superagent请求初始页面URL,获得整个网页,使用Cheerio根据用户配置中的标签选择器与属性选择器分析页面,得到目标数据。
为了满足用户调用爬虫爬到的数据的需求,Web在线爬虫支持生成数据接口,这是一个返回爬虫爬取数据的URL。Web应用负责与数据库交互,数据库保存用户的爬虫配置。生成数据接口时,将爬虫配置写入数据库,请求数据接口时,从数据库获得配置,将配置设置到爬虫中进行爬取数据。为了提高响应速度,可以将爬虫爬取结果保存到数据库中,设置定时任务,定时调用爬虫程序爬取数据,更新数据库。当用户请求数据接口,直接从数据库取出数据进行响应。
WebSplider技术细节
WebSplider使用koa.js作为Web框架,使用superagent进行请求,Cheerio分析网页,mongodb存储数据。前端使用Vue.js
核心代码
WebSplider项目中使用koa.js,这里是express。东西差不多
var express = require('express');
var cheerio = require('cheerio');
var superagent = require('superagent');
var app = express();
var items = [];
app.get('/', function (req, res, next) {
superagent.get('https://cnodejs.org/')
.end(function (err, sres) {
if (err) {
return next(err);
}
var $ = cheerio.load(sres.text);
$('.topic_title').each(function (idx, element) {
var $element = $(element);
items.push({
title: $element.attr('title'),
url : $element.attr('href')
});
})
res.send(items);
})
})
app.listen(3000, function () {
console.log('app is listening at port 3000');
});
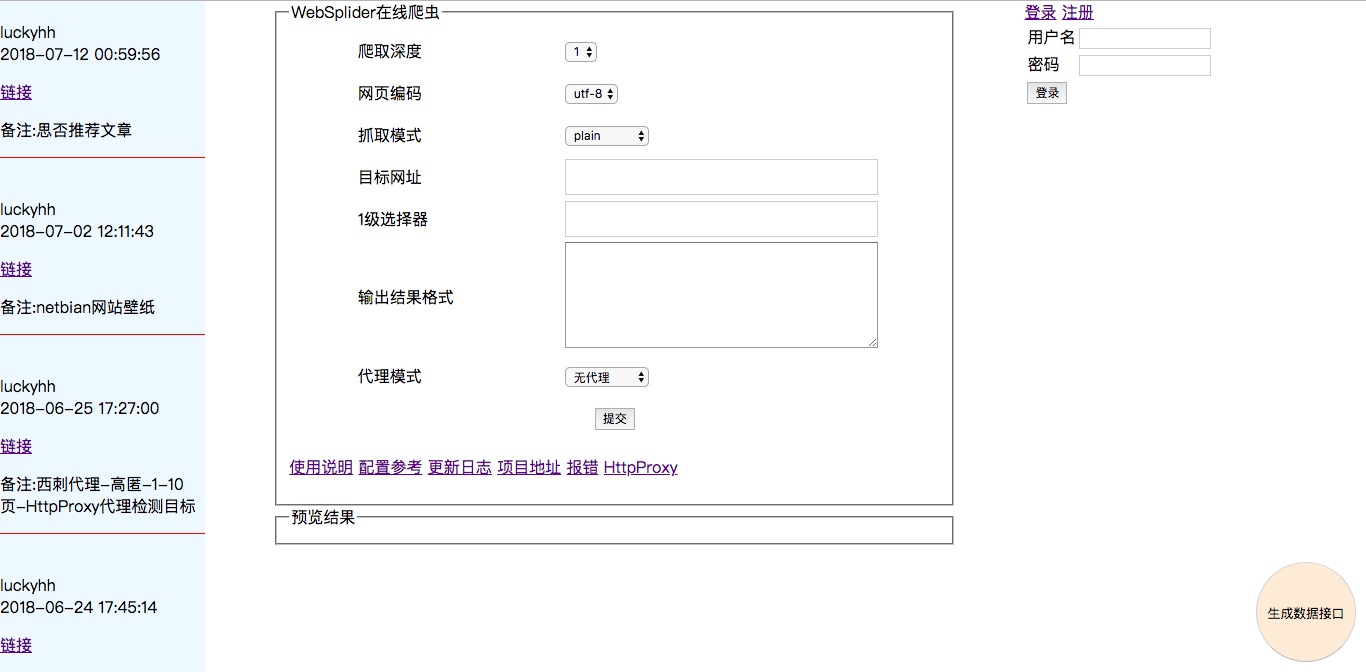
爬取深度
首先看爬虫获得数据的过程。它是由用户给出的初始URL与a标签选择器来找到目标数据的。
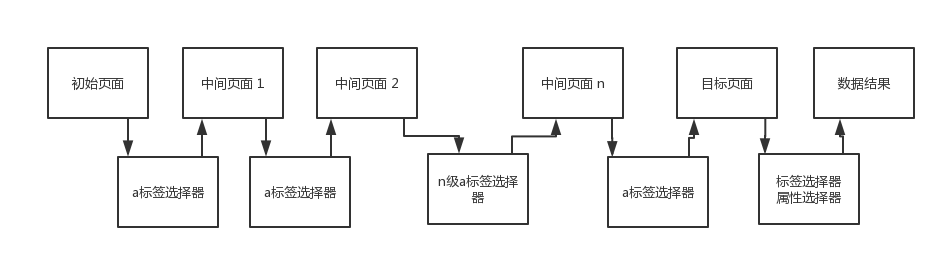
所以,在填写配置的页面,要指出初始页面到目标数据页的a标签选择器,在最后目标数据页,使用标签选择器与属性选择器就可以获得目标数据。
以澎湃新闻为例:
获取首页每个链接的文章详情。需要进入下一层链接才能获得文章数据。
所以“1级选择器”配置到下一层网页的a标签选择器。爬虫程序根据a标签选择器才能找到下一层链接。
“2级选择器”则配置数据所在的标签选择器。用于配合“输出结果定制”,获得数据。
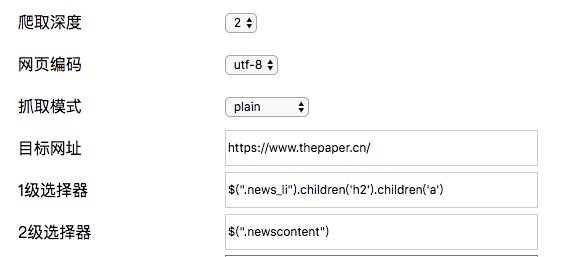
同样的道理,如果目标数据在下一层的下一层,则需要设置爬取深度为3.此时1级选择器与2级选择器都需要设置为a标签选择器。3级选择器是目标数据所在的标签选择器。
HTTP代理
对爬虫稍有研究的人会知道代理的重要性,它保证了我们的IP地址不被目标服务器ban掉。
superagent使用代理发出HTTP请求其实很容易实现,但如何获得大量的代理地址呢?网上有很多代理网站提供免费代理服务。比如:西刺代理,IP海等。但是代理质量参差不齐,可用的代理少之又少。
于是,我做了个小项目HttpProxy,用于检测代理是否可用。WebSplider爬虫爬取了西刺代理的大量代理地址,HttpProxy请求WebSplider提供的API获得这些地址数据,批量分析请求代理是否可用,分析之后,WebSplider请求HttpProxy提供的API,使用分析之后的代理地址进行请求代理。
WebSplider支持选择代理模式。无代理,西刺代理与自定义代理
输出结果格式
怎样让用户自定义自己想要的数据输出?我选择让用户自己根据标签选择器与属性选择器进行配置。
如下所示:
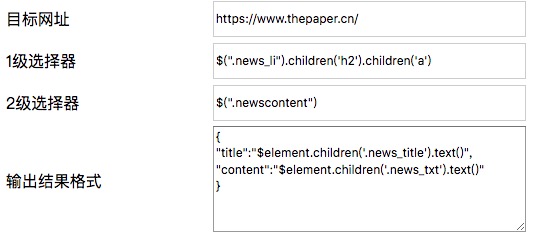
2级选择器指出目标数据在类名为newscontent的元素中。
输出结果定制中则指出了输出那些数据结果。是标准的JSON格式。
这里根据键名称,可以直观的看到我要得到的数据是文章标题与内容。
{
"title":"$element.children('.news_title').text()",
"content":"$element.children('.news_txt').text()"
}
以这个为例说一下写法
$element.children('.news_title').text()
$element是指上面2级选择器选择出的标签。这句话是说要得到类名为newscontent的元素中子元素类名为news_title的文本值。
更多标签选择器与属性选择器写法,参考Cheerio
其他
实例地址:
http://splider.docmobile.cn
项目地址:
https://github.com/LuckyHH/WebSplider
配置参考:
https://www.docmobile.cn/artical_detiail/luckyhh/1528369921460
基于WebSplider的新闻模块开发
https://www.docmobile.cn/artical_detiail/luckyhh/1528989508215
WebSplider在线爬虫的更多相关文章
- 七月在线爬虫班学习笔记(五)——scrapy spider的几种爬取方式
第五课主要内容有: Scrapy框架结构,组件及工作方式 单页爬取-julyedu.com 拼URL爬取-博客园 循环下页方式爬取-toscrape.com Scrapy项目相关命令-QQ新闻 1.S ...
- 七月在线爬虫班学习笔记(六)——scrapy爬虫整体示例
第六课主要内容: 爬豆瓣文本例程 douban 图片例程 douban_imgs 1.爬豆瓣文本例程 douban 目录结构 douban --douban --spiders --__init__. ...
- 七月在线爬虫班学习笔记(二)——Python基本语法及面向对象
第二课主要内容如下: 代码格式 基本语法 关键字 循环判断 函数 容器 面向对象 文件读写 多线程 错误处理 代码格式 syntax基本语法 a = 1234 print(a) a = 'abcd' ...
- Scrapy框架爬虫初探——中关村在线手机参数数据爬取
关于Scrapy如何安装部署的文章已经相当多了,但是网上实战的例子还不是很多,近来正好在学习该爬虫框架,就简单写了个Spider Demo来实践.作为硬件数码控,我选择了经常光顾的中关村在线的手机页面 ...
- 爬虫实战——Scrapy爬取伯乐在线所有文章
Scrapy简单介绍及爬取伯乐在线所有文章 一.简说安装相关环境及依赖包 1.安装Python(2或3都行,我这里用的是3) 2.虚拟环境搭建: 依赖包:virtualenv,virtualenvwr ...
- shell爬虫--抓取某在线文档所有页面
在线教程一般像流水线一样,页面有上一页下一页的按钮,因此,可以利用shell写一个爬虫读取下一页链接地址,配合wget将教程所有内容抓取. 以postgresql中文网为例.下面是实例代码 #!/bi ...
- Python爬虫教程-16-破解js加密实例(有道在线翻译)
python爬虫教程-16-破解js加密实例(有道在线翻译) 在爬虫爬取网站的时候,经常遇到一些反爬虫技术,比如: 加cookie,身份验证UserAgent 图形验证,还有很难破解的滑动验证 js签 ...
- python爬虫scrapy框架——爬取伯乐在线网站文章
一.前言 1. scrapy依赖包: 二.创建工程 1. 创建scrapy工程: scrapy staratproject ArticleSpider 2. 开始(创建)新的爬虫: cd Artic ...
- python爬虫之有道在线翻译
今天初学了python这门课 老师简单的讲解了一下 python的安装环境,配置环境变量,当前主流Python使用的是3.x版本, 下午简单的讲解了python的起源,发展以及在各个方面的应用 然后晚 ...
随机推荐
- 向Sql Server数据库插入中文时显示乱码的解决办法 (转)
转自:http://blog.csdn.net/wizardlun/article/details/4577658 參考:http://shareideas.blog.51cto.com/362642 ...
- The 10 Best Neighborhoods in Seattle
https://www.seattlemet.com/articles/2015/4/24/the-10-best-neighborhoods-in-seattle-may-2015 By Darre ...
- windows下,怎么轻易拷贝一个文件的完整路径?
1. 到目录下,复制文件 2. win+R ,打开"运行"输入框 3.ctrl+v
- 在阿里云Windows Server 上部署ASP .NET CORE2.0项目
近期使用ASP.NET Core2.0对博客进行了重写,在部署到服务器时遇到了一些问题,来记录一下留用. 配置环境 安装 .Net Framework3.5 在IIS管理器上直接开启,这里总是失败,上 ...
- python3: 迭代器与生成器(1)
1. 手动遍历迭代器 你想遍历一个可迭代对象中的所有元素,但是却不想使用for循环. >>> items = [1, 2, 3] >>> # Get the ite ...
- BZOJ 1085 骑士精神 迭代加深搜索+A*
题目链接: https://www.lydsy.com/JudgeOnline/problem.php?id=1085 题目大意: 在一个5×5的棋盘上有12个白色的骑士和12个黑色的骑士, 且有一个 ...
- 「2017 山东一轮集训 Day5」字符串
题目 比较神仙的操作啊 首先先考虑一个串的做法,我们有两种:SA或SAM,其中SAM又有两种,拓扑图上的\(dp\)和\(parent\)上随便统计一下 显然这道题\(SA\)和\(parent\)树 ...
- Jmeter函数助手中添加自定义函数
最近,群里的牛肉面大神有个需求,是将每个post请求的body部分做一个加密操作,其实这个需求不算难,用beanshell引入加密函数的包,然后调用就行了.只是,如果请求多了,每次都要调用一下自己加密 ...
- 6、JUC--同步锁Lock
显示锁 Lock 在Java 5.0之前,协调共享对象的访问时可以使用的机 制只有 synchronized 和 volatile .Java 5.0 后增加了一些 新的机制,但并不是一种替代内置 ...
- Python高级网络编程系列之基础篇
一.Socket简介 1.不同电脑上的进程如何通信? 进程间通信的首要问题是如何找到目标进程,也就是操作系统是如何唯一标识一个进程的! 在一台电脑上是只通过进程号PID,但在网络中是行不通的,因为每台 ...