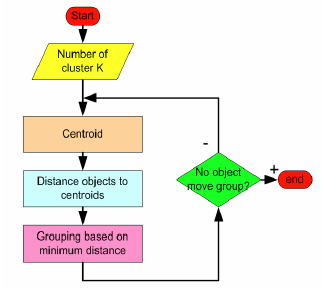
聚类:(K-means)算法
1.归类:
- 聚类(clustering) 属于非监督学习 (unsupervised learning)
- 无类别标记(class label)
2.举例:
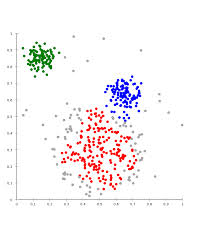
输入:k, data[n];
4.2 一个药物分类的例子:

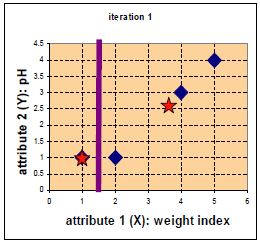
四中药物给予了 weight index 和 pH 两个特征。
在二维坐标系中的分布如下:
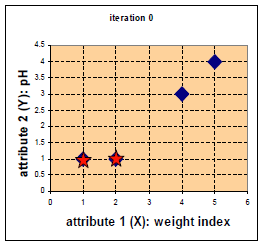
D0为第一次迭代,第一行为4个点到c1的距离,第二行为4个点到c2的距离。
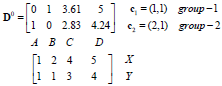
G0为第一次迭代后的归类情况,将各点到c1、c2的距离进行比较,哪个的距离小就为哪一类。
归类如下:c1为第一类,c2、c3、c4为第二类。
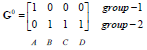
第二类的中心点更新如下:

重新计算中心点如下(星为中心点):(若该类中的点变化,则更新该类的中心点;否则不更新)
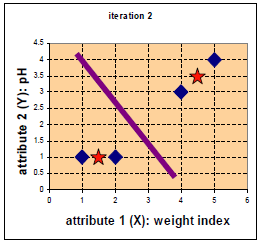
第二次迭代。
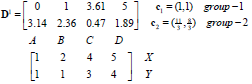
G1为第二次迭代后的归类情况。
归类如下:c1、c2为第一类,c3、c4为第二类。
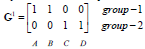
更新第一类、第二类的中心点如下:
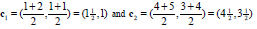

归类没有发生变化(达到终止条件)
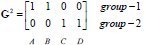
停止。

聚类:(K-means)算法的更多相关文章
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 聚类--K均值算法
import numpy as np from sklearn.datasets import load_iris iris = load_iris() x = iris.data[:,1] y = ...
- 第八次作业:聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
import numpy as np x = np.random.randint(1,100,[20,1]) y = np.zeros(20) k = 3 def initcenter(x,k): r ...
- K-means算法
K-means算法很简单,它属于无监督学习算法中的聚类算法中的一种方法吧,利用欧式距离进行聚合啦. 解决的问题如图所示哈:有一堆没有标签的训练样本,并且它们可以潜在地分为K类,我们怎么把它们划分呢? ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 聚类和EM算法——K均值聚类
python大战机器学习——聚类和EM算法 注:本文中涉及到的公式一律省略(公式不好敲出来),若想了解公式的具体实现,请参考原著. 1.基本概念 (1)聚类的思想: 将数据集划分为若干个不想交的子 ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
随机推荐
- 时间序列HW
https://www.cnblogs.com/sylvanas2012/p/4328861.html写得特别好,推荐阅读 Holt-Winters: 三阶指数平滑 Holt-Winters的思想是 ...
- Java入门:练习——自定义通用工具类
请编写一个通用工具类,该类具有如下功能: 1)判断一个字符串是否是邮箱地址 2)判断一个字符串是否是手机号码 3)判断一个字符串是否是电话号码 4)判断一个字符串是否是IP地址 代码结构如下,请补充完 ...
- Swarm使用原生的overlay网络
一.Swarm Overlay Network Swarm有Service的概念.一个Service是指使用相同镜像.同时运行的多个容器,多个容器同时一起对外提供服务,多个容器之间负载均衡.每个Ser ...
- 发现视口(窗口)自适应的新大陆!!vw、vh
从事前端已经1年了,一直为背景自适应铺满整个屏幕而苦苦发愁,因为要适配不同的pc显示器,所以高度不能写死,但是写(height:100%)并不能实现,愁死我了~我要不用写好的css框架实现或者自己写j ...
- MySQL数据库远程连接很慢的解决方案
在开发机器上链接mysql数据库很慢,但是在数据库服务器上直接链接数据库很快.猜测应该是远程链接解析的问题,在查询MySQL相关文档和网络搜索后,发现了一个配置似乎可以解决这样的问题,就是在MySQL ...
- 6个动作4种难度选择!家庭减肥就用hiit
今天推荐一组课程计划,6个动作,后面会教你如何调整课程难度,以便让课程更适合自己的身体情况. 一.深蹲:8-10次 二.俯卧撑:5-8次(女生如果完成不了标准俯卧撑,可以选择跪姿俯卧撑) 三.平板支撑 ...
- PHP 神盾解密工具
前两天分析了神盾的解密过程所用到的知识点,昨晚我把工具整理了下,顺便用神盾加密了.这都是昨天说好的,下面看下调用方法吧. 先下载 decryption.zip然后解压放到一个文件夹里,把你要解密的文件 ...
- asp.net中GridView传多个值到其它页面的方法
网站开发中,在页面之间的跳转,经常会用到传值,其中可能会传递多个值. 一.CommadArgument传多个值到其他页面. 像Gridview dataList repeater等数据绑定控件中,可以 ...
- Getting Real 摘记
第二章 起始点 一个很好的做软件的方式就是一开始用它来解决你自己的问题.由于你自己变成了软件的目标受众因此你会知道什么是重要的什么不是.这样做下去将会是推出一个突破性产品的伟大起始点. 手头有多少钱就 ...
- HDU 1256 画8 模拟题
解题报告:这题我觉得题目有一个没有交代清楚的地方就是关于横线的字符的宽度的问题,题目并没有说,事实上题目要求的是在保证下面的圈高度不小于上面的圈的高度的情况下,横线的宽度就是等于下面的圈的高度. #i ...