【转载】 AI与人类首次空战,5:0大胜!40亿次模拟造美国怪兽,谁与争锋? (再次证明深度强化学习路线的正确性)
原文:
------------------------------------------------

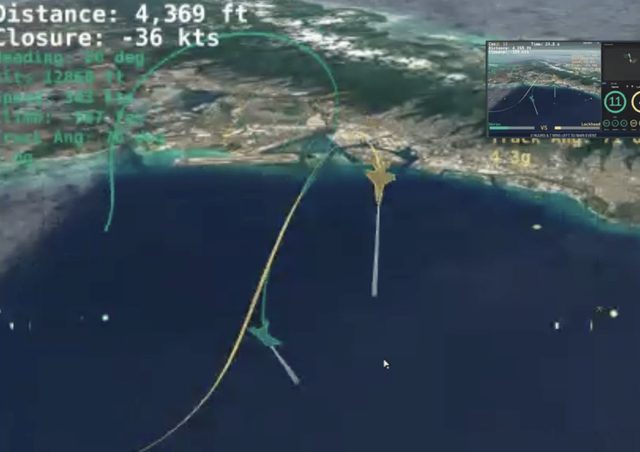
8月20日,美国苍鹭系统公司的人工智能空战系统,与一名坐在模拟器中、戴着虚拟现实头盔的人类战斗机飞行员进行空战格斗对抗,最后以5:0的绝对优势获胜。这场世界首次人工智能和人类的空战大赛,表明在空战近距格斗领域,人工智能可以超越人类。那么,人工智能是否会在空军作战中获得巨大发展呢?

2019年8月,国防高级研究开发局DARPA选择了八个团队,包括洛克希德·马丁公司这样的大型传统国防承包商到苍鹭系统公司(Heron Systems)这样的小公司,在11月和2020年1月的一系列试验中展开一系列竞争,最后苍鹭系统公司在与其他七支球队的较量中脱颖而出获得冠军,亚军洛克希德·马丁公司获得亚军。而20日人工智能对人类的胜利,再次证明 深度强化学习路线的正确性 。即人工智能算法可以在虚拟战争环境中一遍又一遍地训练一项空战任务,最终发展“理解”空战的层次。

来自洛克希德·马丁公司的人工智能副总裁马特·塔拉西奥和人工智能总监兼首席架构师李·里索尔茨表示,试图让算法在空战中表现良好,与简单地教软件“飞”或保持特定的方向、高度和速度有很大的不同。人工智能软件一开始甚至 对非常基本的飞行任务都完全缺乏理解,这使得它一开始十分“菜”。一个最普通的人也知道飞机它不应该撞到地面,但是算法不知道。在训练一开始,人工智能经常把飞机开到地面自杀,就像婴儿一样。
克服这种无知的“人工智能”,需要算法训练,每个错误都有代价,但这些代价并不相等。当算法基于仿真后的分析,能够为每个动作分配权重,然后随着经验的不断更新,能够重新分配这些权重,就能够逐渐加固人工智能的“战斗意识”。但是程序员在如何构建模拟方面的,存在有意识和无意识巨大争论。是 基于人类知识编写软件规则来约束人工智能,还是让 人工智能通过试错自我学习?这是一场激烈的辩论。最后美方选择第二种,因为人类的经验有可能限制了它的性能。

尽管已开始是菜鸟,但人工智能可以学习的速度有多快是令人震惊的,因为它可以在多台机器上一遍又一遍地重复训练。洛克希德公司和其他几个团队一样,有一名战斗机飞行员提供建议,还能够一次在多达25台服务器上训练人工智能。而苍鹭系统公司的人工智能算法,竟然经历了40亿次模拟,等于在1年的时间中获得了至少“12年资深战斗机飞行员的经验”。美国目标是最终生产的人工智能产品可以运行在一块GPU芯片上。
这不是人工智能第一次在比赛中击败人类战斗机飞行员。2016年的一次演示显示,一名为阿尔法的人工智能特工可以击败一名经验丰富的人类战斗飞行教官。但8月20日的模拟对抗意义更大,因为它让各种人工智能在高度结构化的框架中相互对抗,然后具备与人类对抗的能力。

而且人工智能厂商还认为,即便是5:0的结果,但实际上对他们来说并不公平,因为规则不允许在实际对抗中,人工智能来学习对手的经验。实际的比赛确实证实了这一点。在了第五轮也是最后一轮比赛时,匿名的人类飞行员已经能够显著改变他的战术,尽管最后失败了但持续的时间要长得多。显然人类战斗机飞行员也在学习,但是他学的而不够快,还是失败了。而人工智能公司认为,如果AI也能在战斗中学习人类对手,那么人类败得会更快更惨。

这一比赛,将促使美国军方将不得不对未来做出的重大选择。企业界建议,美国军方应该 允许人工智能在实战中学习更多,而不是简单计算机模拟,这样从而在人类的直接监督下,人工智能学习速度可能更快,并帮助无人驾驶战斗机更好地与人类飞行员或其他形态人工智能竞争。但这需要军方的决定,特别是在这一关键时刻做出决定。至少现在,美军应该训练算法,部署人工智能战机, 然后把数据带回来,加强学习,然后再次重新部署,不断循环这一过程。

DARPA战略技术办公室主任蒂莫西·格雷森认为,这场试验并不简单是人工智能的胜利,更准确的描述是更好的人机合作的胜利,格雷森说:“我认为我们今天看到的是一种我将称之为人机共生时代的开始。让我们想象一下,坐在驾驶舱里的 人类,被这些人工智能算法看做武器系统飞行的一部分。人工智能正在做人工智能最擅长的战斗。人类专注于人类最擅长的事情,比如更高层次的战略思维。”
----------------------------------------
【转载】 AI与人类首次空战,5:0大胜!40亿次模拟造美国怪兽,谁与争锋? (再次证明深度强化学习路线的正确性)的更多相关文章
- 【转载】 深度强化学习处理cartpole为什么reward很难超过200?
原贴地址: https://www.zhihu.com/question/266493753 一直在看强化学习方面的内容,cartpole是最简单的入门实验环境,最原始的评判标准是连续100次epis ...
- 强化学习——如何提升样本效率 ( DeepMind 综述深度强化学习:智能体和人类相似度竟然如此高!)
强化学习 如何提升样本效率 参考文章: https://news.html5.qq.com/article?ch=901201&tabId=0&tagId=0&docI ...
- 【转载】 “强化学习之父”萨顿:预测学习马上要火,AI将帮我们理解人类意识
原文地址: https://yq.aliyun.com/articles/400366 本文来自AI新媒体量子位(QbitAI) ------------------------------- ...
- 【转载】 准人工智能分享Deep Mind报告 ——AI“元强化学习”
原文地址: https://www.sohu.com/a/231895305_200424 ------------------------------------------------------ ...
- AI 学习路线
[导读] 本文由知名开源平台,AI技术平台以及领域专家:Datawhale,ApacheCN,AI有道和黄海广博士联合整理贡献,内容涵盖AI入门基础知识.数据分析挖掘.机器学习.深度学习.强化学习.前 ...
- 【转载】 强化学习(八)价值函数的近似表示与Deep Q-Learning
原文地址: https://www.cnblogs.com/pinard/p/9714655.html ------------------------------------------------ ...
- 【转载】 强化学习(七)时序差分离线控制算法Q-Learning
原文地址: https://www.cnblogs.com/pinard/p/9669263.html ------------------------------------------------ ...
- 【转载】 强化学习(五)用时序差分法(TD)求解
原文地址: https://www.cnblogs.com/pinard/p/9529828.html ------------------------------------------------ ...
- ICML论文|阿尔法狗CTO讲座: AI如何用新型强化学习玩转围棋扑克游戏
今年8月,Demis Hassabis等人工智能技术先驱们将来到雷锋网“人工智能与机器人创新大会”.在此,我们为大家分享David Silver的论文<不完美信息游戏中的深度强化学习自我对战&g ...
- 【转载】 DeepMind发表Nature子刊新论文:连接多巴胺与元强化学习的新方法
原文地址: baijiahao.baidu.com/s?id=1600509777750939986&wfr=spider&for=pc 机器之心 18-05-15 14:26 - ...
随机推荐
- kafka事务流程
流程 kafka事务使用的5个API // 1. 初始化事务 void initTransactions(); // 2. 开启事务 void beginTransaction() throws Pr ...
- java+SpringCloud开发的性能和环保问题
对于大部分商业应用开发程序员而言,使用java+spring是一件幸福的事情. 一般情况下,我们使用cloud开发不是那么重要.精密的应用,这些应用包括例如大型的商业交易,社区等等. 因为这些应用天然 ...
- ThreadLocal 源码浅析
前言 多线程在访问同一个共享变量时很可能会出现并发问题,特别是在多线程对共享变量进入写入时,那么除了加锁还有其他方法避免并发问题吗?本文将详细讲解 ThreadLocal 的使用及其源码. 一.什么是 ...
- HarmonyOS SDK助力鸿蒙原生应用“易感知、易理解、易操作”
6月21-23日,华为开发者大会(HDC 2024)盛大开幕.6月23日上午,<HarmonyOS开放能力,使能应用原生易用体验>分论坛成功举办,大会邀请了多位华为技术专家深度解读如何通过 ...
- 记录一次EF实体跟踪错误
记录一次EF实体跟踪错误 前言 在我写文章编辑接口的,出现了一个实体跟踪的错误,详情如下 System.InvalidOperationException: The instance of entit ...
- Linux 内核:设备驱动模型(4)uevent与热插拔
Linux 内核:设备驱动模型(4)uevent与热插拔 背景 我们简单回顾一下Linux的设备驱动模型(Linux Device Driver Model,LDDM): 1.在<sysfs与k ...
- 卷积神经网络中nn.Conv2d()和nn.MaxPool2d()以及卷积神经网络实现minist数据集分类
卷积神经网络中nn.Conv2d()和nn.MaxPool2d() 卷积神经网络之Pythorch实现: nn.Conv2d()就是PyTorch中的卷积模块 参数列表 参数 作用 in_channe ...
- P3749 题解
既然是求最大值而且有收益有代价,所以考虑建立一个最大权封闭子图模型. 收益 正的美味值是收益,所以假若 \(d_{i,j} \geq 0\) 则建边 \((s,pos_{i,j},d_{i,j})\) ...
- python3 json.dumps(OrderDict类型) 报错:TypeError: Object of type datetime is not JSON serializable
chatgpt给出的解决方案, 在json.dumps()函数调用中传入default参数来指定如何处理datetime对象 import json from datetime import date ...
- DDP:微软提出动态detection head选择,适配计算资源有限场景 | CVPR 2022
DPP能够对目标检测proposal进行非统一处理,根据proposal选择不同复杂度的算子,加速整体推理过程.从实验结果来看,效果非常不错 来源:晓飞的算法工程笔记 公众号 论文: Should A ...