L1正则化及其推导
\(L1\)正则化及其推导
在机器学习的Loss函数中,通常会添加一些正则化(正则化与一些贝叶斯先验本质上是一致的,比如\(L2\)正则化与高斯先验是一致的、\(L1\)正则化与拉普拉斯先验是一致的等等,在这里就不展开讨论)来降低模型的结构风险,这样可以使降低模型复杂度、防止参数过大等。大部分的课本和博客都是直接给出了\(L1\)正则化的解释解或者几何说明来得到\(L1\)正则化会使参数稀疏化,本来会给出详细的推导。
\(L1\)正则化
大部分的正则化方法是在经验风险或者经验损失\(L_{emp}\)(emprirical loss)上加上一个结构化风险,我们的结构化风险用参数范数惩罚\(\Omega(\theta)\),用来限制模型的学习能力、通过防止过拟合来提高泛化能力。所以总的损失函数(也叫目标函数)为:
\[
J(\theta; X, y) = L_{emp}(\theta; X, y) + \alpha\Omega(\theta) \tag{1.1}
\]
其中\(X\)是输入数据,\(y\)是标签,\(\theta\)是参数,\(\alpha \in [0,+\infty]\)是用来调整参数范数惩罚与经验损失的相对贡献的超参数,当\(\alpha = 0\)时表示没有正则化,\(\alpha\)越大对应该的正则化惩罚就越大。对于\(L1\)正则化,我们有:
\[
\Omega(\theta) = \|w\|_1 \tag{1.2}
\]
其中\(w\)是模型的参数。
几何解释
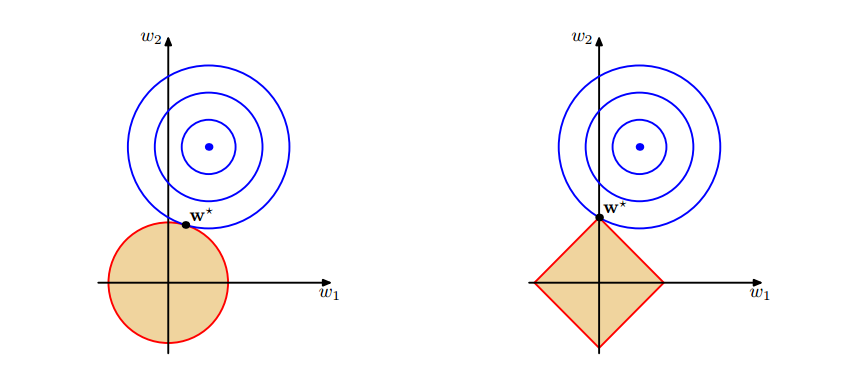
图1 上面中的蓝色轮廓线是没有正则化损失函数的等高线,中心的蓝色点为最优解,左图、右图分别为$L2$、$L1$正则化给出的限制。
可以看到在正则化的限制之下,\(L2\)正则化给出的最优解\(w^*\)是使解更加靠近原点,也就是说\(L2\)正则化能降低参数范数的总和。\(L1\)正则化给出的最优解\(w^*\)是使解更加靠近某些轴,而其它的轴则为0,所以\(L1\)正则化能使得到的参数稀疏化。
解析解的推导
有没有偏置的条件下,\(\theta\)就是\(w\),结合式\((1.1)\)与\((1.2)\),我们可以得到\(L1\)正则化的目标函数:
\[
J(w; X, y) = L_{emp}(w; X, y) + \alpha\|w\|_1 \tag{3.1}
\]
我们的目的是求得使目标函数取最小值的\(w^*\),上式对\(w\)求导可得:
\[
\nabla_w J(w; X, y) = \nabla_w L_{emp}(w; X, y) + \alpha \cdot sign(w) \tag{3.2}
\]
其中若\(w>0\),则\(sign(w)=1\);若\(w<0\),则\(sign(w) = -1\);若\(w=0\),则\(sign(w)=0\)。当\(\alpha = 0\),假设我们得到最优的目标解是\(w^*\),用秦勤公式在\(w^*\)处展开可以得到(要注意的\(\nabla J(w^*)=0\)):
\[
J(w; X, y) = J(w^*; X, y) + \frac{1}{2}(w - w^*)H(w-w^*) \tag{3.3}
\]
其中\(H\)是关于\(w\)的Hessian矩阵,为了得到更直观的解,我们简化\(H\),假设\(H\)这对角矩阵,则有:
\[
H = diag([H_{1,1},H_{2,2}...H_{n,n}]) \tag{3.4}
\]
将上式代入到式\((3.1)\)中可以得到,我们简化后的目标函数可以写成这样:
\[
J(w;X,y)=J(w^*;X,y)+\sum_i\left[\frac{1}{2}H_{i,i}(w_i-w_i^*)^2 + \alpha_i|w_i| \right] \tag{3.5}
\]
从上式可以看出,\(w\)各个方向的导数是不相关的,所以可以分别独立求导并使之为0,可得:
\[
H_{i,i}(w_i-w_i^*)+\alpha \cdot sign(w_i)=0 \tag{3.6}
\]
我们先直接给出上式的解,再来看推导过程:
\[
w_i = sign(w^*) \max\left\{ |w_i^*| - \frac{\alpha}{H_{i,i}},0 \right\} \tag{3.7}
\]
从式\((3.5)\)与式\((3.6)\)可以得到两点:
- 1.可以看到式\((3.5)\)中的二次函数是关于\(w^*\)对称的,所以若要使式\((3.5)\)最小,那么必有:\(|w_i|<|w^*|\),因为在二次函数值不变的程序下,这样可以使得\(\alpha|w_i|\)更小。
- 2.\(sign(w_i)=sign(w_i^*)\)或\(w_1=0\),因为在\(\alpha|w_i|\)不变的情况下,\(sign(w_i)=sign(w_i^*)\)或\(w_i=0\)可以使式\((3.5)\)更小。
由式\((3.6)\)与上述的第2点:\(sign(w_i)=sign(w_i^*)\)可以得到:
\[
\begin{split}
0 &= H_{i,i}(w_i-w_i^*)+\alpha \cdot sign(w_i^*) \cr
w_i &= w_i^* - \frac{\alpha}{H_{i,i}}sign(w_i^*) \cr
w_i &= sign(w_i^*)|w_i^*| - \frac{\alpha}{H_{i,i}}sign(w_i^*)\cr
&=sign(w_i^*)(|w_i^*| - \frac{\alpha}{H_{i,i}}) \cr
\end{split} \tag{3.8}
\]
我们再来看一下第2点:\(sign(w_i)=sign(w_i^*)\)或\(w_1=0\),若\(|w_i^*| < \frac{\alpha}{H_{i,i}}\),那么有\(sign(w_i) \neq sign(w_i^*)\),所以这时有\(w_1=0\),由于可以直接得到解式\((3.7)\)。
从这个解可以得到两个可能的结果:
- 1.若\(|w_i^*| \leq \frac{\alpha}{H_{i,i}}\),正则化后目标中的\(w_i\)的最优解是\(w_i=0\)。因为这个方向上\(L_{emp}(w; X, y)\)的影响被正则化的抵消了。
- 2.若\(|w_i^*| > \frac{\alpha}{H_{i,i}}\),正则化不会推最优解推向0,而是在这个方面上向原点移动了\(\frac{\alpha}{H_{i,i}}\)的距离。
L1正则化及其推导的更多相关文章
- Laplace(拉普拉斯)先验与L1正则化
Laplace(拉普拉斯)先验与L1正则化 在之前的一篇博客中L1正则化及其推导推导证明了L1正则化是如何使参数稀疏化人,并且提到过L1正则化如果从贝叶斯的观点看来是Laplace先验,事实上如果从贝 ...
- L2与L1正则化理解
https://www.zhihu.com/question/37096933/answer/70507353 https://blog.csdn.net/red_stone1/article/det ...
- L1正则化与L2正则化的理解
1. 为什么要使用正则化 我们先回顾一下房价预测的例子.以下是使用多项式回归来拟合房价预测的数据: 可以看出,左图拟合较为合适,而右图过拟合.如果想要解决右图中的过拟合问题,需要能够使得 $ ...
- 【深度学习】L1正则化和L2正则化
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况.正则化是机器学习中通过显式的控制模 ...
- L1正则化比L2正则化更易获得稀疏解的原因
我们知道L1正则化和L2正则化都可以用于降低过拟合的风险,但是L1正则化还会带来一个额外的好处:它比L2正则化更容易获得稀疏解,也就是说它求得的w权重向量具有更少的非零分量. 为了理解这一点我们看一个 ...
- L1正则化
正则化项本质上是一种先验信息,整个最优化问题从贝叶斯观点来看是一种贝叶斯最大后验估计,其中正则化项对应后验估计中的先验信息,损失函数对应后验估计中的似然函数,两者的乘积即对应贝叶斯最大后验估计的形式, ...
- L1正则化和L2正则化
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择 L2正则化可以防止模型过拟合(overfitting):一定程度上,L1也可以防止过拟合 一.L1正则化 1.L1正则化 需注意, ...
- 正则化--L1正则化(稀疏性正则化)
稀疏矢量通常包含许多维度.创建特征组合会导致包含更多维度.由于使用此类高维度特征矢量,因此模型可能会非常庞大,并且需要大量的 RAM. 在高维度稀疏矢量中,最好尽可能使权重正好降至 0.正好为 0 的 ...
- LASSO回归与L1正则化 西瓜书
LASSO回归与L1正则化 西瓜书 2018年04月23日 19:29:57 BIT_666 阅读数 2968更多 分类专栏: 机器学习 机器学习数学原理 西瓜书 版权声明:本文为博主原创文章,遵 ...
随机推荐
- CY7C68013A控制传输
大家好,你们的大熊又回来了.本篇文章我们来重点了解一下USB设备的四大传输方式之一--控制传输.不同于其他三种传输方式,控制传输有其独特的作用和功能,是一个USB设备必须支持的传输方式.控制传输对带宽 ...
- JavaWeb(九)AJAX
Ajax ajax:AJAX 是与服务器交换数据的艺术,它在不重载全部页面的情况下,实现了对部分网页的更新 AJAX:Asynchronous JavaScript and XML,异步 javasc ...
- grep命令中文手册(info grep翻译)
body { font: 13.34px helvetica, arial, freesans, clean, sans-serif; color: black; line-height: 1.4em ...
- 【Linux】ssh免密登录
一.ssh免密配置 ssh 无密码登录要使用公钥与私钥.linux下可以用用ssh-keygen生成公钥/私钥对,下面我以CentOS为例.有机器A(192.168.1.155),B(192.168. ...
- 用xml画水平虚线和竖直虚线.md
1.画水平虚线 直接建一个shape,设置stroke属性就行了,再将这个属性直接作为background的drawable属性引入就行了 注意在4.0以上的真机加一句 <?xml versio ...
- java IO输入输出流实现文本复制
- input长度随输入内容动态变化 input光标定位在最右侧
<input type="text" onkeydown="this.onkeyup();" onkeyup="this.size=(this. ...
- 使用DOM解析XML文件,、读取xml文件、保存xml、增加节点、修改节点属性、删除节点
使用的xml文件 <?xml version="1.0" encoding="GB2312" ?> <PhoneInfo> <Br ...
- HTTP协议Keep-Alive模式详解
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcytp22 HTTP协议Keep-Alive模式详解 1.什么是Keep-Aliv ...
- 第1阶段——关于u-boot目标文件start.o中.globl 和.balignl理解(3)
汇编程序中以.开头的名称并不是指令的助记符,不会被翻译成机器指令,而是给汇编器一些特殊指示,称为伪操作. .globl _start 作用:声明一个_start全局符号(Symbol), 这个_sta ...