python 爬虫实例(一)
一个简单的爬虫工程
环境:
OS:Window10
python:3.7
安装一些库文件
pip install requests
pip install beautifulsoup4
pip install lxml
在安装的时候如果遇到了你的pip版本过低的错误的话,可以找到你本地的C:\Users\XXX\PycharmProjects\getHtml\venv\Lib\site-packages下面的pip-18.1.dist-info文件夹删除,之后在进行更新
下面是提取一个网页的图片代码
import time import requests
import os
import threading from bs4 import BeautifulSoup class BeautifulPicture(): def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}
self.web_url = "https://unsplash.com/"
self.folder_path = r'C:\Users\peiqiang\Desktop\python Pic' def request(self, url):
r = requests.get(url)
return r def mkdir(self, path):
path = path.strip()
isExists = os.path.exists(path)
if not isExists:
print("创建名字叫做", path, "的文件夹")
os.makedirs(path)
print("创建成功!")
else:
print(path, '文件夹已经存在了,不再创建') def save_img(self, url, name):
print('开始保存图片...')
img = self.request(url)
file_name = self.folder_path + '\{}.jpg'.format(name)
print('开始保存文件')
f = open(file_name, 'ab')
f.write(img.content)
f.close()
thread_lock.release()
print(file_name, '文件保存成功!') def get_pic(self):
print('开始网页get请求')
r = self.request(self.web_url)
print('开始获取所有img标签')
all_a = BeautifulSoup(r.text, 'lxml').find_all('img')
print('开始创建文件夹')
self.mkdir(self.folder_path)
print('开始切换文件夹')
os.chdir(self.folder_path)
i=0
for a in all_a:
i += 1
print("開始下載第{}張圖片".format(i))
thread_lock.acquire()
print("抓取圖片的URL:", a["src"])
self.save_img(a["src"], i) thread_lock = threading.BoundedSemaphore(value=10)
beauty = BeautifulPicture()
beauty.get_pic()
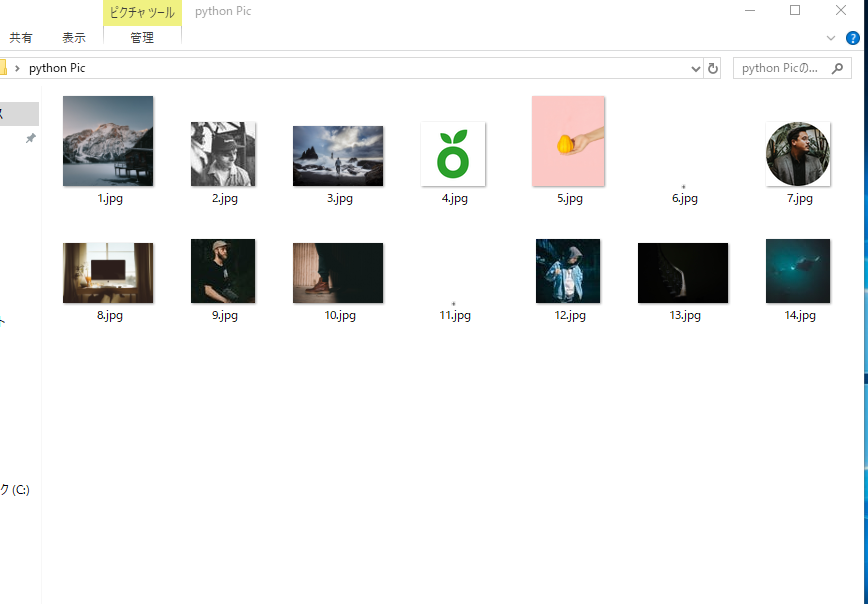
效果如下

本地的存放的路径下
python 爬虫实例(一)的更多相关文章
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python 爬虫实例
下面是我写的一个简单爬虫实例 1.定义函数读取html网页的源代码 2.从源代码通过正则表达式挑选出自己需要获取的内容 3.序列中的htm依次写到d盘 #!/usr/bin/python import ...
- shell及Python爬虫实例展示
1.shell爬虫实例: [root@db01 ~]# vim pa.sh #!/bin/bash www_link=http://www.cnblogs.com/clsn/default.html? ...
- python爬虫实例——爬取歌单
学习自<<从零开始学python网络爬虫>> 爬取酷狗歌单,保存入csv文件 直接上源代码:(含注释) import requests #用于请求网页获取网页数据 from b ...
- Python爬虫实例:糗百
看了下python爬虫用法,正则匹配过滤对应字段,这里进行最强外功:copy大法实践 一开始是直接从参考链接复制粘贴的,发现由于糗百改版导致失败,这里对新版html分析后进行了简单改进,把整理过程记录 ...
- python爬虫实例大全
WechatSogou [1]- 微信公众号爬虫.基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典. DouBanSpider [2]- ...
- Python 爬虫实例(爬百度百科词条)
爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入 ...
- Python爬虫实例(三)代理的使用
一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,如果访问频率太快以至于看起来不像正常访客,它可能就会会禁止这个IP的访问.所以我们需要设置一些代理服务器,每隔一段时间换一 ...
随机推荐
- 【一起来烧脑】读懂HTTP知识体系
背景 读懂HTTP很重要,参加过面试的小伙伴都很清楚,无论是技术面试面试题出得怎样,都有机会让你讲解一下HTTP,大部分都会问一下. 面试官:考考你网络协议的知识,TCP协议和UDP协议的区别,HTT ...
- Kafka 深入核心参数配置
Kafka 真是一个异常稳定的组件,服务器上我们部署了 kafka_2.11-1.0.1 版本的 kafka 除了几次计算时间太长触发了 rebalance 以外,基本没有处理过什么奇怪的问题. 但是 ...
- P5025 [SNOI2017]炸弹
原题链接 https://www.luogu.org/problem/P5025 闲话时刻: 第一道 AC 的黑题,虽然众人皆说水... 其实思路不是很难,代码也不是很难打,是一些我们已经学过的东西 ...
- ZR#1009
ZR#1009 解法: 因为无敌的SR给了一个大暴力算法,所以通过打表发现了了一些神奇的性质,即第一行和第一列的对应位置数值相等. 我们可以通过手算得出 $ F(n) = \frac{n(n + 1) ...
- html转图片/html2canvas的使用/星座测试/类似于损友圈的活动
https://try.fishqc.com/Activity/constellation ---成品 电脑上录的gif 有借鉴的链接,很多,下面这个还不错~先别看,尊重下我先~~~~ https:/ ...
- 普通的checkbox的回显功能
var ypxt=document.getElementsByName("map.LCSYLB"); var jgjg='${map.LCSYLB}'; ...
- pymongo错误记录
1.AutoReconnect pymongo.errors.AutoReconnect: connection closed 2.ServerSelectionTimeoutError pymong ...
- CSS(1)
使用CSS的注意点: 1.style标签必须写在head标签的开始标签和结束标签之间(也就是必须和title标签是兄弟关系). 2.style标签中的type属性其实可以不用写,默认就是type=&q ...
- REDIS中加锁和解锁问题
使用lua+redis的方法.之所以使用lua是为了保证原子性 问题: 1. redis发现锁失败了要怎么办?中断请求还是循环请求?2. 循环请求的话,如果有一个获取了锁,其它的在去获取锁的时候,是不 ...
- List和Array相互转换
List<String> list = new ArrayList<String>(); list.add("1"); list.add("2&q ...