吴裕雄 python 爬虫(3)
import hashlib md5 = hashlib.md5()
md5.update(b'Test String')
print(md5.hexdigest())
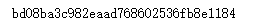
import hashlib md5 = hashlib.md5(b'Test String').hexdigest()
print(md5)
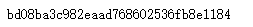
import os
import hashlib
import requests # url = "http://opendata.epa.gov.tw/ws/Data/REWXQA/?$orderby=SiteName&$skip=0&$top=1000&format=json"
url = "https://www.baidu.com" # 读取网页原始码
html=requests.get(url).text.encode('utf-8-sig')
# 判断网页是否更新
md5 = hashlib.md5(html).hexdigest()
if os.path.exists('F:\\pythonBase\\pythonex\\ch06\\old_md5.txt'):
with open('F:\\pythonBase\\pythonex\\ch06\\old_md5.txt', 'r') as f:
old_md5 = f.read()
with open('F:\\pythonBase\\pythonex\\ch06\\old_md5.txt', 'w') as f:
f.write(md5)
else:
with open('F:\\pythonBase\\pythonex\\ch06\\old_md5.txt', 'w') as f:
f.write(md5) if md5 != old_md5:
print('数据已更新...')
else:
print('数据未更新,从数据库读取...')

import os
import ast
import hashlib
import sqlite3
import requests from bs4 import BeautifulSoup conn = sqlite3.connect('F:\\pythonBase\\pythonex\\DataBasePM25.sqlite') # 建立数据库连接
cursor = conn.cursor() # 建立 cursor 对象 # 建立一个数据表
sqlstr='''
CREATE TABLE IF NOT EXISTS TablePM25 ("no" INTEGER PRIMARY KEY AUTOINCREMENT
NOT NULL UNIQUE ,"SiteName" TEXT NOT NULL ,"PM25" INTEGER)
'''
cursor.execute(sqlstr) url = "http://api.help.bj.cn/apis/aqilist/"
#html=requests.get(url).text.encode('utf-8-sig') # 读取网页原始码
html=requests.get(url).text.encode('iso-8859-1').decode('utf-8-sig')
# print(html)
html = html.encode('utf-8-sig')
# 判断网页是否更新
md5 = hashlib.md5(html).hexdigest()
old_md5 = "" if os.path.exists('F:\\pythonBase\\pythonex\\ch06\\old_md5-.txt'):
with open('F:\\pythonBase\\pythonex\ch06\\old_md5-.txt', 'r') as f:
old_md5 = f.read()
with open('F:\\pythonBase\\pythonex\ch06\\old_md5-.txt', 'w') as f:
f.write(md5)
print("old_md5="+old_md5+";"+"md5="+md5) #显示新老md5码进行观察
if md5 != old_md5:
print('数据已更新...')
sp=BeautifulSoup(html,'html.parser') #解析网页内容
jsondata = ast.literal_eval(sp.text) #此时jscondata取到的是字典类型数据
# 删除数据表内容
js1=jsondata.get("aqidata") #取出字典数据中的aqidata项的值(值是列表)
conn.execute("delete from TablePM25")
conn.commit()
n=1
for city in js1: #city此时是列表js1中的第一条字典数据
CityName=city["city"] #取出city字典数据中的值为"city"的key
if(city["pm2_5"] == ""):
PM25=0
else: #如果city字典中的key对应的value为空,则PM25=0,否则,把PM25=value
PM25=int(city["pm2_5"])
print("城市:{} PM2.5={}".format(CityName,PM25)) #显示城市对应的名称与PM2.5值
# 新增一笔记录
sqlstr="insert into TablePM25 values({},'{}',{})" .format(n,CityName,PM25)
cursor.execute(sqlstr)
n+=1
conn.commit() # 主动更新
else:
print('数据未更新,从数据库读取...')
cursor=conn.execute("select * from TablePM25")
rows=cursor.fetchall()
for row in rows:
print("城市:{} PM2.5={}".format(row[1],row[2])) conn.close() # 关闭数据库连

........................................................

import os
import ast
import hashlib
import sqlite3
import requests from bs4 import BeautifulSoup # cur_path=os.path.dirname(__file__) # 取得目前路径
# print(cur_path)
conn = sqlite3.connect('F:\\pythonBase\\pythonex\\' + 'DataBasePM25.sqlite') # 建立数据库连接
cursor = conn.cursor() # 建立 cursor 对象 # 建立一个数据表
sqlstr='''
CREATE TABLE IF NOT EXISTS TablePM25 ("no" INTEGER PRIMARY KEY AUTOINCREMENT
NOT NULL UNIQUE ,"SiteName" TEXT NOT NULL ,"PM25" INTEGER)
'''
cursor.execute(sqlstr) url = "http://api.help.bj.cn/apis/aqilist/"
# 读取网页原始码
# html=requests.get(url).text.encode('utf-8-sig')
html=requests.get(url).text.encode('iso-8859-1').decode('utf-8-sig')
# print(html)
html = html.encode('utf-8-sig') print('数据已更新...')
sp=BeautifulSoup(html,'html.parser') #sp是bs4.Beautifulsoup类
# 将网页内转换为 list,list 中的元素是 dict
jsondata = ast.literal_eval(sp.text) #把sp.text字符串转为dict类型
js=jsondata.get("aqidata") #从jasondata中取出值为"aqidata"的key对应的value的列表 # 删除数据表内容
conn.execute("delete from TablePM25")
conn.commit() #把抓到的数据逐条存到数据库
n=1
for city in js:
CityName=city["city"]
PM25=0 if city["pm2_5"] == "" else int(city["pm2_5"])
print("城市:{} PM2.5={}".format(CityName,PM25))
# 新增一条记录
sqlstr="insert into TablePM25 values({},'{}',{})" .format(n,CityName,PM25)
cursor.execute(sqlstr)
n+=1
conn.commit() # 主动更新
conn.close() # 关闭数据库连

from time import sleep
from selenium import webdriver urls = ['http://www.baidu.com','http://www.wsbookshow.com','http://news.sina.com.cn/'] browser = webdriver.Chrome()
browser.maximize_window
for url in urls:
browser.get(url)
sleep(3) browser.quit()
from selenium import webdriver #导入webdriver url='http://www.wsbookshow.com/bookshow/jc/bk/cxsj/12442.html' #以此链接为例
browser=webdriver.Chrome() #生成Chrome浏览器对象(结果是打开Chrome浏览器)
browser.get(url) #在浏览器中打开url
login_form=browser.find_element_by_id("menu_1") ##查找id="menu_1"的元素
print(login_form.text) #显示元素内容
#browser.quit() #退出浏览器,退出驱动程序
username=browser.find_element_by_name("username") #查找name="username"的元素
print(username)
password=browser.find_element_by_name("pwd") #查找name="pwd"的元素
print(password)
login_form=browser.find_element_by_xpath("//input[@name='arcID']")
print(login_form)
login_form=browser.find_element_by_xpath("//div[@id='feedback_userbox']")
print(login_form)
continue_link=browser.find_element_by_link_text('新概念美语')
print(continue_link)
continue_link=browser.find_element_by_link_text('英语')
print(continue_link)
heading1=browser.find_element_by_tag_name('h1')
print(heading1)
content=browser.find_elements_by_class_name('topbanner')
print(content)
content=browser.find_elements_by_css_selector('.topsearch')
print(content)
# print(content.get_property)
print()
browser.quit() #退出浏览器,退出驱动程序

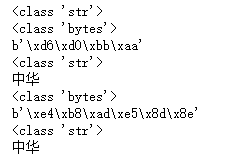
text = '中华'
print(type(text))#<class 'str'>
text1 = text.encode('gbk')
print(type(text1))#<class 'bytes'>
print(text1)#b'\xd6\xd0\xbb\xaa'
text2 = text1.decode('gbk')
print(type(text2))#<class 'str'>
print(text2)#中华 text4= text.encode('utf-8')
print(type(text4))#<class 'bytes'>
print(text4)#b'\xe4\xb8\xad\xe5\x8d\x8e'
text5 = text4.decode('utf-8')
print(type(text5))#<class 'str'>
print(text5)#中华
import requests url="http://www.baidu.com"
response = requests.get(url)
content = response.text.encode('iso-8859-1').decode('utf-8')
#把网页源代码解码成Unicode编码,然后用utf-8编码
print(content)

from selenium import webdriver # 导入webdriver模块 chrome_obj = webdriver.Chrome() # 打开Google浏览器
chrome_obj.get("https://www.baidu.com") # 打开 网址
print(chrome_obj.title)
from selenium import webdriver # 导入webdriver模块 chrome_obj = webdriver.Chrome() # 打开Google浏览器 chrome_obj.get(r"C:\desktop\text.html") # 打开本地 html页面
吴裕雄 python 爬虫(3)的更多相关文章
- 吴裕雄 python 爬虫(4)
import requests user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, li ...
- 吴裕雄 python 爬虫(2)
import requests from bs4 import BeautifulSoup url = 'http://www.baidu.com' html = requests.get(url) ...
- 吴裕雄 python 爬虫(1)
from urllib.parse import urlparse url = 'http://www.pm25x.com/city/beijing.htm' o = urlparse(url) pr ...
- 吴裕雄--python学习笔记:爬虫基础
一.什么是爬虫 爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息. 二.Python爬虫架构 Python 爬虫架构主要由五个部分组成,分别是调度器.URL管理器.网页下载器.网 ...
- 吴裕雄--python学习笔记:爬虫包的更换
python 3.x报错:No module named 'cookielib'或No module named 'urllib2' 1. ModuleNotFoundError: No module ...
- 吴裕雄--python学习笔记:爬虫
import chardet import urllib.request page = urllib.request.urlopen('http://photo.sina.com.cn/') #打开网 ...
- 吴裕雄 python 神经网络——TensorFlow pb文件保存方法
import tensorflow as tf from tensorflow.python.framework import graph_util v1 = tf.Variable(tf.const ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(4)
# -*- coding: utf-8 -*- import glob import os.path import numpy as np import tensorflow as tf from t ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(3)
import glob import os.path import numpy as np import tensorflow as tf from tensorflow.python.platfor ...
随机推荐
- Android Studio设置自定义字体
Android Studio设置自定义字体 (1)进入设置页面,File->Settings (2)自定义字体Editor->Colors&Fonts->Font (3)点击 ...
- MariaDB MaxScale
1. down https://mariadb.com/downloads/#mariadb_platform-mariadb_maxscale (1) install sudo yum locali ...
- SQLServer树查询
感觉这个CTE递归查询蛮好用的,先举个例子: use City; go create table Tree ( ID int identity(1,1) primary key not null, N ...
- gentoo samba 配置
准备搞一台 PC 作为 NAS, 开启 SAMBA 作为文件服务器.考虑多个手机自动备份到不同的文件夹,可以通过盒子进行播放,还要密码防护. 所以在配置文件里面 valid users 这里把 手机和 ...
- 转:SQL 操作结果集 -并集、差集、交集、结果集排序
为了配合测试,特地建了两个表,并且添加了一些测试数据,其中重复记录为东吴的人物. 表:Person_1魏国人物 表:Person_2蜀国人物 A.Union形成并集 Union可以对两个或多个结果集进 ...
- nodejs基础学习1
ES6常用新语法 ES6新语法 什么是ES6? 由于JavaScript是上个世纪90年代,由Brendan Eich在用了10天左右的时间发明的:虽然语言的设计者很牛逼,但是也扛不住"时间 ...
- python学习笔记_week9
一.paramiko模块 SSHClient,用于连接远程服务器并执行基本命令 基于用户名密码连接: ssh执行命令:stdin,stdout,sterr:标准输入.输出.错误 import para ...
- 图解HTTP / HTTPS
http://kb.cnblogs.com/page/155287/ 我们都知道HTTPS能够加密信息,以免敏感信息被第三方获取.所以很多银行网站或电子邮箱等等安全级别较高的服务都会采用HTTPS协议 ...
- Android自定义View学习笔记(一)
绘制基础 参考:HenCoder Android 开发进阶: 自定义 View 1-1 绘制基础 Paint详解 参考:HenCoder Android 开发进阶: 自定义 View 1-2 Pain ...
- Flex自定义组件、皮肤,并调用
标签:Flex 自定义组件 自定义皮肤 主应用调用模块 本程序样例学习自flex 实战教程.但因原教程代码不全,且根据个人需求有更改. 1文件列表 自定义as类Reveal.as,该类实现组件的 ...