吴裕雄 python 爬虫(1)
from urllib.parse import urlparse url = 'http://www.pm25x.com/city/beijing.htm'
o = urlparse(url)
print(o) print("scheme={}".format(o.scheme)) # http
print("netloc={}".format(o.netloc)) # www.pm25x.com
print("port={}".format(o.port)) # None
print("path={}".format(o.path)) # /city/beijing.htm
print("query={}".format(o.query)) # 空

import requests url = 'http://www.wsbookshow.com/'
html = requests.get(url)
html.encoding="GBK"
print(html.text)

import requests url = 'http://www.wsbookshow.com/'
html = requests.get(url)
html.encoding="gbk" htmllist = html.text.splitlines()
n=0
for row in htmllist:
if "新概念" in row:
n+=1
print("找到 {} 次!".format(n))
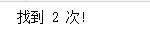
import re
pat = re.compile('[a-z]+') m = pat.match('tem12po')
print(m) if not m==None:
print(m.group())
print(m.start())
print(m.end())
print(m.span())

import re
m = re.match(r'[a-z]+','tem12po')
print(m) if not m==None:
print(m.group())
print(m.start())
print(m.end())
print(m.span())
import re
pat = re.compile('[a-z]+')
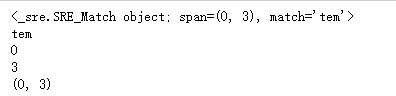
m = pat.search('3tem12po')
print(m) # <_sre.SRE_Match object; span=(1, 4), match='tem'>
if not m==None:
print(m.group()) # tem
print(m.start()) #
print(m.end()) #
print(m.span()) # (1,4)

import re
pat = re.compile('[a-z]+') m = pat.findall('tem12po')
print(m) # ['tem', 'po']
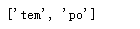
import requests,re
regex = re.compile('[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+')
url = 'http://www.wsbookshow.com/'
html = requests.get(url)
emails = regex.findall(html.text)
for email in emails:
print(email)

吴裕雄 python 爬虫(1)的更多相关文章
- 吴裕雄 python 爬虫(4)
import requests user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, li ...
- 吴裕雄 python 爬虫(3)
import hashlib md5 = hashlib.md5() md5.update(b'Test String') print(md5.hexdigest()) import hashlib ...
- 吴裕雄 python 爬虫(2)
import requests from bs4 import BeautifulSoup url = 'http://www.baidu.com' html = requests.get(url) ...
- 吴裕雄--python学习笔记:爬虫基础
一.什么是爬虫 爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息. 二.Python爬虫架构 Python 爬虫架构主要由五个部分组成,分别是调度器.URL管理器.网页下载器.网 ...
- 吴裕雄--python学习笔记:爬虫包的更换
python 3.x报错:No module named 'cookielib'或No module named 'urllib2' 1. ModuleNotFoundError: No module ...
- 吴裕雄--python学习笔记:爬虫
import chardet import urllib.request page = urllib.request.urlopen('http://photo.sina.com.cn/') #打开网 ...
- 吴裕雄 python 神经网络——TensorFlow pb文件保存方法
import tensorflow as tf from tensorflow.python.framework import graph_util v1 = tf.Variable(tf.const ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(4)
# -*- coding: utf-8 -*- import glob import os.path import numpy as np import tensorflow as tf from t ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(3)
import glob import os.path import numpy as np import tensorflow as tf from tensorflow.python.platfor ...
随机推荐
- python序列化模块
什么叫序列化——将原本的字典.列表等内容转换成一个字符串的过程就叫做序列化. 序列化的目的 1.以某种存储形式使自定义对象持久化: 2.将对象从一个地方传递到另一个地方. 3.使程序更具维护性. ...
- tips:Java中while的判断条件
tips:Java中while的判断条件! 在c++中,有时候会遇到这种情况: while(x = y){ dosomething; } 如果x与y相等,这个时候如果循环体中没有跳出的点,那么会无限循 ...
- Android原生和H5交互;Android和H5混合开发;WebView点击H5界面跳转到Android原生界面。
当时业务的需求是这样的,H5有一个活动商品列表的界面,IOS和Android共用这一个界面,点击商品可以跳转到Android原生的商品详情界面并传递商品ID: 大概就是点击H5界面跳转到Androi ...
- day25类的组合多态封装
类的组合多态与封装类的组合 1. 什么是组合 组合指的是某一个对象拥有一个属性,该属性的值是另外一个类的对象 2. 为何要用组合 通过为某一个对象添加属性(属性的值是另外一个类的对象)的方式,可以 ...
- DRF 视图组件,路由组件
视图组件 -- 第一次封装 -- GenericAPIView(APIView): queryset = None serializer_class = None def ge ...
- 自动创建表出错 type=InnDB
因为type=InnoDB在5.0以前是可以使用的,但5.1之后就不行了 只需要修改配置: hibernate.dialect=org.hibernate.dialect.MySQLInnoDBDia ...
- BZOJ4195 luoguP1955 NOI2015D1T1 程序自动分析
题意:给定n个(xi = xj) 或 (xi != xj) 的条件,问是否可能成立 BZOJ链接:http://www.lydsy.com/JudgeOnline/problem.php?id=419 ...
- django-BaseCommand自带的权限分组
note: 应该是这样的结构,并且commands名字是固定的. 执行: python manage.py initgroup initgroup.py # -*- coding: utf-8 - ...
- [Lua]弱引用table
参考链接: http://www.benmutou.com/archives/1808 一.强引用table lua中的table是引用类型,更准确地说,是强引用类型.如下第二段代码,在内存中有一个{ ...
- c#上传文件并将word pdf转化成txt存储并将内容写入数据库
c#上传文件并将word pdf转化成txt存储并将内容写入数据库 using System; using System.Data; using System.Configuration; using ...