Python知乎热门话题爬取
本例子是参考崔老师的Python3网络爬虫开发实战写的
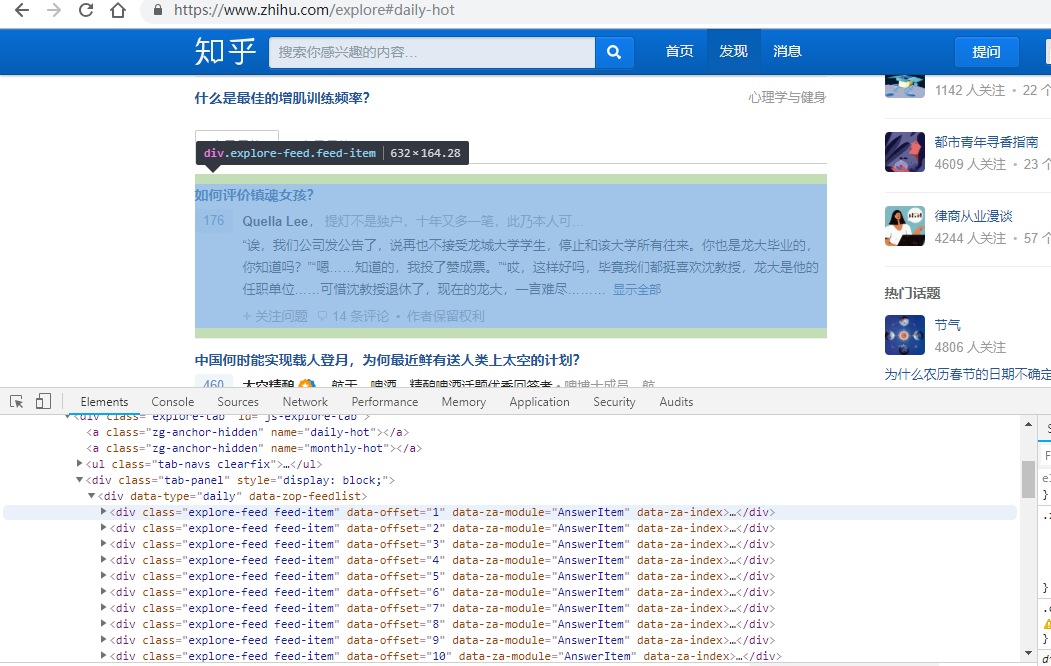
看网页界面:
热门话题都在 explore-feed feed-item的div里面
源码如下:
import requests
from pyquery import PyQuery as pq url='https://www.zhihu.com/explore' #今日最热
#url='https://www.zhihu.com/explore#monthly-hot' #本月最热
headers={
'User-Agent':"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
}
html=requests.get(url,headers=headers).text
doc=pq(html)
#print(doc)
items=doc('.explore-feed.feed-item').items()
for item in items:
question=item.find('h2').text()
#获取问题
print(question)
author=item.find('.author-link').text()
#获取作者
print(author)
answer=pq(item.find('.content').html()).text()
#获取答案(老师写的没看懂,可能需要jquery知识)
print(answer)
print('===='*10)
answer1=item.find('.zh-summary').text()
#自己写的获取答案。。。
print(answer1) #第一种写入方法
file=open('知乎.txt','a',encoding='utf-8')
file.write('\n'.join([question,author,answer]))
file.write('\n'+'****'*50+'\n')
file.close() #第二种写入方法 不需要写关闭方法
with open('知乎.txt','a',encoding='utf-8') as fp:
fp.write('\n'.join([question, author, answer]))
fp.write('\n' + '****' * 50 + '\n')
运行结果如下:

不过比较奇怪的地方是 url为今日最热和本月最热 所爬取的结果一模一样。。而且都只能爬下五个div里面的东西,可能是因为知乎是动态界面。需要用到selenium吧
还有就是
answer=pq(item.find('.content').html()).text()
#获取答案(老师写的没看懂,可能需要jquery知识)
这行代码没有看懂。。。。
还得学习jQuery
Python知乎热门话题爬取的更多相关文章
- Python知乎热门话题数据的爬取实战
import requestsfrom pyquery import PyQuery as pq url = 'https://www.zhihu.com/explore'headers = { 'u ...
- Python爬虫入门教程 26-100 知乎文章图片爬取器之二
1. 知乎文章图片爬取器之二博客背景 昨天写了知乎文章图片爬取器的一部分代码,针对知乎问题的答案json进行了数据抓取,博客中出现了部分写死的内容,今天把那部分信息调整完毕,并且将图片下载完善到代码中 ...
- Python爬虫——request实例:爬取网易云音乐华语男歌手top10歌曲
requests是python的一个HTTP客户端库,跟urllib,urllib2类似,但比那两个要简洁的多,至于request库的用法, 推荐一篇不错的博文:https://cuiqingcai. ...
- Python网络爬虫与如何爬取段子的项目实例
一.网络爬虫 Python爬虫开发工程师,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 【学习笔记】Python 3.6模拟输入并爬取百度前10页密切相关链接
[学习笔记]Python 3.6模拟输入并爬取百度前10页密切相关链接 问题描述 通过模拟网页,实现百度搜索关键词,然后获得网页中链接的文本,与准备的文本进行比较,如果有相似之处则代表相关链接. me ...
随机推荐
- Pycharm使用中背景颜色和更改项目的Python版本
一.背景颜色 颜色是每一个人都会去更改的,而且可以保护眼睛! 第二步: 选择图中画框的位置,便可以更改背景颜色! 二.项目版本的更改: python2 和 python3 有很大的不同,使用pytho ...
- hydra 常用的命令
1.本地调试模式运行项目 /gaea hydra /zk节点名 -r "zk://zk地址" -t "节点标识" -d -w 项目相对于$GOPATH/src ...
- VSTO 开发中 应用ActionPane、CustomTaskPane
以Excel插件为例: 1. ActionPane 创建 ThisWorkbook 项目 private void ThisWorkbook_Startup(object sender, System ...
- sql执行计划变更和删除缓存中执行计划的方法
将指定SQL的执行计划从共享池删除的方法 http://www.2cto.com/database/201204/126388.html Oracle SQL执行计划变更的问题 http://www. ...
- 名词后变为复数+s,或者+es等怎么读
, 以ce,se,ze, (d)ge等结尾的词 加 -s 读 /iz/ license-licenses, office offices 最佳答案1: 当名词后加-e(-es)变成复数,动词单数第三人 ...
- SAP S/4HANA生产订单的BAdI增强点之Initialize方法
在S/4HANA里创建生产订单时,有一个增强点WORKORDER_UPDATE: 这个CAUFVDB里存放的是生产订单抬头级别的数据: 我们来观察下运行时这个结构里存放的数据. 请大家用我github ...
- IOS UIWebView(浏览器控件)
什么是UIWebViewUIWebView是iOS内置的浏览器控件系统自带的Safari浏览器就是通过UIWebView实现的 UIWebView不但能加载远程的网页资源,还能加载绝大部分的常见文件h ...
- postgres if ,when及判断表是否存在的sql编写
判断表是否存在方法1: SELECT THEN END FROM ( select count(*) as cc from pg_class where relname = 'wo' --wo is ...
- [转]删除MSSQL所有的约束及表格
--删除所有约束.表.视图等SQL脚本 --############################################### --删除所有外键约束 --################# ...
- 第六章.MyBatis缓存结构
一级缓存 测试案例: MyBatisTest.java //缓存 @Test public void testFindCustomerCache1() throws Exception{ SqlSes ...