scrapy架构流程
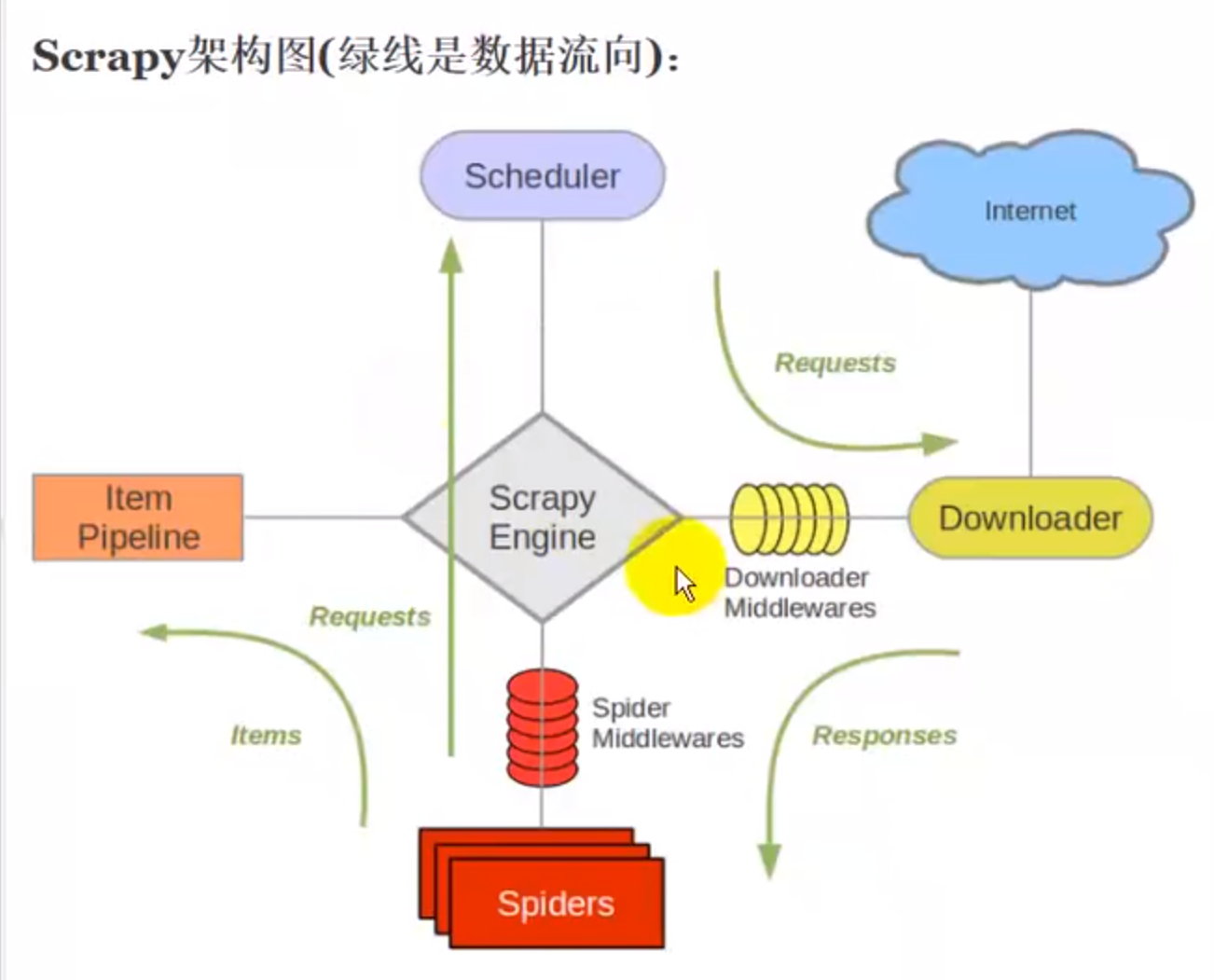
1.爬虫spiders将请求通过引擎传递给调度器scheduler
2.scheduler有个请求队列,在请求队列中拿出请求给下载器,downloader
3.downloader从Internet的服务器端请求数据,下载下来
4.下载下来的响应体交还给我们自己写的spiders,对响应体做相应的处理
5.响应体处理后有两种情况,1):如果是数据,交给pipeline管道,处理数据 2):如果是请求,接着交给调度器放到请求队列中等待处理,然后交给下载器处理,如此循环,直到没有请求产生
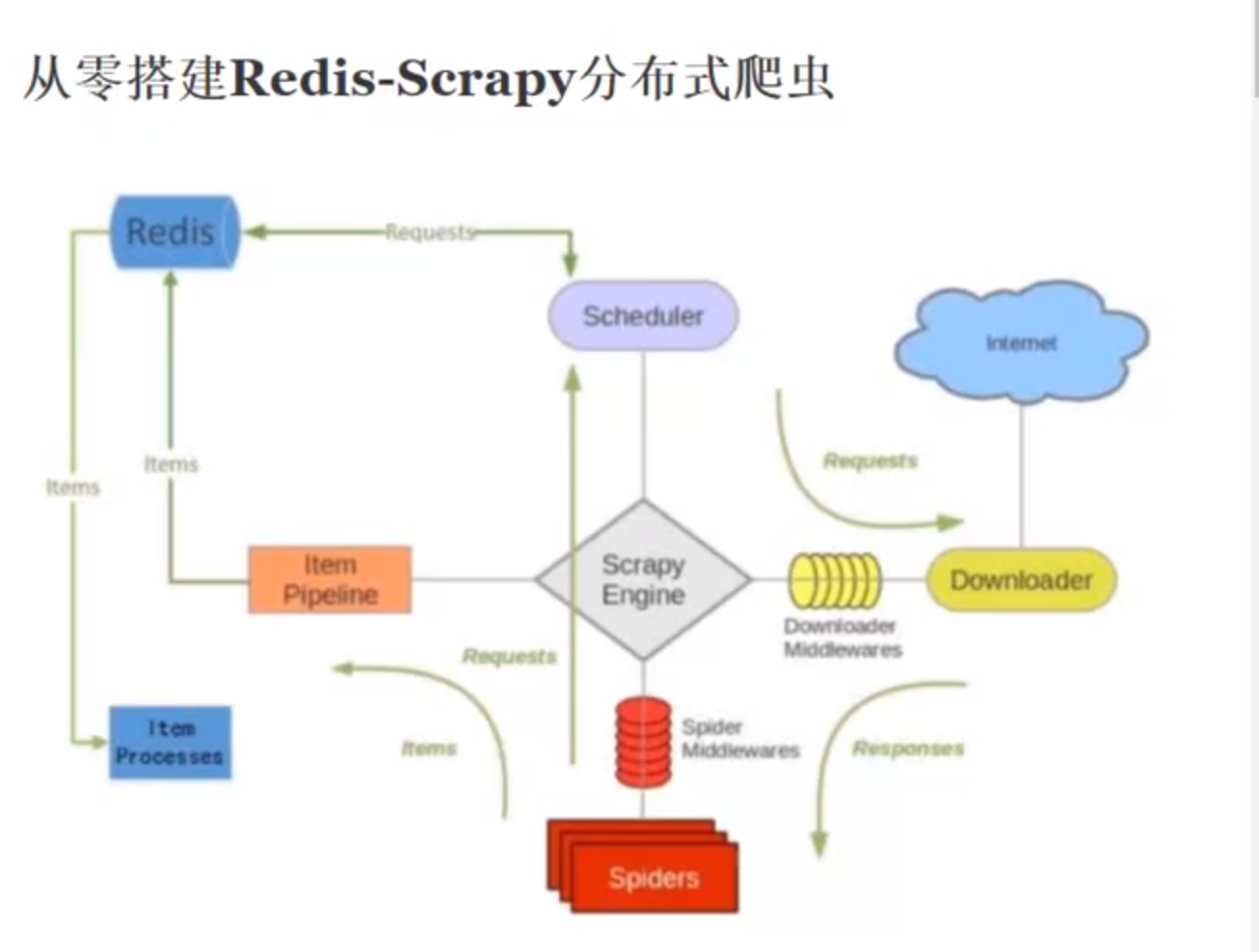
redis-scrapy是基于scrapy框架的一套组件
scrapy是一个通用的爬虫框架,不支持分布式操作,scrapy-redis是为了更方便的是scrapy进行分布式的爬取,而提供了一些以redis为基础的组件(仅有组件)
scrapy提供了四种组件(components),四种组件也就意味这四个模块都要做相应的修改:
- scheduler
- duplication filter
- item pipeline
- base spider
scrapy的去重是在内存中执行的,如果请求量非常大的时候,scrapy占用的内存会非常高,如果我们把这个去重的指纹队列放到redis数据库中的话就会很方便了
scrapy中的数据是交给pipeline来处理的,在scrapy-redis中,数据是直接存储到redis数据库中的,然后我们对数据进行处理持久化到mongodb中或者mysql中,因为redis也是基于内存的存储,不适合持久化数据
Scheduler:
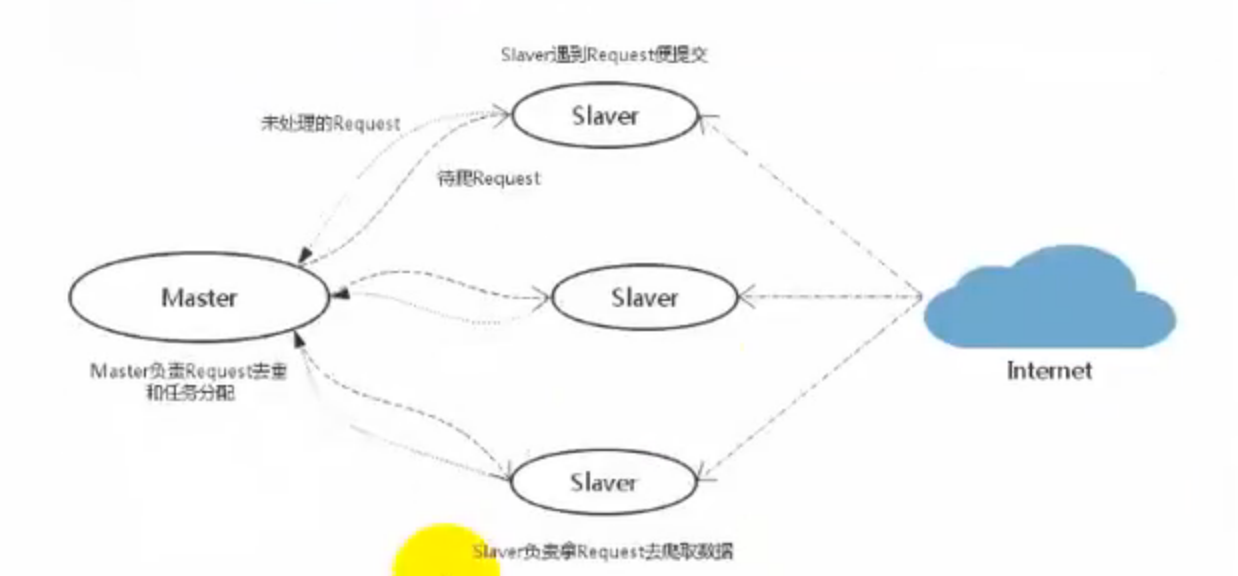
scrapy改造了python本来的collection.deque(双向队列)形成了自己的scrapy queue,但是scrapy多个spider不能共享待爬取队列scrapy queue,即scrapy本身不支持爬取分布式,scrapy-redis的解决是把这个scrapy queue换成redis数据库(也是指redis队列),从同一个redis-server存放要爬取的request,便能让多个spider从同一个数据库中读取。
scrapy中跟待爬队列直接相关的就是调度器scheduler,它把新的request进行入列操作,放到scrapy queue中,把要爬取的request取出,从scrapy queue中取出,它把待爬队列按照优先级建立了一种字典结构
{
优先级0:队列0
优先级1:队列1
优先级2:队列2
}
然后根据request中的优先级,来决定该入到哪个队列中,出列时则是按照优先级较小的优先出列。对于这个较高级别的队列结构,scrapy要提供一系列的方法来管理它,原有的scrapy scheduler以无法满足,此时需要使用scrapy-redis中的scheduler组件。
duplication filter:
scrapy中用集合来实现request的去重功能。scrapy中将已经发送的request指纹信息放入到set中,然后把将要发送的request指纹信息和set中的进行比较,如果存在则返回,否则继续进行操作。核心实现功能代码如下:
def request_seen(self,request):
#self.request_figerprints就是一个指纹集合
fp=self.request_fingerprint(request) #这就是判重的核心操作
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp+os.linesep)



scrapy架构流程的更多相关文章
- scrapy架构初探
scrapy架构初探 引言 Python即时网络爬虫启动的目标是一起把互联网变成大数据库.单纯的开放源代码并不是开源的全部,开源的核心是"开放的思想",聚合最好的想法.技术.人员, ...
- Scrapy架构概述
Scrapy架构概述 1, 从最初自己编写的spiders,获取到start_url,并且封装成Request对象. 2,通过engine(引擎)调度给SCHEDULER(Requests管理调度器) ...
- scrapy架构简介
一.scrapy架构介绍 1.结构简图: 主要组成部分:Spider(产出request,处理response),Pipeline,Downloader,Scheduler,Scrapy Engine ...
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图 1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scra ...
- Python -- Scrapy 架构概览
架构概览 本文档介绍了Scrapy架构及其组件之间的交互. 概述 接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示). 下面对每个组件都做了简单介绍,并给出了详 ...
- 二十四 Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scrapy架构源码分析图
- 一:SpringMVC架构流程
架构流程: 1.用户发送请求至前端控制器DispatcherServlet 2.DispatcherServlet收到请求调用HandlerMapping处理器映射器. 3.处理器映射器根据请求url ...
- 爬虫---scrapy架构和原理
scrapy是一个为了爬取网站数据, 提取结构性数据而编写的应用框架, 它是基于Twisted框架开发而来, 而Twisted框架是事件驱动的, 比较适合异步代码. 对会阻塞线程的操作, 包括访问数据 ...
- scrapy架构与目录介绍、scrapy解析数据、配置相关、全站爬取cnblogs数据、存储数据、爬虫中间件、加代理、加header、集成selenium
今日内容概要 scrapy架构和目录介绍 scrapy解析数据 setting中相关配置 全站爬取cnblgos文章 存储数据 爬虫中间件和下载中间件 加代理,加header,集成selenium 内 ...
随机推荐
- Codeforces 889F Letters Removing(二分 + 线段树 || 树状数组)
Letters Removing 题意:给你一个长度为n的字符串,然后进行m次删除操作,每次删除区间[l,r]内的某个字符,删除后并且将字符串往前补位,求删除完之后的字符串. 题解:先开80个set ...
- HZNU Training 2 for Zhejiang Provincial Collegiate Programming Contest 2019
赛后总结: T:今天下午参加了答辩比赛,没有给予队友很大的帮助.远程做题的时候发现队友在H上遇到了挫折,然后我就和她们说我看H吧,她们就开始做了另外两道题.今天一人一道题.最后我们在研究一道dp的时候 ...
- 2018中国大学生程序设计竞赛 - 网络选拔赛 hdu6438 Buy and Resell 买入卖出问题 贪心
Buy and Resell Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)To ...
- Atcoder C - Nuske vs Phantom Thnook(递推+思维)
题目链接:http://agc015.contest.atcoder.jp/tasks/agc015_c 题意:给一个n*m的格,蓝色的组成路径保证不成环,q个询问,计算指定矩形区域内蓝色连通块的个数 ...
- hdu3746(kmp最小循环节)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3746 题意:问在一个字符串末尾加上多少个字符能使得这的字符串首尾相连后能够循环 题解:就是利用next ...
- SpringBoot整合ActiveMQ,看这篇就够了
ActiveMQ是Apache提供的一个开源的消息系统,完全采用Java来实现,因此它能很好地支持JMS(Java Message Service,即Java消息服务)规范:本文将详细介绍下Activ ...
- Monte-Carlo Dropout
Monte-Carlo Dropout Monte-Carlo Dropout(蒙特卡罗 dropout),简称 MC dropout. 一种从贝叶斯理论出发的 Dropout 理解方式,将 Drop ...
- Oracle 实用SQL
start with connect by prior 递归查询用法 select * from 表名 aa start with aa.id = 'xxx' connect by prior aa. ...
- AWGN
高斯白噪声的功率谱密度服从均匀分布,幅度分布服从高斯分布: 白噪声是指它的二阶矩不相关,一阶矩为常数,是指先后信号在时间上的相关性: 高斯白噪声在任意两个不同时刻上的随机变量之间,不仅是互不相关的,而 ...
- .Net基础篇_学习笔记_第五天_流程控制while循环002
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...