Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~
1. 准备工作:
安装Scrapy框架、MongoDB和PyMongo库,如果没有安装,google了解一下~~
2. 创建项目:
使用命令创建Scrapy项目,命令如下:
scrapy startproject tutorial
该命令可以在任意文件夹运行,如果提示权限问题,可以加sudo运行。该命令会创建一个名为tutorial的文件夹,结构如下:

# scrapy.cfg: Scrapy项目的配置文件,定义了项目的配置文件路径,部署相关信息等
# item.py: 定义item数据结构(爬取的数据结构)
# pipeline.py: 定义数据管道
# settings.py: 配置文件
# middlewares.py: 定义爬取时的中间件
# spiders: 放置Spiders的文件夹
3. 创建Spider:
Spider是自己定义的类,Scrapy用它来从网页抓取内容,并解析抓取结果。该类必须继承Scrapy提供的Spider类scrapy.Spider。
使用命令创建一个Spider,命令如下:
cd tutorial
scrapy genspider quotes quotes.toscrape.com
首先,进入刚才创建的tutorial文件夹,然后执行genspider命令。第一个参数是spider的名称,第二个参数是网络域名(要抓取网络的域名)。执行完毕后,spiders文件夹中多了一个quotes.py,它就是刚刚创建的Spider,内容如下:
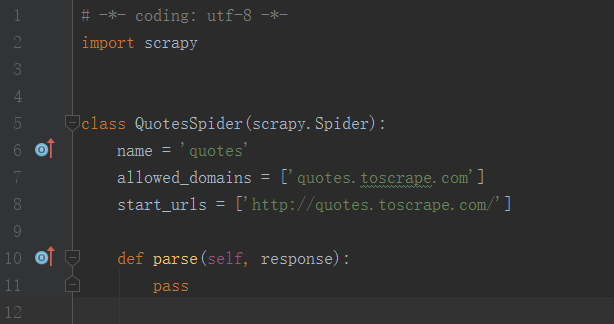
该类中有三个属性 ------ name、allowed_domains、start_urls,一个方法parse。
# name,唯一的名字,用来区分不同的Spider。
# allowed_domains,允许爬取的域名,如果初始或后续的请求链接不是该域名下的,则被过滤掉。
# start_urls,Spider在启动时爬取的url列表,用来定义初始的请求。
# parse,它是spider的一个方法,用来处理start_urls里面的请求返回的响应,该方法负责解析返回的响应,提取数据或进一步生成处理的请求。
4. 创建Item:
Item是保存爬取数据的容器,使用方法和字典类似。创建Item需要继承scrapy.Item类,并且定义类型为scrapy.Field的字段。
定义Item,将生成的items.py修改如下:
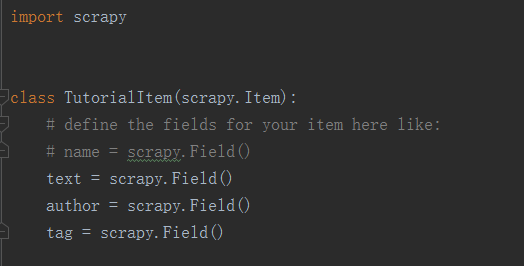
这里定义了三个字段,接下来爬取时我们会用到这个Item。
5. 解析Response:
前面我们看到,parse()方法的参数response是start_urls里面的链接爬取后的结果,所以在parse方法中,可以对response变量包含的内容进行解析。网页结构如下:


提取方式可以是CSS选择器或XPath选择器。在这里,使用CSS选择器,parse()方法修改如下:

首先,利用选择器选取所有的quote,并将其赋值给quotes变量,然后利用for循环对每一个quote遍历,解析每一个quote的内容。
对text来说,他的class是text,所以用.text选择器来选取,这个结果实际上是整个带有标签的节点,要获取它的正文内容,可以加::text来获取。这时的结果是长度为1的列表,所以还需要用extract_first()方法来获取第一个元素。
而对于tags来说,由于我们要获取所有的标签,所以用extract()方法来获取整个列表即可。
6. 使用Item:
上面定义了Item,这边我们就需要用到它。Item可以理解为一个字典,不过在这里需要先实例化,然后将解析的结果赋值给Item的每一个字段,最后返回Item。
修改QuotesSpider类如下:

至此,首页的所有内容被解析出来了,并将结果赋值给一个个TutorialItem。
7. 后续Request:
上面实现了网页首页的抓取解析,那么下一页怎么抓取呢?我们可以看到网页的翻页结构如下:

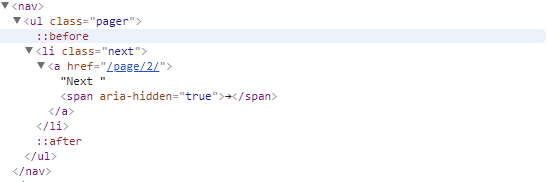
这里有一个Next按钮,查看源码,可以看出下一页的全链接是:http://quotes.toscrape.com/page/2/,通过这个链接我们就可以构造下一个请求。
构造请求需要用到scrapy.Request。这里会有两个参数 -------url和callback。
# url,请求链接。
# callback,回调函数。请求完毕后,获取响应,引擎会将该响应作为参数传递给回调函数,回调函数进行解析或生成下一个请求。
在parse()方法中追加如下代码:

第一句,获取下一个页面的链接,即要获取a超链接中的href属性。
第二句,调用urljoin()方法,urljoin()方法可以将相对URL构造成一个绝对URL。例如,获取得到下一页的地址是/page/2/,urljoin()方法处理后的结果是:http://quotes.toscrape.com/page/2/。
第三句,通过url和callback变量构造了一个新的请求,回调函数callback依然使用parse()方法。这样,爬虫就进入了一个循环,直到最后一页。
修改之后,整个Spider类如下:

8. 运行:
进入目录,运行如下命令:
scrapy crawl quotes
就可以看到Scrapy的运行结果了。
9. 保存到文件:
运行完Scrapy后,我们只在控制台看到了输出结果。如何保存结果呢?
Scrapy提供了Feed Exports可以轻松将结果输出。例如,我们想将上面的结果保存成JSON文件,可以执行如下命令:
scrapy crawl quotes -o quotes.json
命令运行后,会发现项目内多了一个quotes.json文件,这个文件包含了抓取的所有内容,格式为JSON。
另外,还支持其他格式如下:
scrapy crawl quotes -o quotes.jsonlines (scrapy crawl quotes -o quotes.jl , jl是jsonlines的缩写)
scrapy crawl quotes -o quotes.csv
scrapy crawl quotes -o quotes.xml
scrapy crawl quotes -o quotes.pickle
scrapy crawl quotes -o quotes.marshal
scrapy crawl quotes -o ftp://user:pass@ftp.example.com/path/to/quotes.csv (远程输出,需要正确配置,否则会报错)
10. 使用Pipeline:
如果想进行复杂额操作,如将结果保存到MongoDB数据库,或者筛选Item,我们可以定义Pipeline来实现。
前面提到,Pipeline是项目管道,当Item生成后,它会自动被送到Pipeline进行处理,主要的操作如下:
# 清理HTML数据
# 验证爬取的数据,检查爬取的字段
# 查重并丢弃重复内容
# 将结果保存到数据库
实现Pipeline,只需要定义一个类并实现process_item()方法即可。启用Pipeline后,Pipline会自动调用这个方法。process_item()方法必须返回包含数据的字典或item对象,或者抛出DropItem异常。
process_item()方法有两个参数,一个参数是item,每次Spider生成的Item都会作为参数传递过来,另一个参数是spider,就是Spider的实例。
接下来,我们实现一个Pipline,筛掉text长度大于50的Item,并将结果保存到MongoDB数据库。
修改pipelines.py如下:


# from_crawler,这是一个类方法,用@classmethod标识,是一种依赖注入。它的参数就是crawler,通过crawler可以拿到全局配置的每一个配置信息。在全局配置settings.py中,可以配置MONGO_UR和MONGO_DB来指定MongoDB连接需要的地址和数据库名称,拿到配置信息之后返回类对象即可。所以这个方法主要是用来获取settings.py中的配置信息。
# open_spider,当Spider开启时,这个方法被调用。进行初始化操作。
# close_spider,当Spider关闭时,这个方法被调用。将数据库连接关闭。
最主要的process_item()方法则进行了数据插入操作。
定义好的TutorialPipeline和MongoPipline这两个类后,我们需要在settings.py中使用它们,MongoDB的连接信息也需要在settings.py中定义。
settings.py中加入如下内容:

赋值ITEM_PIPELINES字典,键名是Pipeline的类名称,键值是调用的优先级,是一个数字,数字越小对应的Pipeline越先被调用。
重新执行如下命令进行爬取:
scrapy crawl quotes
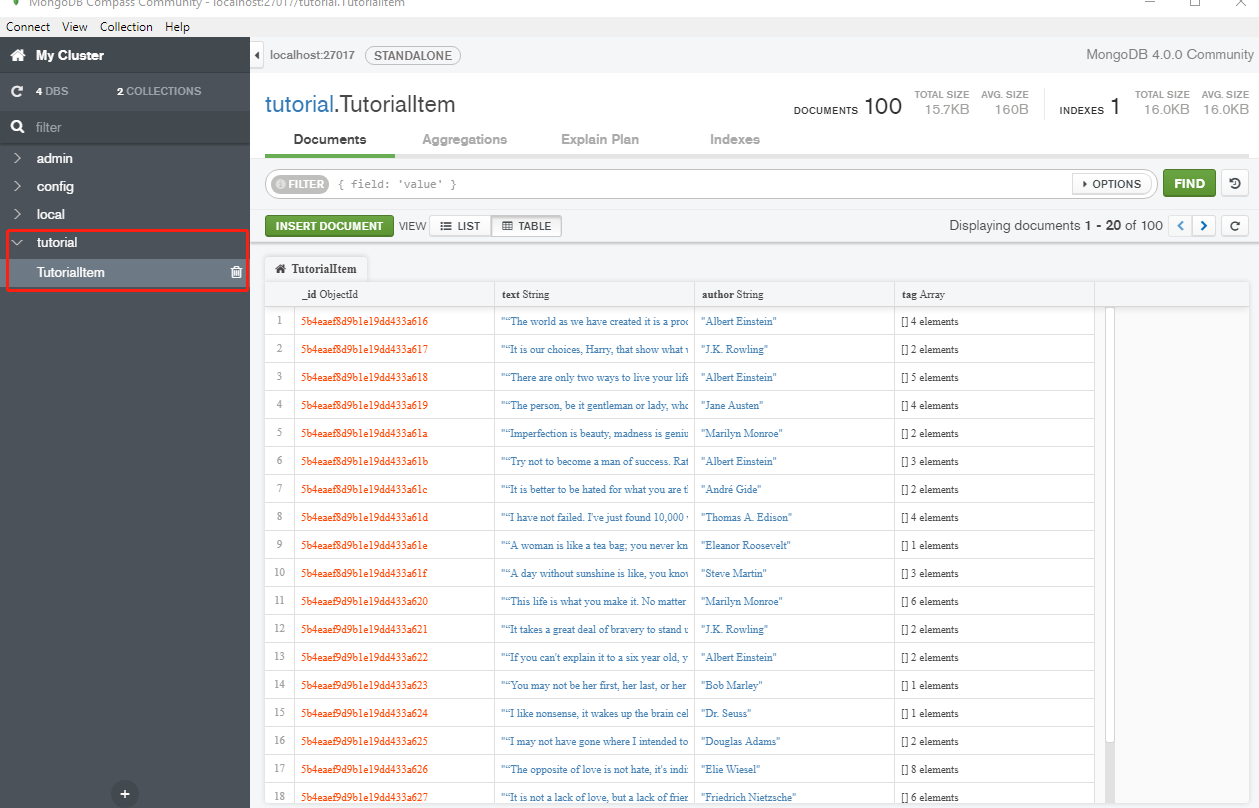
结束后,MongoDB中会创建了一个tutorial的数据库、TutorialItem的表,如下图:
11. 结语:
至此,一个简单的Scrapy框架爬虫就完成了,这只是一个简单的爬虫例子,想要了解更多,可以去看看崔庆才的书---------《Python3 网络爬虫开发实战》。
Github上面也有许多相关的项目可以去研究~~~
Scrapy框架-----爬虫的更多相关文章
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录 模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于star ...
- 第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用
第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用 xpath表达式 //x 表示向下查找n层指定标签,如://div 表示查找所有div标签 /x 表示向下查找一层指定的标签 ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
- Python爬虫进阶(Scrapy框架爬虫)
准备工作: 配置环境问题什么的我昨天已经写了,那么今天直接安装三个库 首先第一步: ...
- python scrapy框架爬虫遇到301
1.什么是状态码301 301 Moved Permanently(永久重定向) 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一.如果可能,拥有链接编 ...
- Scrapy框架爬虫
一.sprapy爬虫框架 pip install pypiwin32 1) 创建爬虫框架 scrapy startproject Project # 创建爬虫项目 You can start your ...
- 十二 web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于start_urls,start_requests()返回的请求会替代start_urls里 ...
随机推荐
- 【spring源码分析】准备工作
前言:之前写过两篇基于xml形式的IOC容器初始化过程,现在看来写的比较烂,最近又继续阅读spring源码,对IOC容器的初始化有了一些新的认识,因此决定记录下来,加深自己对spring的印象与理解. ...
- Django-CRM项目学习(二)-模仿admin实现stark
开始今日份整理 1.stark模块基本操作 1.1 stark模块的启动 保证django自动的加载每一个app下的stark.py文件 创建django项目,创建stark项目,start app ...
- JS 数组去重的几种方式
JS 常见的几种数组去重方法 一.最简单方法(indexOf 方法) 实现思路:新建一个数组,遍历要去重的数组,当值不在新数组的时候(indexOf 为 -1)就加入该新数组中: function u ...
- git方法 GUI here
注:stage changed是将所有修改归集到一次commit,如果要分开commit,则应该使用ctrl+t来一个一个文件的stage
- 好久好久没写,,百度API逆地址解析以及删除指定marker
百度地图Api中 除覆盖物有两个方法:map.removeOverlay()或者 map.clearOverlays(),其中 clearOverlays()方法一次移除所有的覆盖物removeOve ...
- Platform.Uno介绍
编者语:Xamarin国内很多人说缺乏可用的实例,我在写书过程中在完善一些常用场景的例子,希望帮到大家.Build 2018结束一周了,善友问我要不要谈谈Xamarin的一些变化,但碍于时间有限一直没 ...
- Nginx ACCESS阶段 Satisfy 指令
L:60 这里一定要记住 return 指令所对应的阶段 早与access 因此如果location 有return 的话 那么 deny可能都会失效
- LoadRunner【第三篇】录制脚本实践:订票网站
启动服务 安装好loadrunner,我们就可以实践了. loadrunner自带订票网站,可以方便我们练习, 先把下面两个发送到桌面快捷方式 首先,启动服务,点击下面图标(如果服务无法启动,检查端口 ...
- (转)史上最全 40 道 Dubbo 面试题及答案,看完碾压面试官!
背景:因为自己的简历写了dubbo,面试时候经常被问到.实际自己对dubbo的认识只停留在使用阶段,所以有必要好好补充下基础的理论知识. https://zhuanlan.zhihu.com/p/45 ...
- Eclipse 添加 Source 源代码、Javadoc 文档
源代码 Source 按住 Ctrl 键,鼠标放到对应的类.方法上,出现 Open Declaration,Open Implementation ,可查看对应的实现.声明源代码. 也可以在[Proj ...