登录网站爬虫(保持Cookie不变)
平时经常需要到学校的信息门户去查看课表及其他信息,于是想做一个爬虫 ,可以自动替我登录并且得到这些信息,于是今天动手写了一个爬虫:
首先登录学校的信息门户:http://cas.whu.edu.cn/authserver/login?service=http://my.whu.edu.cn
然后这里我随便输入账号名和密码,来看看登录时浏览器都做了些什么。这里我使用的是FireFix浏览器以及HttpFox插件,如果用Chrome的话,谷歌下也有很棒的插件,IE的话推荐HTTPWatch。
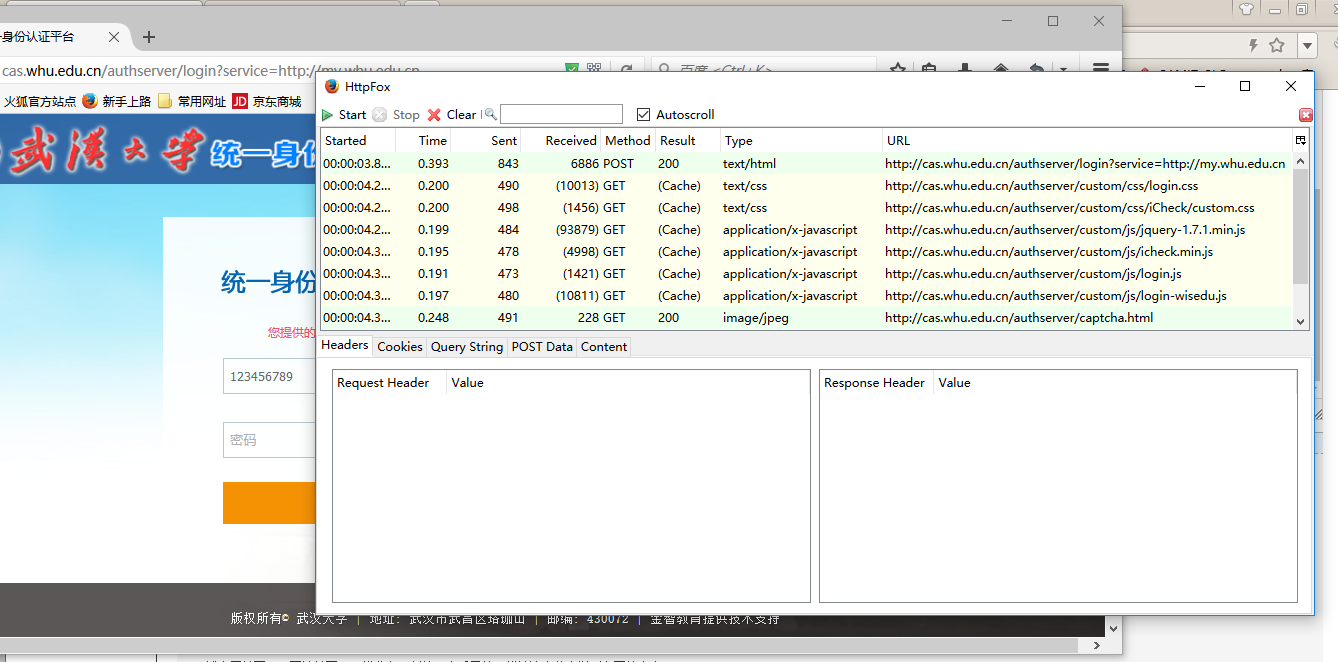
从HttpFox中我们可以分析得出大概流程,首先就是浏览器根据Name获取到html中表单中的input内容,然后通过post提交到一个服务器地址,然后服务器判断用户名密码是否正确,进而做出相应的响应。接下来我们就需要知道浏览器是把什么数据提交到了哪里,我们点击httpfox中的第一个步骤:
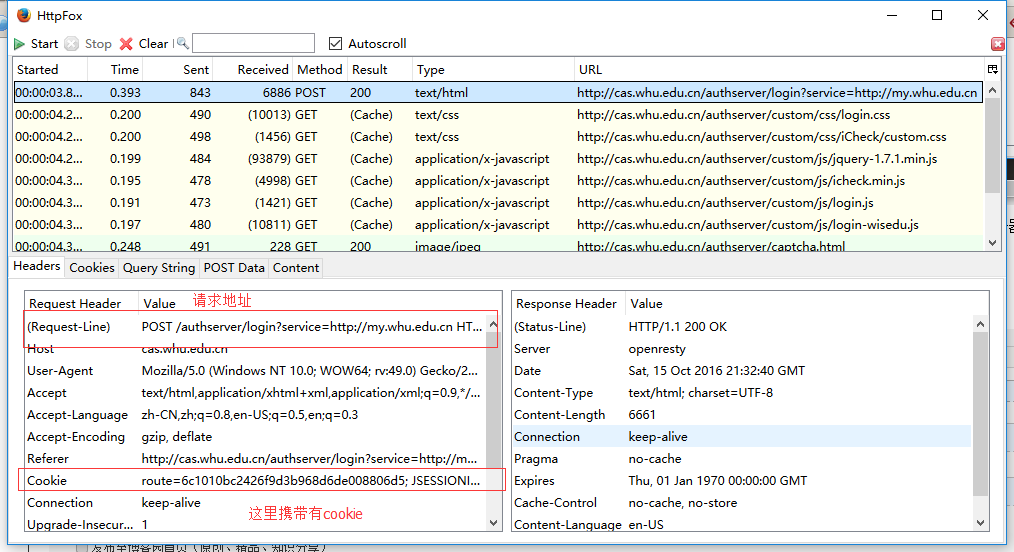
可以看到浏览器把数据还是提交到了当前页面,并且携带有Cookie,我们再看看postdata里都有什么
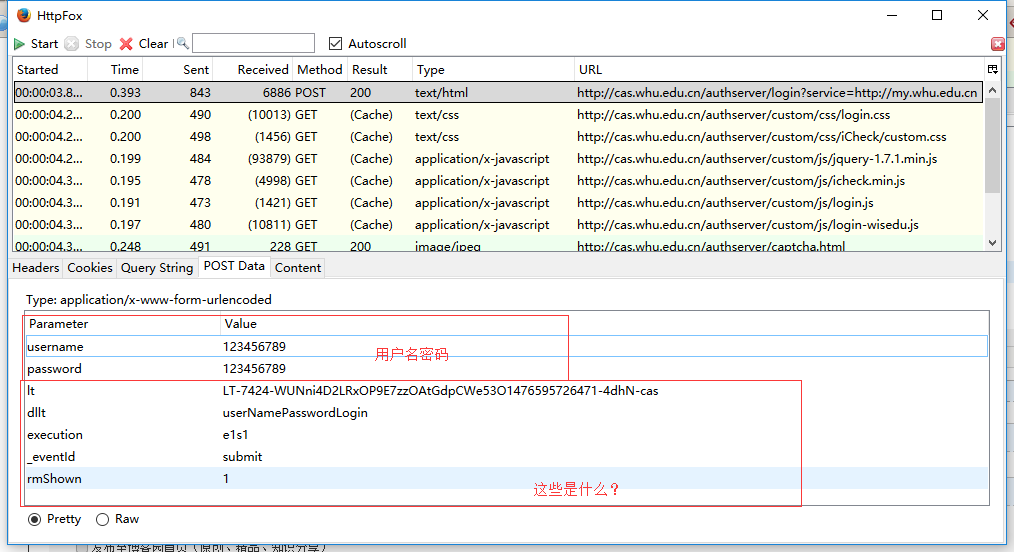
可以看到postdata中不仅有用户名密码,还有一些其他数据,到这里我们可以用Python写一个爬虫,只提交用户名密码,然后你会发现服务器还是给你返回一个登录页面,这时候我们就需要考虑lt dllt这些postdata了,可是这些是什么呢?我查阅了一些资料,lt可以理解成每个需要登录的用户都有一个流水号。只有有了webflow发放的有效的流水号,用户才可以说明是已经进入了webflow流程。否则,没有流水号的情况下,webflow会认为用户还没有进入webflow流程,从而会重新进入一次webflow流程,从而会重新出现登录界面。
那么如何获得这个lt数据呢。我们回到http://cas.whu.edu.cn/authserver/login?service=http://my.whu.edu.cn,按F12,
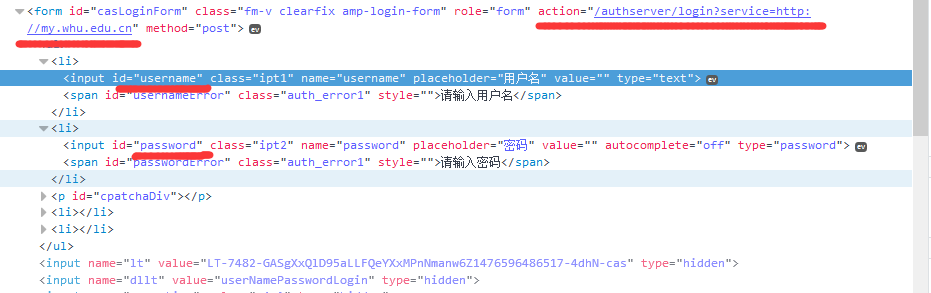
我们很容易能找到用户名和密码的两个input,我们在查找input标签:
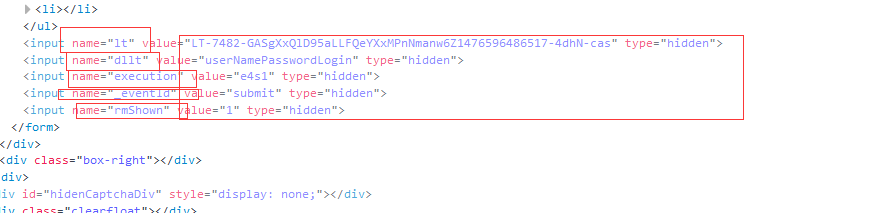
发现在form最下面有这几个隐藏域,现在我们已经拿到了流水号,可是还有一个问题:就是我首先发送一个get,然后我拿到这个隐藏域所有value,然后我需要在发送一次post方式,这时候,我们先前获得的lt值已经不再是现在的lt值了,所以这个时候我们就要用requests的session方法来保持cookie不变了,session方法可以让同一个实例发出的所有请求保持相同的cookie。
接下来任务就好做了:
#encode=utf8
'''
Created on 2016年10月15日 @author: WangHui
@note: View things from WuHanUniversity
'''
import requests
from http.cookiejar import CookieJar
from bs4 import BeautifulSoup class WHUHelper(object):
__loginuri='http://cas.whu.edu.cn/authserver/login?service=http://my.whu.edu.cn'
__logindo='http://yjs.whu.edu.cn'
#初始化构造函数,账户和密码
def __init__(self,name='',password=''):
#账户名
if not isinstance(name,str):
raise TypeError('请输入字符串')
else:
self.name=name
if isinstance(password,int):
self.password=str(password)
elif isinstance(password, str):
self.password=password
else:
raise TypeError('请输入字符串')
#返回一个登陆成功后的Response
def __getResponseAfterLogin(self):
#模拟一个浏览器头
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0'}
#保持Cookie不变,然后再次访问这个页面
s=requests.Session()
#CookieJar可以帮我们自动处理Cookie
s.cookies=CookieJar()
#得到一个Response对象,但是此时还没有登录
r=s.get(self.__loginuri,headers=header)
#得到postdata应该有的lt
#这里使用BeautifulSoup对象来解析XML
dic={}
lt=BeautifulSoup(r.text,'html.parser')
for line in lt.form.findAll('input'):
if(line.attrs['name']!=None):
dic[line.attrs['name']]=line.attrs['value']
params={
'username':self.name,
'password':self.password,
'dllt':'userNamePasswordLogin',
'lt':dic['lt'],
'execution':dic['execution'],
'_eventId':dic['_eventId'],
'rmShown':dic['rmShown']}
#使用构建好的PostData重新登录,以更新Cookie
r=s.post(self.__loginuri, data=params,headers=header)
#返回登录后的response
return s
#得到研究生信息门户指定分类下的HTML
def __getHtmlOfPerson(self):
s=self.__getResponseAfterLogin()
personUri='http://yjs.whu.edu.cn/ssfw/index.do#'
r=s.get(personUri)
return r.text
#得到研究生个人信息
def getPersonInfor(self):
s=self.__getResponseAfterLogin()
bs=BeautifulSoup(self.__getHtmlOfPerson(),'html.parser')
dic={}
#得到基本信息get方式的访问URL网站
jbxxUri=self.__logindo+bs.find('a',{'text':'基本信息'}).attrs['url']
r=s.get(jbxxUri)
bs=BeautifulSoup(r.text,'html.parser')
dic['学号']=bs.find('input',{'name':'jbxx.xh'}).attrs['value']
dic['姓名']=bs.find('input',{'name':'jbxx.xm'}).attrs['value']
return dic
#得到个人课表
def getClassInfo(self):
#初始化课表
classInfo=[]
classTitle=['星期一','星期二','星期三','星期四','星期五','星期六','星期日']
for i in range(13):
singleclass=[]
for j in range(7):
singleclass.append('')
classInfo.append(singleclass)
#首先得到登陆后的request
s=self.__getResponseAfterLogin()
bs=BeautifulSoup(self.__getHtmlOfPerson(),'html.parser')
jbxxkb=self.__logindo+bs.find('a',{'text':'我的课表'}).attrs['url']
r=s.get(jbxxkb)
bs=BeautifulSoup(r.text,'html.parser')
#得到每天十三节课
trs=bs.find('table',{'class':'table_con'}).findAll('tr',{'class':'t_con'})
for i in range(len(trs)):
tds=trs[i].findAll('td')
#表示星期几
j=0
for td in tds:
#首先去掉table的行标题和列标题
#根据规律可知,凡是带有标题的都含有b标签
if td.find('b')!=None:
continue
#beautifulsoup会把 解析为\a0,所以这里需要先转码,然后在编码
classInfo[i][j]=str(td.get_text()).encode('gbk','ignore').decode('gbk')
j=j+1
classInfo.insert(0, classTitle)
return classInfo
当然这个类并不完善,我只是想要看到我的课表,如果需要查看其他信息,可以使那个requests再次发送请求,然后用BeautifulSoup4解析即可。
这里我们可以测试一下:
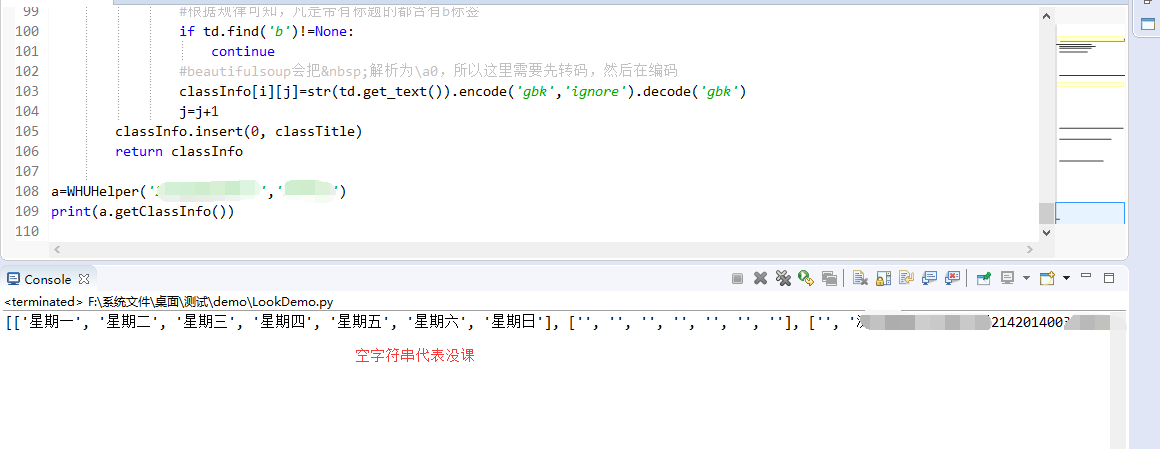
参考文章:
https://my.oschina.net/u/1177799/blog/491645
http://beautifulsoup.readthedocs.io/zh_CN/latest/
http://m.blog.csdn.net/article/details?id=51628649
http://docs.python-requests.org/en/latest/user/advanced/#session-objects
登录网站爬虫(保持Cookie不变)的更多相关文章
- Python 自动登录网站(处理Cookie)
http://digiter.iteye.com/blog/1300884 Python代码 def login(): cj = cookielib.CookieJar() ope ...
- python网络爬虫之使用scrapy自动登录网站
前面曾经介绍过requests实现自动登录的方法.这里介绍下使用scrapy如何实现自动登录.还是以csdn网站为例. Scrapy使用FormRequest来登录并递交数据给服务器.只是带有额外的f ...
- 爬虫模拟cookie自动登录(人人网自动登录)
什么是cookie? 在网站中,HTTP请求时无状态的,也就是说即使第一次和服务器连接后并且登录成功后,第二次请求服务器依然不能知道当前请求是谁,cookie的出现就是为了解决这个问题,第一次登陆后服 ...
- 4 使用Selenium模拟登录csdn,取出cookie信息,再用requests.session访问个人中心(保持登录状态)
代码: # -*- coding: utf-8 -*- """ Created on Fri Jul 13 16:13:52 2018 @author: a " ...
- 用libcurl 登录网站
libcurl 可以发送和接收HTTP消息,因此可以发送用户名.密码和验证码来登录网站,网上有不少这方面的内容,但不甚完整,我摸索了两天,将其中要点记录下来. 基本步骤 正常访问登录页面,访问时,设置 ...
- IE10、IE11 ASP.Net 网站无法写入Cookie 问题
在做项目的时候遇上一个奇怪的问题,这个项目是用前端DWZ框架+MVC框架做的,在IE10和IE11上, 用户登录之后,操作界面中的任何操作,都无法操作,抛出异常,经过查找分析发现, 只有在IE10和I ...
- c#使用WebClient登录网站抓取登录后的网页
C#登录网站实际上就是模拟浏览器提交表单,然后记录浏览器响应返回的会话Cookie值,再次发送请求时带着这个会话cookie值去请求就可以实现模拟登录的效果了. 如下类CookieAwareWebCl ...
- Winform模拟post请求和get请求登录网站
引言 最近有朋友问如何用winform模拟post请求,然后登录网站,稍微想了一下,大致就是对http报文的相关信息的封装,然后请求网站登录地址的样子.发现自己的博客中对这部分只是也没总结,就借着这股 ...
- Bing必应(Yahoo雅虎)搜索引擎登录网站 - Blog透视镜
Bing必应是微软的搜索引擎,原本是置放在MSN网站上的,微软重新开发并改为新的名子,只要连到官网,登录网站后,过了不久,搜索引擎就会用爬虫,来检索你的网站,等过了一阵子之后,自然就可以找到你的文章. ...
随机推荐
- django访问sqlserver中的坑
首先不用说先安装django-sqlserver pip install django-sqlserver 然后在settings.py中修改'ENGINE': 'sqlserver_ado', ...
- 操作Json
C#可以像Javascript一样操作Json 阅读目录 Json的简介 Json的优点 传统操作Json 简易操作Json Json的简介 JSON(JavaScript Object Notati ...
- javabean 简介
javabean其实包含多个方面的含义. Java语言开发的可重用组件 优点:1,代码简洁.2,HTML与Java分离,好维护.3,将常用程序写成可重用组件,避免重复. 特点:1,所有类放在同 ...
- BZOJ 1012 最大数
Description 现在请求你维护一个数列,要求提供以下两种操作: 1. 查询操作.语法:Q L 功能:查询当前数列中末尾L个数中的最大的数,并输出这个数的值.限制:L不超过当前数列的长度. 2. ...
- 【Java】WSDL 简介
WSDL(网络服务描述语言,Web Services Description Language)是一门基于 XML 的语言,用于描述 Web Services 以及如何对它们进行访问. 什么是 WSD ...
- Unity 随机数的使用
脚本语言:C# 一个比较常用的例子是游戏中的主角碰到场景中的NPC时,NPC会随机做出反应,例如有50%几率来友好的致敬,25%几率走开,20%几率反身攻击和%%的几率赠送礼物. 创建一个NPCTes ...
- github继续折腾
又在折腾github了,本来以前在neworiginou这个github上上传过项目的: 现在想在另一个github上joely上传项目,发现按以前的流程做个测试,居然没能上传成功! 经发现,以前的n ...
- DateDiff 函数,用生日获得年龄
一:截图 二:代码 using System; using System.Collections.Generic; using System.ComponentModel; using System. ...
- IGeometry 中取指定的点
private static IGeometryCollection MakeMultiPoint(IGeometry geometry,int pointcount) { IGeo ...
- String拼接也有用加号更好的时候
做String拼接时用StringBuilder(或StringBuffer)好还是直接用+号性能好?一般来说是前者,不过也有用加号略好的时候.首先我一直认为用+号有很好的可读性,而且当String拼 ...