【Python】Python简易爬虫爬取百度贴吧图片
通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地。(Python版本为3.6.0)
一.获取整个页面数据
def getHtml(url):
page=urllib.request.urlopen(url)
html=page.read()
return html
说明:
向getHtml()函数传递一个网址,就可以把整个页面下载下来.
urllib.request 模块提供了读取web页面数据的接口,我们可以像读取本地文件一样读取www和ftp上的数据.
二.筛选页面中想要的数据
在百度贴吧找到了几张漂亮的图片,想要下载下来.使用火狐浏览器,在图片位置鼠标右键单单击有查看元素选项,点进去之后就会进入开发者模式,并且定位到图片所在的前段代码
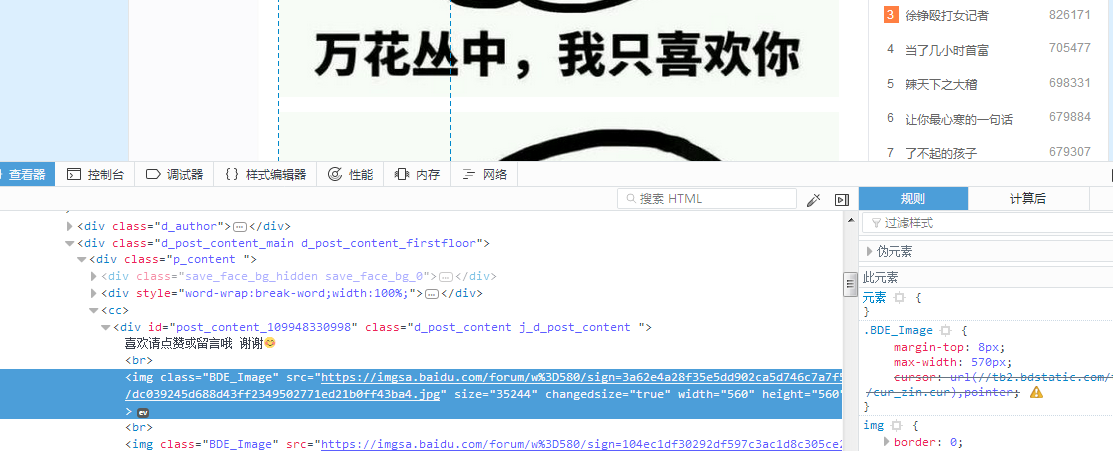
现在主要观察图片的正则特征,编写正则表达式.
reg=r'src="(https://imgsa[^>]+\.(?:jpeg|jpg))"'
#参考正则
编写代码
def getImg(html):
reg=r'src="(https://imgsa[^>]+\.(?:jpeg|jpg))"'
imgre = re.compile(reg)
imglist = re.findall(imgre,html.decode('utf-8'))
return imglist
说明:
re.compile() 可以把正则表达式编译成一个正则表达式对象.
re.findall() 方法读取html 中包含 imgre(正则表达式)的数据。
运行脚本将得到整个页面中包含图片的URL地址。
三.将页面筛选的数据保存到本地
编写一个保存的函数
def saveFile(x):
if not os.path.isdir(path):
os.makedirs(path)
t = os.path.join(path,'%s.img'%x)
return t
完整代码:
'''
Created on 2017年7月15日 @author: Administrator
'''
import urllib.request,os
import re def getHtml(url):
page=urllib.request.urlopen(url)
html=page.read()
return html path='D:/workspace/Python1/reptile/__pycache__/img' def saveFile(x):
if not os.path.isdir(path):
os.makedirs(path)
t = os.path.join(path,'%s.img'%x)
return t html=getHtml('https://tieba.baidu.com/p/5248432620') print(html) print('\n') def getImg(htnl):
reg=r'src="(https://imgsa[^>]+\.(?:jpeg|jpg))"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html.decode('utf-8'))
x=0
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,saveFile(x))
print(imgurl)
x+=1
if x==23:
break
print(x)
return imglist getImg(html)
print('end')
核心是用到了urllib.request.urlretrieve()方法,直接将远程数据下载到本地
【Python】Python简易爬虫爬取百度贴吧图片的更多相关文章
- Python简易爬虫爬取百度贴吧图片
通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地.(Python版本为3.6.0) 一.获取整个页面数据 def getHtml(url): page=urllib.requ ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- python爬虫—爬取百度百科数据
爬虫框架:开发平台 centos6.7 根据慕课网爬虫教程编写代码 片区百度百科url,标题,内容 分为4个模块:html_downloader.py 下载器 html_outputer.py 爬取数 ...
- Python爬虫爬取百度贴吧的帖子
同样是参考网上教程,编写爬取贴吧帖子的内容,同时把爬取的帖子保存到本地文档: #!/usr/bin/python#_*_coding:utf-8_*_import urllibimport urlli ...
- python简单爬虫爬取百度百科python词条网页
目标分析:目标:百度百科python词条相关词条网页 - 标题和简介 入口页:https://baike.baidu.com/item/Python/407313 URL格式: - 词条页面URL:/ ...
- Python爬虫爬取百度贴吧的图片
根据输入的贴吧地址,爬取想要该贴吧的图片,保存到本地文件夹,仅供参考: #!/usr/bin/python#_*_coding:utf-8_*_import urllibimport urllib2i ...
- Python编写网页爬虫爬取oj上的代码信息
OJ升级,代码可能会丢失. 所以要事先备份. 一開始傻傻的复制粘贴, 后来实在不能忍, 得益于大潇的启示和聪神的原始代码, 网页爬虫走起! 已经有段时间没看Python, 这次网页爬虫的原始代码是 p ...
随机推荐
- 【EXCEL】XMLファイルを開く方法(XML文件打开方法)
前言 XMLとは:Extensible Markup Language(エクステンシブル マークアップ ランゲージ)は.基本的な構文規則を共通とすることで.任意の用途向けの言語に拡張することを容易とし ...
- 博科Brocade 300光纤交换机配置zone教程
光纤交换机作为SAN网络的重要组成部分,在日常应用中非常普遍,本次将以常用的博科交换机介绍基本的配置方法. 博科300实物图: 环境描述: 如上图,四台服务器通过各自的双HBA卡连接至两台博科300光 ...
- Java 高级应用编程 第一章 工具类
一.Java API Java API简介 1.API (Application Programming Interface) 应用程序接口 2.Java中的API,就是JDK提供的各种功能的Java ...
- FPGA学习之路——PLL的使用
锁相环(PLL)主要用于频率综合,使用一个 PLL 可以从一个输入时钟信号生成多个时钟信号. PLL 内部的功能框图如下图所示: 在ISE中新建一个PLL的IP核,设置四个输出时钟,分别为25MHz. ...
- 无限滚动HTML UL结构
http://framework7.taobao.org/docs/infinite-scroll.html#.VUjA7NOqqko
- 【原创】Odoo开发文档学习之:构建接口扩展(Building Interface Extensions)(边Google翻译边学习)
构建接口扩展(Building Interface Extensions) 本指南是关于为Odoo的web客户创建模块. 要创建有Odoo的网站,请参见建立网站;要添加业务功能或扩展Odoo的现有业务 ...
- How To Install Apache Tomcat 7 on CentOS 7 via Yum
摘自:https://www.digitalocean.com/community/tutorials/how-to-install-apache-tomcat-7-on-centos-7-via-y ...
- sqlserver 循环赋值变量
sql server 是可以用 @变量 +=值的: 第一:必须在循环里面, 第二: 必须在循环外面初始化变量的值 如: @变量=''; 这样才能循环给值
- lesson 16 Mary had a little lamb
lesson 16 Mary had a little lamb a little + 可数 小的;+ 不可数 少量的 对于动物在幼时都有不同的称呼: calf 小牛 lamb 羊羔 piglet 小 ...
- STL之--插入迭代器(back_inserter,inserter,front_inserter的区别)
除了普通迭代器,C++标准模板库还定义了几种特殊的迭代器,分别是插入迭代器.流迭代器.反向迭代器和移动迭代器,定义在<iterator>头文件中,下面主要介绍三种插入迭代器(back_in ...