Scrapy框架的命令行详解【转】
Scrapy框架的命令行详解
请给作者点赞 --> 原文链接
这篇文章主要是对的scrapy命令行使用的一个介绍
创建爬虫项目
scrapy startproject 项目名
例子如下:
localhost:spider zhaofan$ scrapy startproject test1
New Scrapy project 'test1', using template directory '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/scrapy/templates/project', created in:
/Users/zhaofan/Documents/python_project/spider/test1 You can start your first spider with:
cd test1
scrapy genspider example example.com
localhost:spider zhaofan$
这个时候爬虫的目录结构就已经创建完成了,目录结构如下:
|____scrapy.cfg
|____test1
| |______init__.py
| |____items.py
| |____middlewares.py
| |____pipelines.py
| |____settings.py
| |____spiders
| | |______init__.py
接着我们按照提示可以生成一个spider,这里以百度作为例子,生成spider的命令格式为;
scrapy genspider 爬虫名字 爬虫的网址
localhost:test1 zhaofan$ scrapy genspider baiduSpider baidu.com
Created spider 'baiduSpider' using template 'basic' in module:
test1.spiders.baiduSpider
localhost:test1 zhaofan$
关于命令详细使用
命令的使用范围
这里的命令分为全局的命令和项目的命令,全局的命令表示可以在任何地方使用,而项目的命令只能在项目目录下使用
全局的命令有:
startproject
genspider
settings
runspider
shell
fetch
view
version
项目命令有:
crawl
check
list
edit
parse
bench
startproject
这个命令没什么过多的用法,就是在创建爬虫项目的时候用
# 创建项目
scrapy startprojects myproject
genspider
用于生成爬虫,这里scrapy提供给我们不同的几种模板生成spider,默认用的是basic,我们可以通过命令查看所有的模板
# 列出所有的模版
scrapy genspider -l
localhost:test1 zhaofan$ scrapy genspider -l
Available templates:
basic
crawl
csvfeed
xmlfeed
localhost:test1 zhaofan$
当我们创建的时候可以指定模板,不指定默认用的basic,如果想要指定模板则通过
scrapy genspider -t 模板名字
# 生成一个项目模版
scrapy genspider -t crawl zhihu wwww.zhihu.com
localhost:test1 zhaofan$ scrapy genspider -t crawl zhihuspider zhihu.com
Created spider 'zhihuspider' using template 'crawl' in module:
test1.spiders.zhihuspider
localhost:test1 zhaofan$
crawl
这个是用去启动spider爬虫格式为:
scrapy crawl 爬虫名字
# 运行spider
scrapy crawl spidername
这里需要注意这里的爬虫名字和通过scrapy genspider 生成爬虫的名字是一致的
check
用于检查代码是否有错误,scrapy check
# check 用来检查代码是否有错误
scrapy check
list
scrapy list列出所有可用的爬虫
# list 返回项目里面所有spider的名称
scrapy list
edit
edit 在命令行下编辑spider ### 不建议运行
scrapy edit myspider
fetch
scrapy fetch url地址
该命令会通过scrapy downloader 讲网页的源代码下载下来并显示出来
这里有一些参数:
--nolog 不打印日志
--headers 打印响应头信息
--no-redirect 不做跳转
# fetch 输出日志及网页源代码
scrapy fetch http://www.baidu.com # fetch --nolog 只输出源代码
scrapy fetch --nolog http://www.baidu.com # fetch --nolog --headers 输出响应头
scrapy fetch --nolog --headers http://www.baidu.com # --nolog --no--redirect 禁止重定向
scrapy fetch --nolog --no--redirect http://www.baidu.com
view
scrapy view url地址
该命令会讲网页document内容下载下来,并且在浏览器显示出来
# view 从浏览器中打开网页
scrapy view http://www.taobao.com
因为现在很多网站的数据都是通过ajax请求来加载的,这个时候直接通过requests请求是无法获取我们想要的数据,所以这个view命令可以帮助我们很好的判断
shell
这是一个命令行交互模式
通过scrapy shell url地址进入交互模式
# shell 命令行交互模式
csrapy shell http://www.baidu.com
这里我么可以通过css选择器以及xpath选择器获取我们想要的内容(xpath以及css选择的用法会在下个文章中详细说明),例如我们通过scrapy shell http://www.baidu.com
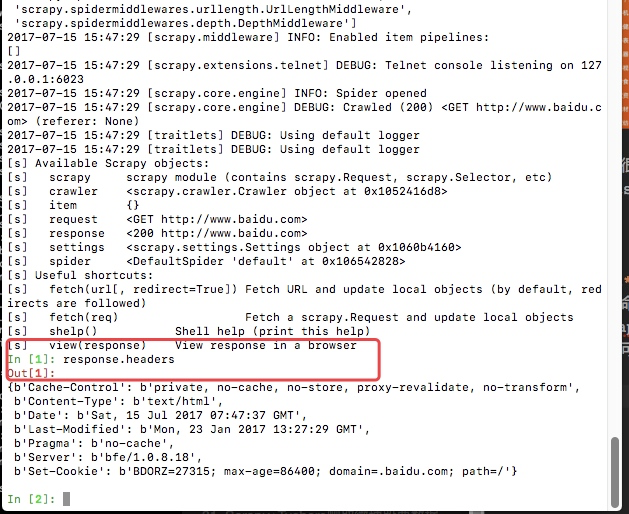
这里最后给我们返回一个response,这里的response就和我们通requests请求网页获取的数据是相同的。
view(response)会直接在浏览器显示结果
response.text 获取网页的文本
下图是css选择器的一个简单用法

settings
获取当前的配置信息
通过scrapy settings -h可以获取这个命令的所有帮助信息
# 获取帮助信息
scrapy settings -h
localhost:jobboleSpider zhaofan$ scrapy settings -h
Usage
=====
scrapy settings [options] Get settings values Options
=======
--help, -h show this help message and exit
--get=SETTING print raw setting value
--getbool=SETTING print setting value, interpreted as a boolean
--getint=SETTING print setting value, interpreted as an integer
--getfloat=SETTING print setting value, interpreted as a float
--getlist=SETTING print setting value, interpreted as a list Global Options
--------------
--logfile=FILE log file. if omitted stderr will be used
--loglevel=LEVEL, -L LEVEL
log level (default: DEBUG)
--nolog disable logging completely
--profile=FILE write python cProfile stats to FILE
--pidfile=FILE write process ID to FILE
--set=NAME=VALUE, -s NAME=VALUE
set/override setting (may be repeated)
--pdb enable pdb on failure
拿一个例子进行简单的演示:(这里是我的这个项目的settings配置文件中配置了数据库的相关信息,可以通过这种方式获取,如果没有获取的则为None)
localhost:jobboleSpider zhaofan$ scrapy settings --get=MYSQL_HOST
192.168.1.18
localhost:jobboleSpider zhaofan$
runspider
这个和通过crawl启动爬虫不同,这里是scrapy runspider 爬虫文件名称
所有的爬虫文件都是在项目目录下的spiders文件夹中
version
查看版本信息,并查看依赖库的信息
localhost:~ zhaofan$ scrapy version
Scrapy 1.3.2
localhost:~ zhaofan$ scrapy version -v
Scrapy : 1.3.2
lxml : 3.7.3.0
libxml2 : 2.9.4
cssselect : 1.0.1
parsel : 1.1.0
w3lib : 1.17.0
Twisted : 17.1.0
Python : 3.5.2 (v3.5.2:4def2a2901a5, Jun 26 2016, 10:47:25) - [GCC 4.2.1 (Apple Inc. build 5666) (dot 3)]
pyOpenSSL : 16.2.0 (OpenSSL 1.0.2k 26 Jan 2017)
Platform : Darwin-16.6.0-x86_64-i386-64bit
Scrapy框架的命令行详解【转】的更多相关文章
- Python爬虫从入门到放弃(十三)之 Scrapy框架的命令行详解
这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: localhost:spider zhaofan$ scrapy start ...
- Python之爬虫(十五) Scrapy框架的命令行详解
这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: localhost:spider zhaofan$ scrapy start ...
- 3-----Scrapy框架的命令行详解
创建爬虫项目 scrapy startproject 项目名 例子如下: E:\crawler>scrapy startproject test1 New Scrapy project 'tes ...
- [转载]OpenSSL中文手册之命令行详解(未完待续)
声明:OpenSSL之命令行详解是根据卢队长发布在https://blog.csdn.net/as3luyuan123/article/details/16105475的系列文章整理修改而成,我自己 ...
- scrapy框架的命令行解释
scrapy框架的命令解释 创建爬虫项目 scrapy startproject 项目名例子如下: scrapy startproject test1 这个时候爬虫的目录结构就已经创建完成了,目录结构 ...
- 7Z命令行详解
7z.exe在CMD窗口的使用说明如下: 7-Zip (A) 4.57 Copyright (c) 1999-2007 Igor Pavlov 2007-12-06 Usage: 7za <co ...
- 7-zip命令行详解
一.简介 7z,全称7-Zip, 是一款开源软件.是目前公认的压缩比例最大的压缩解压软件. 主要特征: # 全新的LZMA算法加大了7z格式的压缩比 # 支持格式: * 压缩 / 解压缩:7z, XZ ...
- 爬虫(十):scrapy命令行详解
建爬虫项目 scrapy startproject 项目名例子如下: localhost:spider zhaofan$ scrapy startproject test1 New Scrapy pr ...
- gcc命令行详解
介绍] ----------------------------------------- 常见用法: GCC 选项 GCC 有超过100个的编译选项可用. 这些选项中的许多你可能永远都不会用到, 但 ...
随机推荐
- PIO导出
1..HSSFWorkbook 声明一个工作簿,创建一个excel文件 //创建HSSFWork对象(excel的文档对象) HSSFWorkbook wb=new HSSFWorkbook(); / ...
- LESS CSS非常实用实例应用
@charset "UTF-8"; @base-color:#333; // 圆角 .border-radius (@radius: 5px) { -webkit-border-r ...
- JavaScript 创建对象的七种方式
转自:xxxgitone.github.io/2017/06/10/JavaScript创建对象的七种方式/ JavaScript创建对象的方式有很多,通过Object构造函数或对象字面量的方式也可以 ...
- testNG测试基础一
1.TestNG概念 TestNG:Testing Next Generation 下一代测试技术,是一套根据JUnit和Nunit思想构建的利用注释来强化测试功能的测试框架,可用来做单元测试,也可用 ...
- Visual Studio 2010 vs2010 英文版 使用 已有的中文版 MSDN 帮助文档
第一步 设置Help Library Manager区域语言 打开Microsoft Visual Studio 2010开始菜单里Visual Studio Tools里的Manage Help S ...
- cms-详细页面2
详细页面遗留下来的部分: 1:当前位置 2.分享 3.时间格式 4.摘要 5.关键字: 解决方案: 1:当前位置:---后台拼接 2:分享:前端一段js代码 3.摘要,直接数据库查询 4.时间格式:引 ...
- hadoop balance均衡datanode存储不起作用问题分析
前段时间因为hadoop集群各datanode空间使用率很不均衡,需要重新balance(主要是有后加入集群的2台机器磁盘空间比较大引起的),在执行如下语句: bin/start-balancer.s ...
- 关于前端的交互 ajax
对于交互来说,可以利用原生的javascript和jquery 这篇说的就是jquery 1 不是跨域的 利用$ajax({})这个函数实现的 $.ajax({ url: "", ...
- VMware NAT端口映射外网访问虚拟机linux可能会出现的错误总结
博主因为做实验报告的缘故,尝试以NAT的方式从外网远程连接到虚拟机的linux操作系统:https://www.cnblogs.com/jluzhsai/p/3656760.html,本文主要举出在此 ...
- Windows 服务快捷启动命令,可以直接在运行处运行电脑的功能。
gpedit.msc-----组策略 sndrec32-----录音机 nslookup----- ip地址侦测器 explorer------ 打开资源管理器 logoff-------注销命令 t ...