Spark MLlib KMeans 聚类算法
一.简介
KMeans 算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把分类样本点分到各个簇。然后按平均法重新计算各个簇的质心,从而确定新的簇心。一直迭代,直到簇心的移动距离小于某个给定的值。
二.步骤
1.为待聚类的点寻找聚类中心。
2.计算每个点到聚类中心的距离,将每个点聚类到该点最近的聚类中。
3.计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心。
4.反复执行步骤2,3,直到聚类中心不再进行大范围移动或者聚类迭代次数达到要求为止。
三.演示

四.初始中心点选择
1.随机选择k个点作为中心点。
对应算法:KMeans
2.采用k-means++选择中心点。
基本思想:初始的聚类中心点之间的相互距离要尽可能远。
步骤:
1.从输入的数据点集合中随机选择一个点作为第一个聚类中心点。
2.对于数据点中的每一个点【已选择为中心点的除外】x,计算它与最近聚类中心点的距离D(x)。
3.选择一个新的数据点为聚类的中心点,原则是D(x)较大的点,被选择的概率较大。
4.重复步骤2,3,直到所有的聚类中心点被选择出来。
5.使用这k个初始中心点运行标准的KMeans算法。
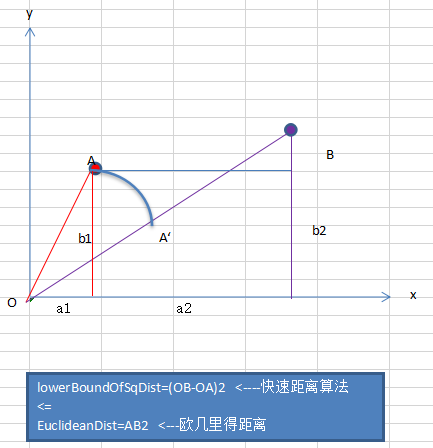
五.D(x)映射被选择的概率
1.从输入的数据点集合D中随机选择一个点作为第一个聚类中心点。
2.对于数据点中的每一个点【已选择为中心点的除外】x,计算它与最近聚类中心点的距离Si,对所有Si求和得到sum。
3.取一个随机数,用权重的方式计算下一个中心点。取随机值random(0<random<sum),对点集D循环,做random-=Si运算,直到random<0,那么点i就是下一个中心点。
六.源码分析
1.MLlib的KMeans聚类模型的runs参数可以设置并行计算聚类中心的数量,runs代表同时计算多组聚类中心点,最后去计算结果最好的那一组中心点作为聚类的中心点。
2.KMeans快速查找,计算距离

七.代码测试
1.测试数据
0.0 0.0 0.0
0.1 0.1 0.1
0.2 0.2 0.2
9.0 9.0 9.0
9.1 9.1 9.1
9.2 9.2 9.2
4.5 5.6 4.3
2.代码实现
package big.data.analyse.mllib
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.clustering.{KMeans, KMeansModel}
import org.apache.spark.mllib.linalg.Vectors
/**
* Created by zhen on 2019/4/11.
*/
object KMeansTest {
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("KMeansExample")
conf.setMaster("local[2]")
val sc = new SparkContext(conf)
// Load and parse the data
val data = sc.textFile("data/mllib/kmeans_data.txt")
val parsedData = data.map(s => Vectors.dense(s.split(' ').map(_.toDouble))).cache()
// split data to train data and test data
val weights = Array(0.8, 0.2)
val splitParseData = parsedData.randomSplit(weights)
// Cluster the data into two classes using KMeans
val numClusters = 2
val numIterations = 20
val clusters = KMeans.train(parsedData, numClusters, numIterations)
// Evaluate clustering by computing Within Set Sum of Squared Errors
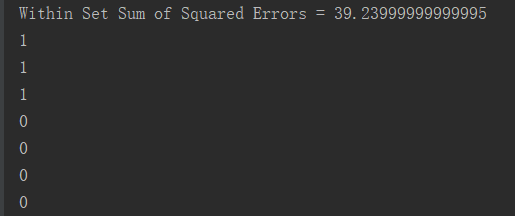
val WSSSE = clusters.computeCost(parsedData)
println("Within Set Sum of Squared Errors = " + WSSSE)
// predict data
val result = clusters.predict(parsedData)
result.foreach(println(_))
// Save and load model
clusters.save(sc, "target/KMeansModel")
val sameModel = KMeansModel.load(sc, "target/KMeansModel")
sc.stop()
}
}
3.结果
八.总结
聚类作为无监督的机器学习算法,只能根据具体的算法实现对不同数据进行分类,不能具体指出类内不同数据的相似性,以及与其它类内节点的差异性。
Spark MLlib KMeans 聚类算法的更多相关文章
- Spark MLBase分布式机器学习系统入门:以MLlib实现Kmeans聚类算法
1.什么是MLBaseMLBase是Spark生态圈的一部分,专注于机器学习,包含三个组件:MLlib.MLI.ML Optimizer. ML Optimizer: This layer aims ...
- K-Means 聚类算法
K-Means 概念定义: K-Means 是一种基于距离的排他的聚类划分方法. 上面的 K-Means 描述中包含了几个概念: 聚类(Clustering):K-Means 是一种聚类分析(Clus ...
- k-means聚类算法python实现
K-means聚类算法 算法优缺点: 优点:容易实现缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他 ...
- K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
- Kmeans聚类算法原理与实现
Kmeans聚类算法 1 Kmeans聚类算法的基本原理 K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一.K-means算法的基本思想是:以空间中k个点为中心进行聚类,对 ...
- 机器学习六--K-means聚类算法
机器学习六--K-means聚类算法 想想常见的分类算法有决策树.Logistic回归.SVM.贝叶斯等.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别 ...
- 转载: scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- 沙湖王 | 用Scipy实现K-means聚类算法
沙湖王 | 用Scipy实现K-means聚类算法 用Scipy实现K-means聚类算法
- Matlab中K-means聚类算法的使用(K-均值聚类)
K-means聚类算法采用的是将N*P的矩阵X划分为K个类,使得类内对象之间的距离最大,而类之间的距离最小. 使用方法:Idx=Kmeans(X,K)[Idx,C]=Kmeans(X,K) [Idx, ...
随机推荐
- VS2017中使用组合项目_windows服务+winform管理_项目发布_测试服务器部署
前言:作为一名C#开发人员,避免不了常和windows服务以及winform项目打交道,本人公司对服务的管理也是用到了这2个项目的组合方式进行:因为服务项目是无法直接安装到计算器中,需要使用命令借助微 ...
- Java 在PDF文档中绘制图形
本篇文档将介绍通过Java编程在PDF文档中绘制图形的方法.包括绘制矩形.椭圆形.不规则多边形.线条.弧线.曲线.扇形等等.针对方法中提供的思路,也可以自行变换图形设计思路,如菱形.梯形或者组合图形等 ...
- String字符串类总结
object类 int hashCode() Object定义的hashCode方法能为不同对象返回不同的整数.实际上是把JVM给对象分配的地址转化为整数,确保了逻辑上的唯一性.而转化的散列算法,可能 ...
- JS 实现的年月日三级联动
js文件 SYT="-请选择年份-"; SMT="-请选择月份-"; SDT="-请选择日期-"; BYN=50;//年份范围往前50年 A ...
- 设计模式之桥接模式——Java语言描述
桥接适用于把抽象化和实现化解耦,使得二者可以独立变化.这种类型的设计模式属于结构性模式,它通过提供抽象化和实现化之间的桥接结构,来实现二者的解耦 这种模式设计到一个作为桥接的接口,使得实体类的功能独立 ...
- GDAL读取的坐标起点在像素左上角还是像素中心?
目录 1. 问题 2. 结论 3. 例外 1. 问题 笔者在处理地理栅格数据的时候,总是会发生偏差半个像素的问题. 比如说通过ArcMap打开一张.tif,查看其地理信息:同时用记事本打开.tfw,比 ...
- 编程心法 之 敏捷开发(新架构)Agile Team Organization Squads, Chapters, Tribes and Guilds
Agile Team 参考 一般情况下,一个小组有以下功能分布: Squads 每个主要的功能的开发属于一个Squad,比如说QQ这个应用,可以分为QQ空间小组.QQ会员小组等等, 每一个Squad有 ...
- MongoDB十二种最有效的模式设计【转】
持续关注MongoDB博客(https://www.mongodb.com/blog)的同学一定会留意到,技术大牛Daniel Coupal 和 Ken W. Alger ,从 今年 2月17 号开始 ...
- docker的简单使用
1.下载centos镜像 docker pull centos 2.查看本地所有镜像 docker images 3.后台运行docker docker run -t -i -d centos /bi ...
- Vue(day8)
继续上一篇文章的内容,本文主要内容为项目中新闻资讯模块的实现. 新闻资讯页面主要是当我们点击这个按钮时跳转到新闻列表界面. 一.新闻资讯的路由设计 将新闻资讯的标签改为路由:(a标签改为router- ...