简易数据分析 11 | Web Scraper 抓取表格数据

这是简易数据分析系列的第 11 篇文章。
今天我们讲讲如何抓取网页表格里的数据。首先我们分析一下,网页里的经典表格是怎么构成的。
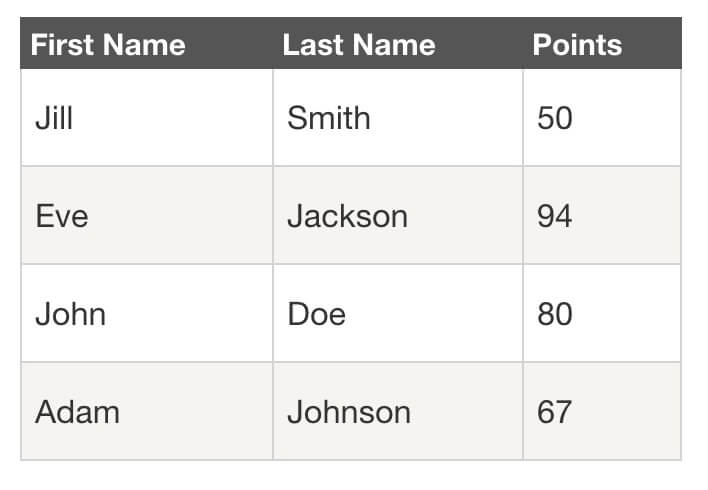
First Name所在的行比较特殊,是一个表格的表头,表示信息分类- 2-5 行是表格的主体,展示分类内容
经典表格就这些知识点,没了。下面我们写个简单的表格 Web Scraper 爬虫。
1.制作 Sitemap
我们今天的练手网站是
http://www.huochepiao.com/search/chaxun/result.asp?txtChuFa=%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们先创建一个包含整个表格的 container,Type 类型选为 Table,表示我们要抓取表格。

具体的参数如上图所示,因为比较简单,就不多说了。
在这个面板下向下翻,会发现多了一个不一样的面板。观察一下你就会发现,这些数据其实就是表格数据类型的分类,在这个案例里,他把车次、出发站、开车时间等分类都列了出来。

在 Table columns 这个分类里,每一行的内容旁边的选择按钮默认都是打勾的,也就是说默认都会抓取这些列的内容。如果你不想抓取某类内容,去掉对应的勾选就可以了。
在你点击 Save selector 的按钮时,会发现 Result key 的一些选项报错,说什么 invalid format 格式无效:

解决这个报错很简单,一般来说是 Result key 名字的长度不够,你给加个空格加个标点符号就行。如果还报错,就试试换成英文名字:

解决报错保存成功后,我们就可以按照 Web Scraper 的爬取套路抓取数据了。
2.为什么我不建议你用 Web Scraper 的 Table Selector?
如果你按照刚刚的教程做下里,就会感觉很顺利,但是查看数据时就会傻眼了。
刚开始抓取时,我们先用 Data preview 预览一下数据,会发现数据很完美:
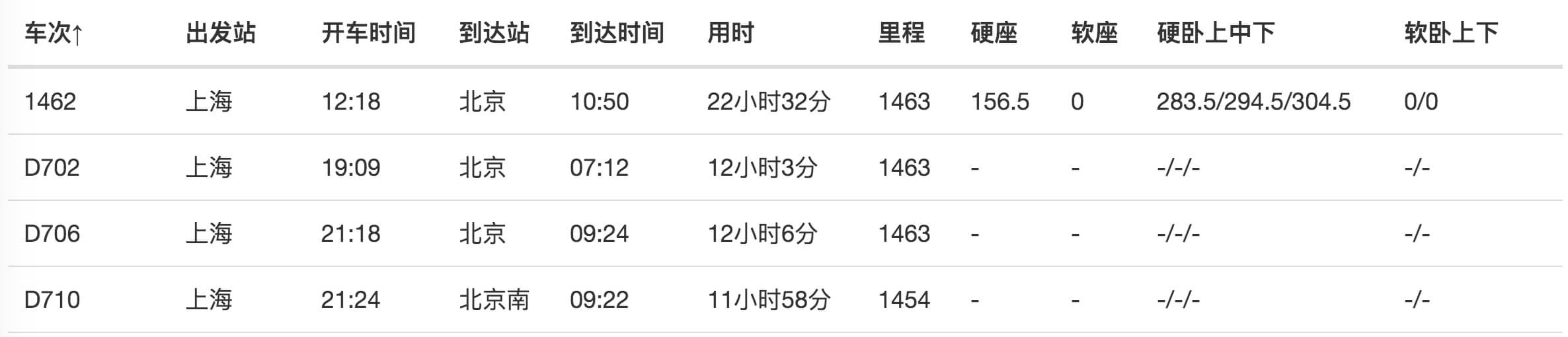
抓取数据后,在浏览器的预览面板预览,会发现车次这一列数据为 null,意味着没有抓取到相关内容:
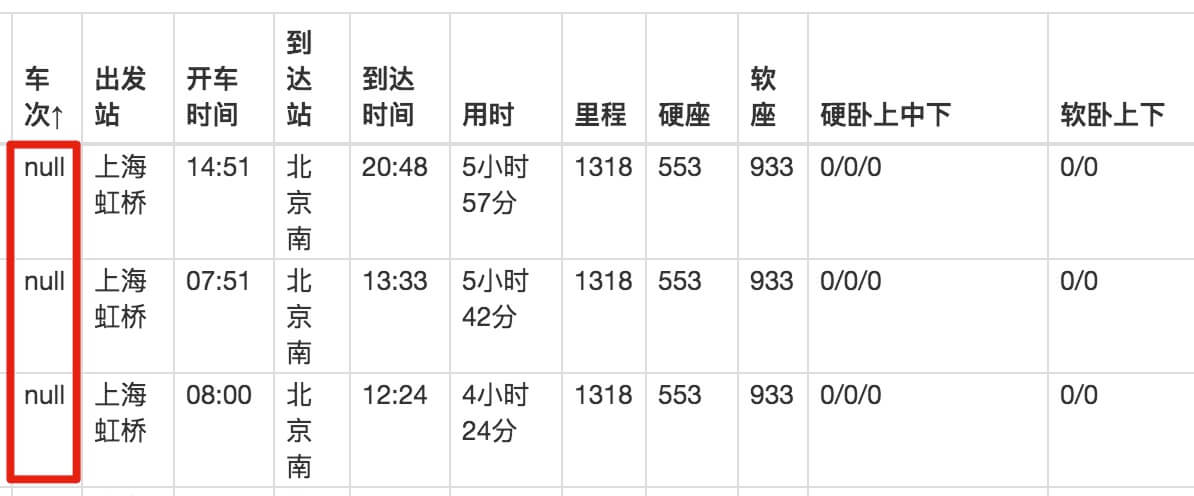
我们下载抓取的 CSV 文件后,在预览器里打开,会发现车次的数据出现了,但出发站的数据又为 null 了!

这不是坑爹呢!
关于这个问题我调查了半天,应该是 Web Scraper 对中文关键字索引的支持不太友好,所以会抛出一些诡异的 bug,因此我并不建议大家用它的 Table 功能。
如果真的想抓取表格数据,我们可以用之前的方案,先创建一个类型为 Element 的 container,然后在 container 里再手动创建子选择器,这样就可以规避这个问题。
上面只是一个原因,还有一个原因是,在现代网站,很少有人用 HTML 原始表格了。
HTML 提供了表格的基础标签,比如说 <table>、 <thead>、 <tbody> 等标签,这些标签上提供了默认的样式。好处是在互联网刚刚发展起来时,可以提供开箱即用的表格;缺点是样式太单一,不太好定制,后来很多网站用其它标签模拟表格,就像 PPT里用各种大小方块组合出一个表格一样,方便定制:

出于这个原因,当你在用 Table Selector 匹配一个表格时,可能会死活匹配不上,因为从 Web Scraper 的角度考虑,你看到的那个表格就是个高仿,根本不是原装正品,自然是不认的。
3.总结
我们并不建议直接使用 Web Scraper 的 Table Selector,因为对中文支持不太友好,也不太好匹配现代网页。如果有抓取表格的需求,可以用之前的创建父子选择器的方法来做。
4.推荐阅读
简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页

简易数据分析 11 | Web Scraper 抓取表格数据的更多相关文章
- 简易数据分析 07 | Web Scraper 抓取多条内容
这是简易数据分析系列的第 7 篇文章. 在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息: 在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息: 今天我们要讲的是,如何抓取多个网页里的多 ...
- 简易数据分析 13 | Web Scraper 抓取二级页面
这是简易数据分析系列的第 13 篇文章. 不知不觉,web scraper 系列教程我已经写了 10 篇了,这 10 篇内容,基本上覆盖了 Web Scraper 大部分功能.今天的内容算这个系列的最 ...
- web scraper 抓取网页数据的几个常见问题
如果你想抓取数据,又懒得写代码了,可以试试 web scraper 抓取数据. 相关文章: 最简单的数据抓取教程,人人都用得上 web scraper 进阶教程,人人都用得上 如果你在使用 web s ...
- web scraper 抓取分页数据和二级页面内容
如果是刚接触 web scraper 的,可以看第一篇文章. web scraper 是一款免费的,适用于普通用户(不需要专业 IT 技术的)的爬虫工具,可以方便的通过鼠标和简单配置获取你所想要数据. ...
- 简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
这是简易数据分析系列的第 8 篇文章. 我们在Web Scraper 翻页--控制链接批量抓取数据一文中,介绍了控制网页链接批量抓取数据的办法. 但是你在预览一些网站时,会发现随着网页的下拉,你需要点 ...
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
- 简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
这是简易数据分析系列的第 4 篇文章. 今天我们开始数据抓取的第一课,完成我们的第一个爬虫.因为是刚刚开始,操作我会讲的非常详细,可能会有些啰嗦,希望各位不要嫌弃啊:) 有人之前可能学过一些爬虫知识, ...
- 简易数据分析 09 | Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器
这是简易数据分析系列的第 9 篇文章. 今天我们说说 Web Scraper 的一些小功能:自动控制 Web Scraper 抓取数量和 Web Scraper 的父子选择器. 如何只抓取前 100 ...
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...
随机推荐
- mysql_fetch_assoc与mysql_fetch_array的区别
mysql_fetch_assoc与mysql_fetch_array的区别? 1. mysql_fetch_assoc : mysql_fetch_assoc() 函数从结果集中取得一行作为关联数组 ...
- MySql 命令(命令行)
1.连接Mysql 格式: mysql -h主机地址 -u用户名 -p用户密码1.连接到本机上的MYSQL. 首先打开DOS窗口,然后进入目录mysql\bin,再键入命令mysql -u root ...
- 在父页面用Iframe加载子页面时,将父页面的title替换成子页面title
报告管理
- IO-文件输出流
一.输出流的原理 Java向文件中写数据的原理 Java程序-->JVM(java虚拟机)-->OS(操作系统)-->OS调用写数据的方法-->把数据写入到文件中 tips: ...
- Tips 14:思维导图读书笔记法
Tips 14:思维导图读书笔记法作读书笔记不仅能提高阅读书.文的效率,而且能提高科学研究和写作能力.读书笔记一般分为摘录.提纲.批注.心得几种,这里特别推荐思维导图式的读书笔记. 通过思维导图先大概 ...
- [机器学习] SVM——Hinge与Kernel
Support Vector Machine [学习.内化]--讲出来才是真的听懂了,分享在这里也给后面的小伙伴点帮助. learn from: https://www.youtube.com/wat ...
- Web访问原理-从输入URL到页面加载完成的过程中都发生了什么事情?
从输入URL到页面加载完成的过程中都发生了什么事情?--这是一个经典的面试题: 主要是关于计算机网络方面的知识基础,对于非科班计算机自学web开发的同学可能理解起来就很困难. StackOverFlo ...
- Selenium浏览器自动化测试框架
selenium简介 介绍 Selenium [1] 是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE(7, 8, 9, 1 ...
- 洛谷P1003 题解
题面 思路一:纯模拟.(暴力不是满分) 思路: 1.定义一个二维数组. 2.根据每个数据给二维数组赋值. 3.最后输出那个坐标的值. 思路二(正规思路): 逆序找,因为后来的地毯会覆盖之前的,一发现有 ...
- 字符串(String、StringBuffer、StringBuilder)进阶分析
转载自https://segmentfault.com/a/1190000002683782 我们先要记住三者的特征: String 字符串常量 StringBuffer 字符串变量(线程安全) St ...