Spark GraphX图计算核心算子实战【AggreagteMessage】
一.简介
参考博客:https://www.cnblogs.com/yszd/p/10186556.html
二.代码实现
package graphx
import org.apache.log4j.{Level, Logger}
import org.apache.spark.graphx.util.GraphGenerators
import org.apache.spark.sql.SparkSession
/**
* Created by Administrator on 2019/10/22.
*/
object AggregateMessage {
/**
* 设置日志级别为WARN
*/
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
/**
* 创建spark入口
*/
val spark = SparkSession.builder().appName("AggregateMessage").master("local[2]").getOrCreate()
val sc = spark.sparkContext
/**
* 随机生成图,默认出度为4,标准偏差为1.3,并行生成numVertices,partition默认为sc的默认partition
*/
val graph = GraphGenerators.logNormalGraph(sc, numVertices = 100).mapVertices((id, _) => id.toDouble)
graph.vertices.take(5).foreach(println)
/**
* 将用户定义的sendMsg函数应用于图形中的每个边三元组,然后使用mergeMsg函数汇聚信息到目标顶点
*/
val olderFollowers = graph.aggregateMessages[(Int, Double)](triplet =>{
if(triplet.srcAttr > triplet.dstAttr){
triplet.sendToDst(1, triplet.srcAttr)
}
},
(a, b) => (a._1 + b._1, a._2 + b._2)
)
/**
* 求平均值
*/
val avgAgeOfOlderFollowers = olderFollowers.mapValues((id, value) => value match {case (count, totalAge) => totalAge / count})
/**
* 输出结果
*/
avgAgeOfOlderFollowers.collect().take(5).foreach(println)
}
}
三.结果
随机生成的顶点数据:
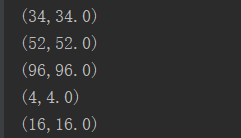
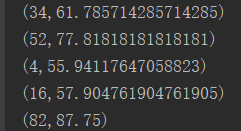
聚合结果:
Spark GraphX图计算核心算子实战【AggreagteMessage】的更多相关文章
- Spark GraphX图计算核心源码分析【图构建器、顶点、边】
一.图构建器 GraphX提供了几种从RDD或磁盘上的顶点和边的集合构建图形的方法.默认情况下,没有图构建器会重新划分图的边:相反,边保留在默认分区中.Graph.groupEdges要求对图进行重新 ...
- Spark GraphX图计算简单案例【代码实现,源码分析】
一.简介 参考:https://www.cnblogs.com/yszd/p/10186556.html 二.代码实现 package big.data.analyse.graphx import o ...
- GraphX 图计算实践之模式匹配抽取特定子图
本文首发于 Nebula Graph Community 公众号 前言 Nebula Graph 本身提供了高性能的 OLTP 查询可以较好地实现各种实时的查询场景,同时它也提供了基于 Spark G ...
- spark graphX作图计算
一.使用graph做好友推荐 import org.apache.spark.graphx.{Edge, Graph, VertexId} import org.apache.spark.rdd.RD ...
- Spark GraphX图处理编程实例
所构建的图如下: Scala程序代码如下: import org.apache.spark._ import org.apache.spark.graphx._ // To make some of ...
- Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈与熟练的掌握Scala语言【大数据Spark实战高手之路】
Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈 大数据的概念与应用,正随着智能手机.平板电脑的快速流行而日渐普及,大数据中图的并行化处理一直是一个非常热门的话题.图计算正在被广泛地应用于社交 ...
- Spark—GraphX编程指南
Spark系列面试题 Spark面试题(一) Spark面试题(二) Spark面试题(三) Spark面试题(四) Spark面试题(五)--数据倾斜调优 Spark面试题(六)--Spark资源调 ...
- Spark GraphX企业运用
========== Spark GraphX 概述 ==========1.Spark GraphX是什么? (1)Spark GraphX 是 Spark 的一个模块,主要用于进行以图为核心的计 ...
- Spark + GraphX + Pregel
Spark+GraphX图 Q:什么是图?图的应用场景 A:图是由顶点集合(vertex)及顶点间的关系集合(边edge)组成的一种网状数据结构,表示为二元组:Gragh=(V,E),V\E分别是顶点 ...
随机推荐
- java中利用POI读写excel2007需要导入的jar
1.下载POI模块:http://poi.apache.org/download.html 2.解压并导入以下包: 导入不会时会报错.
- 创建war类型项目(六)
1. 创建maven project时选择packaging为war: 2. 在webapp文件夹下新建META-INF和WEB-INF/web.xml web.xml模板 <?xml vers ...
- Machine Learning in Finance – Present and Future Applications
https://emerj.com/ai-sector-overviews/machine-learning-in-finance/ Machine learning has had fruitful ...
- 记一次排错经历,requests和fake_useragent
在部署tornado项目上线时, 首次重启服务后第一次请求必然会报错, 后续的就能正常访问, 长报错urllib.error.URLError,如图排查多次依然发现不了问题 报的最多的依然是上图中的错 ...
- JAVA还没死的原因
尽管 TIOBE 指数显示,Java 是一门正在衰落的语言,但它仍然稳居榜首.从 2016 年到 2017 年间,这个数字可能会大幅下降,但最近下降速度有所放缓:在 2018 年 10 月到 2019 ...
- [C/C++]大小端字节序转换程序
计算机数据存储有两种字节优先顺序:高位字节优先(称为大端模式)和低位字节优先(称为小端模式). 大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿 ...
- stringstream字符串流的妙用
现在有一个数组,其值为从1到10000的连续增长的数字.出于某次偶然操作,导致这个数组中丢失了某三个元素,同时顺序被打乱,现在需要你用最快的方法找出丢失的这三个元素,并且将这三个元素根据从小到大重新拼 ...
- [LeetCode] 402. Remove K Digits 去掉K位数字
Given a non-negative integer num represented as a string, remove k digits from the number so that th ...
- [LeetCode] 279. Perfect Squares 完全平方数
Given a positive integer n, find the least number of perfect square numbers (for example, 1, 4, 9, 1 ...
- K8s 集群安装(一)
01,集群环境 三个节点 master node1 node2 IP 192.168.0.81 192.168.0.82 192.168.0.83 环境 centos 7 centos 7 cen ...