关于爬取babycenter.com A-Z为顺序的所有英文名及其详细属性
这一次爬取的内容已经在标题里提到了,下面是详细要求及其图示:
1、首先以A-Z的顺序获取所有英文名,最后爬取该英文名的详细信息。
2、CSV的header以3中的单词为准,请别拼错。如果没有对应的数据,该列留空。
3、最终CSV中的字段名以此为准:EnName,CnName,Gender,Meaning,Description,Source,Character,Celebrity,WishTag
4、请遵守爬虫协议,先保存html至本地,学习并掌握bs4解析规则,切勿频繁请求主机。

网站的url是:“https://www.babycenter.com/babyNamerSearch.htm?startIndex=0&gender=MALE&batchSize=40&startsWith=A”
首先开始构思整体的爬取思想:
我把整个项目功能模块切分成为4个:爬虫控制器、url管理器、网页请求器、网页分析器和数据输出器
爬虫程序的运行流程说明如下:
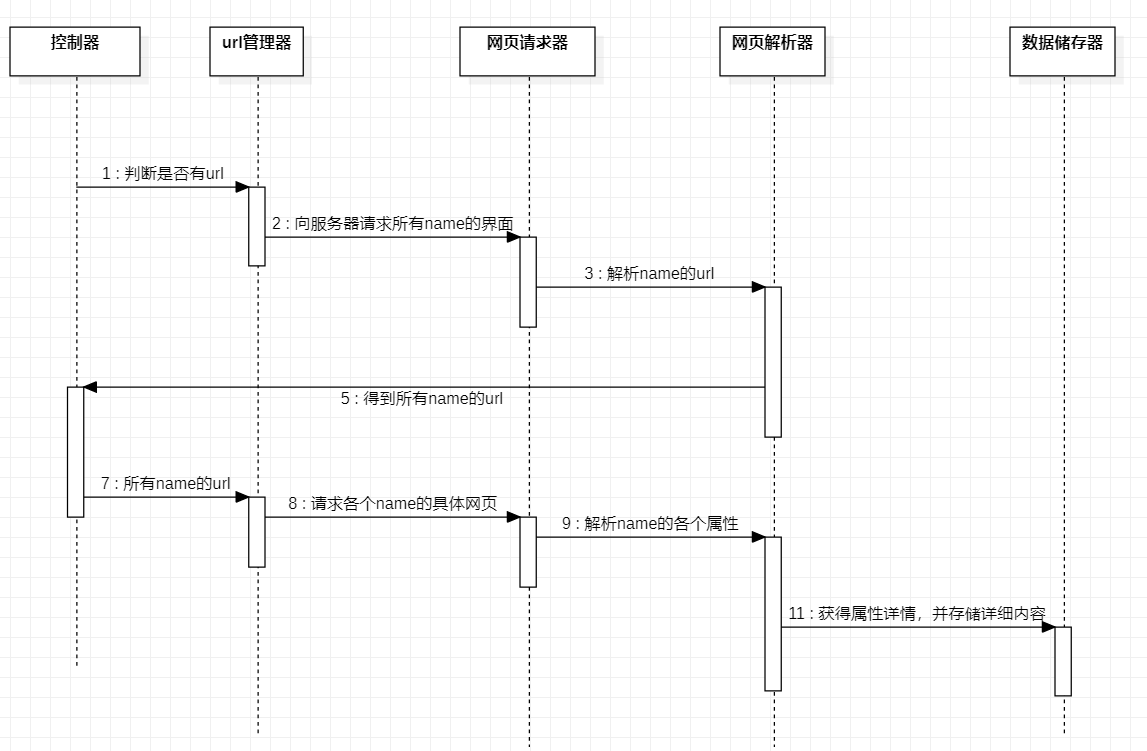
(1)控制器通过for循环获得以A-Z开头为名字的所有页面。
(2)url管理器获得控制器传来的url以后将所有的连接传给网页请求器,网页请求器通过requests向服务器进行请求,并将请求结果传给网页解析器
(3)网页解析器针对网页请求器传来的一系列url进行解析,获得每个页面中英文名相对应的href,将href打包放入网页请求器
(4)网页请求器获取到href开始请求,请求的结果再次传到网页解析器之中。
(5)网页解析器开始分析相关网页,并选取需要的内容进行打包处理,处理完以后的数据将被以list的形式传送到数据存储器。
(6)存储器接收到来自网页解析器传来的数据据以后,开始以csv的形式存入文档之中。程序运行完毕
我用流程图和时序图来解释一下各功能模块之间的合作流程:

时序图:
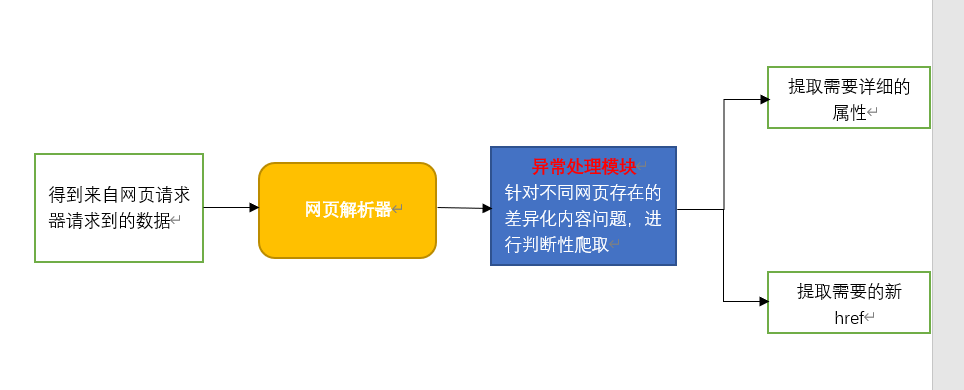
重点讲解一下这里的网页解析器:
网页解析器是从网页中提取有价值数据的工具。
Python常用的解析器有四种,一是正则表达式,二是html.parser,三是beautifulSoup,四是lxml。
这里我选用的是beautifulSoup作为我的网页解析器,相对于正则表达式来说,使用beautifulSoup来解析网页更为简单。
beautifulSoup将网页转化为DOM树来解析,每一个节点是网页的每个标签,通过它提供的方法,你可以很容易的通过每个节点获取你想要的信息。
本功能模块除拥有正常爬取功能外,添加了异常处理功能,这是因为在爬取BabyCenter.com网站中,各name的详情网页中What does Aiden mean?栏目中存在不同的html设计,针对该差异化问题,若不加以处理,爬取过程有几率报错。故添加由try方法组成的异常处理模块,保证爬取过程的顺利。
图解功能块:
还有这里说明一下为什么需要调用两次网页解析器
第一次调用网页解析器的原因是需要在首页找到所有英文名所对应的href:
之所以要通过解析器来find英文名的的地址
是因为这个网站的每个英文名的href不是按照惯例类型:‘www.!@#¥%&*NAME={某英文名}.com’
而是‘www.!@#¥%&*NAME={某英文名+一串没有无规律的数字}.com’
由于找不到规律,无法通过for循环name=‘xxx’挨个进入网站,故需要进入首页调取英文名对应的href
实现代码可参见下图:

剩余的步骤,如果按照惯例的话,只需要for循环将url传到下一函数中进行find属性内容就可以了
但是!!
每当我爬取description和character的内容时候,系统都会报错:
第一类报错是无法获取character的内容
第二类是根本无法获取description和character,找不到属性
在反复比对完网页以后,我发现BabyCenter.com这个网站的排版很奇特
你可以看到三种设计:
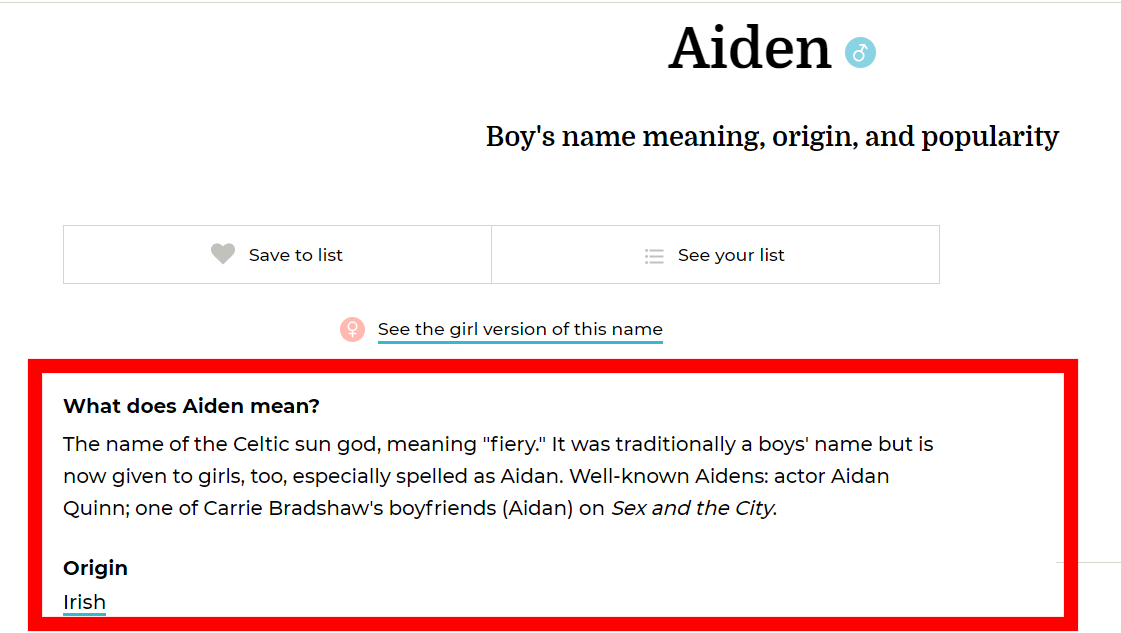
第一种版型
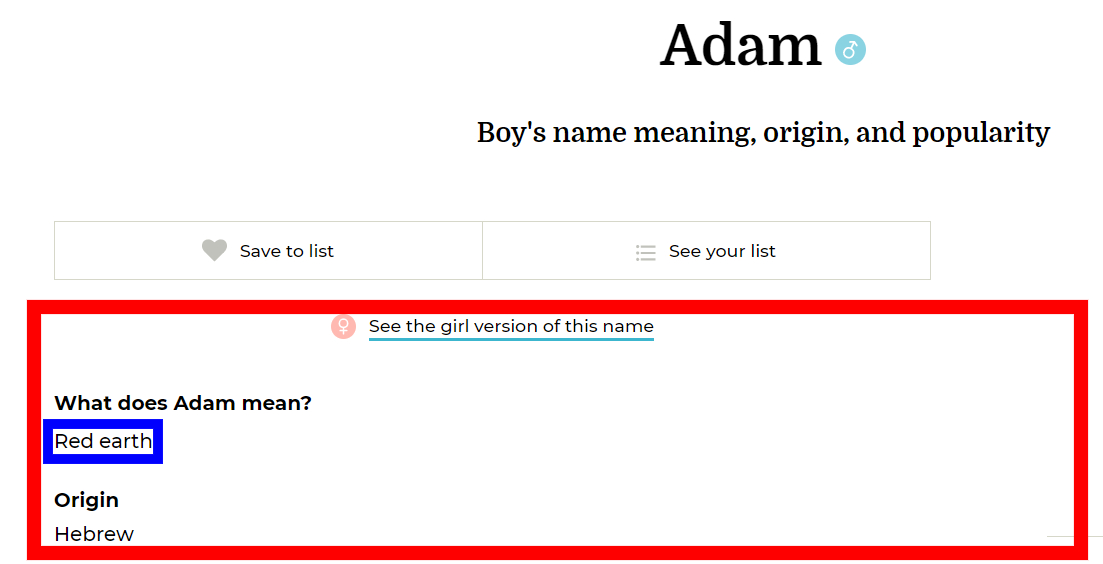
第二种版型
第三种版型
解决方案:运用try,except方法进行爬取,
当爬取报错的时候跳转到另外的一个try方法之中进行爬取,
三种版型运用两个try方法。详细代码见图:
def getDESandCHAR(EveryName,EveryHref):#获取description和character
descriptions=[]
characters=[]
Content=[]
for i in range(len(EveryName)):
url = EveryHref[i]
kv = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
Res = requests.get(url,headers=kv).text
demo=BeautifulSoup(Res,'html.parser')
try:#此处开始第一次尝试,是否存在bodytext,如果不存在,则description和characters全部返还none
ss = (' Well-known ','Aiden','s: ')
k = ''.join(ss).replace('\n','')
x = demo.find('div',{'class':'spacer'}).find('p',{'class':'bodyText'}).text.split(k,1)
print(x[0].replace(',',',').replace("'",'').replace('/',' ').replace('\n',''))
descriptions.append(x[0])
try:#此处开始尝试查询是否存在characters,如果不存在则返还none
print(x[1].replace(',',',').replace("'",'').replace('/',' ').replace('\n',''))
characters.append(x[1])
except:#尝试失败,返还characters返还none
print('none')
characters.append('none')
except:#尝试失败,descriptions和characters全部返还none
descriptions.append('none')
characters.append('none')
Content=[descriptions,characters]#两属性放入一个表格之中,return一个参数
return Content
还有source部分也和上述部分差不多
代码下一次有时间再上吧
关于爬取babycenter.com A-Z为顺序的所有英文名及其详细属性的更多相关文章
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- Python爬虫学习(6): 爬取MM图片
为了有趣我们今天就主要去爬取以下MM的图片,并将其按名保存在本地.要爬取的网站为: 大秀台模特网 1. 分析网站 进入官网后我们发现有很多分类: 而我们要爬取的模特中的女模内容,点进入之后其网址为:h ...
- 微信公众号批量爬取java版
最近需要爬取微信公众号的文章信息.在网上找了找发现微信公众号爬取的难点在于公众号文章链接在pc端是打不开的,要用微信的自带浏览器(拿到微信客户端补充的参数,才可以在其它平台打开),这就给爬虫程序造成很 ...
- 学习用java基于webMagic+selenium+phantomjs实现爬虫Demo爬取淘宝搜索页面
由于业务需要,老大要我研究一下爬虫. 团队的技术栈以java为主,并且我的主语言是Java,研究时间不到一周.基于以上原因固放弃python,选择java为语言来进行开发.等之后有时间再尝试pytho ...
- Python爬取南京市往年天气预报,使用pyecharts进行分析
上一次分享了使用matplotlib对爬取的豆瓣书籍排行榜进行分析,但是发现python本身自带的这个绘图分析库还是有一些局限,绘图不够美观等,在网上搜索了一波,发现现在有很多的支持python的绘图 ...
- Python爬虫入门教程 14-100 All IT eBooks多线程爬取
All IT eBooks多线程爬取-写在前面 对一个爬虫爱好者来说,或多或少都有这么一点点的收集癖 ~ 发现好的图片,发现好的书籍,发现各种能存放在电脑上的东西,都喜欢把它批量的爬取下来. 然后放着 ...
- 03:requests与BeautifulSoup结合爬取网页数据应用
1.1 爬虫相关模块命令回顾 1.requests模块 1. pip install requests 2. response = requests.get('http://www.baidu.com ...
- Python爬虫入门教程: All IT eBooks多线程爬取
All IT eBooks多线程爬取-写在前面 对一个爬虫爱好者来说,或多或少都有这么一点点的收集癖 ~ 发现好的图片,发现好的书籍,发现各种能存放在电脑上的东西,都喜欢把它批量的爬取下来. 然后放着 ...
- 【nodejs 爬虫】使用 puppeteer 爬取链家房价信息
使用 puppeteer 爬取链家房价信息 目录 使用 puppeteer 爬取链家房价信息 页面结构 爬虫库 pupeteer 库 实现 打开待爬页面 遍历区级页面 方法一 方法二 遍历街道页面 遍 ...
随机推荐
- Java通过 Scanner 类来获取用户的输入
通过 Scanner 类来获取用户的输入. import java.util.Scanner; Scanner s = new Scanner(System.in);// 从键盘接收数据 Syste ...
- 100天搞定机器学习|Day57 Adaboost知识手册(理论篇)
Boosting算法 Boosting是一种用来提高弱分类器准确度的算法,是将"弱学习算法"提升为"强学习算法"的过程,主要思想是"三个臭皮匠顶个诸葛 ...
- Java8 Stream终端操作使用详解
话不多说,自己挖的坑自己要填完,今天就给大家讲完Java8中Stream的终端操作使用详解.Stream流的终端操作主要有以下几种,我们来一一讲解. forEach() forEachOrdered( ...
- 【数据结构】之栈(Java语言描述)
在前面的[这篇文章]中,我简单介绍了栈这种数据结构的操作功能,并使用C语言对其进行了代码的编写. Java的JDK中默认为我们提供了栈这种数据结构的API—— Stack . Java中的Stack类 ...
- HUB-交换机-路由器
HUB集线器-物理层 工作原理: 机器1发送一个数据(广播发送),经过集线器hub,hub会转发到其他所有机器,其他机器接收到数据,如果数据是给自己的就收下,如果不是自己的就丢弃 集线器的作用?(su ...
- 【JZOJ】3490. 旅游题解报告
题目 思路 这道题看上去就像一个动态规划!但是还是要把矩阵压成一行. 然后按 \(A\)数组 将结构体从小到大排个序. 随后我们开始了动规标准步骤: 确定状态 很显然, \(f_i\) 表示游览完第\ ...
- js的模糊查询
在项目中会用到模糊查询,之前在首页是用的element的tree显示的目录,会有用到搜索,但tree里边会有自带的模糊查询,用filter-node-method方法使用 但上次的项目中 又涉及到不试 ...
- Spring Boot SpringApplication启动类(一)
目录 目录 前言 1.起源 2.SpringApplication 准备阶段 2.1.推断 Web 应用类型 2.2.加载应用上下文初始器 ApplicationContextInitializer ...
- 用launchscreen.storyboard适配启动图方法(二)
背景 之前有写一篇实现方式比较简单的随笔用launchscreen.storyboard适配启动图方法,顺便在评论区提了一下用autolayout适配启动图的思路,现把思路和流程记录下来. 思路 整体 ...
- nginx的部署及配置文件的介绍 域名 用户认证 SSL加密模块
步骤一:构建Nginx服务器 yum -y install gcc pcre-devel openssl-devel #安装依赖包 wget http://nginx.org/dow ...