Seaborn分布数据可视化---箱型分布图
箱型分布图
boxplot()
sns.boxplot(
x=None,
y=None,
hue=None,
data=None,
order=None,
hue_order=None,
orient=None,
color=None,
palette=None,
saturation=0.75,
width=0.8,
dodge=True,
fliersize=5,
linewidth=None,
whis=1.5,
notch=False,
ax=None,
**kwargs,
)
Docstring:
Draw a box plot to show distributions with respect to categories.
A box plot (or box-and-whisker plot) shows the distribution of quantitative
data in a way that facilitates comparisons between variables or across
levels of a categorical variable. The box shows the quartiles of the
dataset while the whiskers extend to show the rest of the distribution,
except for points that are determined to be "outliers" using a method
that is a function of the inter-quartile range.
Input data can be passed in a variety of formats, including:
- Vectors of data represented as lists, numpy arrays, or pandas Series
objects passed directly to the ``x``, ``y``, and/or ``hue`` parameters.
- A "long-form" DataFrame, in which case the ``x``, ``y``, and ``hue``
variables will determine how the data are plotted.
- A "wide-form" DataFrame, such that each numeric column will be plotted.
- An array or list of vectors.
In most cases, it is possible to use numpy or Python objects, but pandas
objects are preferable because the associated names will be used to
annotate the axes. Additionally, you can use Categorical types for the
grouping variables to control the order of plot elements.
This function always treats one of the variables as categorical and
draws data at ordinal positions (0, 1, ... n) on the relevant axis, even
when the data has a numeric or date type.
See the :ref:`tutorial <categorical_tutorial>` for more information.
Parameters
----------
x, y, hue : names of variables in ``data`` or vector data, optional
Inputs for plotting long-form data. See examples for interpretation.
data : DataFrame, array, or list of arrays, optional
Dataset for plotting. If ``x`` and ``y`` are absent, this is
interpreted as wide-form. Otherwise it is expected to be long-form.
order, hue_order : lists of strings, optional
Order to plot the categorical levels in, otherwise the levels are
inferred from the data objects.
orient : "v" | "h", optional
Orientation of the plot (vertical or horizontal). This is usually
inferred from the dtype of the input variables, but can be used to
specify when the "categorical" variable is a numeric or when plotting
wide-form data.
color : matplotlib color, optional
Color for all of the elements, or seed for a gradient palette.
palette : palette name, list, or dict, optional
Colors to use for the different levels of the ``hue`` variable. Should
be something that can be interpreted by :func:`color_palette`, or a
dictionary mapping hue levels to matplotlib colors.
saturation : float, optional
Proportion of the original saturation to draw colors at. Large patches
often look better with slightly desaturated colors, but set this to
``1`` if you want the plot colors to perfectly match the input color
spec.
width : float, optional
Width of a full element when not using hue nesting, or width of all the
elements for one level of the major grouping variable.
dodge : bool, optional
When hue nesting is used, whether elements should be shifted along the
categorical axis.
fliersize : float, optional
Size of the markers used to indicate outlier observations.
linewidth : float, optional
Width of the gray lines that frame the plot elements.
whis : float, optional
Proportion of the IQR past the low and high quartiles to extend the
plot whiskers. Points outside this range will be identified as
outliers.
notch : boolean, optional
Whether to "notch" the box to indicate a confidence interval for the
median. There are several other parameters that can control how the
notches are drawn; see the ``plt.boxplot`` help for more information
on them.
ax : matplotlib Axes, optional
Axes object to draw the plot onto, otherwise uses the current Axes.
kwargs : key, value mappings
Other keyword arguments are passed through to ``plt.boxplot`` at draw
time.
Returns
-------
ax : matplotlib Axes
Returns the Axes object with the plot drawn onto it.
See Also
--------
violinplot : A combination of boxplot and kernel density estimation.
stripplot : A scatterplot where one variable is categorical. Can be used
in conjunction with other plots to show each observation.
swarmplot : A categorical scatterplot where the points do not overlap. Can
be used with other plots to show each observation.
#设置风格
sns.set_style('white')
#导入数据
tip_datas = sns.load_dataset('tips', data_home='seaborn-data')
# 绘制传统的箱型图
sns.boxplot(x='day', y='total_bill', data=tip_datas,
linewidth=2, #线宽
width=0.8, #箱之间的间隔比例
fliersize=3, #异常点大小
palette='hls', #设置调色板
whis=1.5, #设置IQR
notch=True, #设置中位值凹陷
order=['Thur','Fri','Sat','Sun'], #选择类型并排序
)
# 绘制箱型图
sns.boxplot(x='day', y='total_bill', data=tip_datas,
linewidth=2,
width=0.8,
fliersize=3,
palette='hls',
whis=1.5,
notch=True,
order=['Thur','Fri','Sat','Sun'],
)
#添加散点图
sns.swarmplot(x='day', y='total_bill', data=tip_datas, color='k', size=3, alpha=0.8)
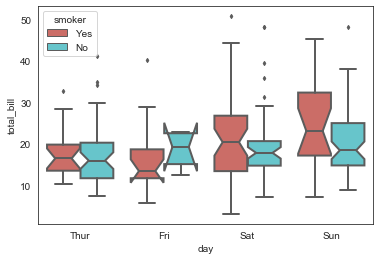
# 绘制箱型图,hue参数设置再分类
sns.boxplot(x='day', y='total_bill', data=tip_datas,
linewidth=2,
width=0.8,
fliersize=3,
palette='hls',
whis=1.5,
notch=True,
order=['Thur','Fri','Sat','Sun'],
hue='smoker',
)
violinplot()
sns.violinplot(x='day', y='total_bill', data=tip_datas,
linewidth=2,
width=0.8,
palette='hls',
order=['Thur','Fri','Sat','Sun'],
scale='area', #设置提琴宽度:area-面积相同,count-按照样本数量决定宽度,width-宽度一样
gridsize=50, #设置提琴图的边线平滑度,越高越平滑
inner='box', #设置内部显示类型--"box","quartile","point","stick",None
bw=0.8 #控制拟合程度,一般可以不设置
)
sns.violinplot(x='day', y='total_bill', data=tip_datas,
linewidth=2,
width=0.8,
palette='hls',
order=['Thur','Fri','Sat','Sun'],
scale='width',
gridsize=50,
inner='quartile', #内部标记分位线
bw=0.8
)
sns.violinplot(x='day', y='total_bill', data=tip_datas,
linewidth=2,
width=0.8,
palette='hls',
order=['Thur','Fri','Sat','Sun'],
scale='width',
gridsize=50,
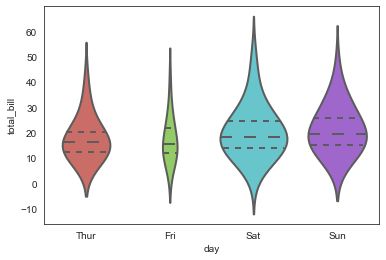
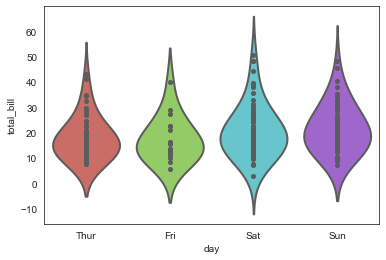
inner='point', #内部添加散点
bw=0.8
)
sns.violinplot(x='day', y='total_bill', data=tip_datas,
linewidth=2,
width=0.8,
palette='hls',
order=['Thur','Fri','Sat','Sun'],
scale='width',
gridsize=50,
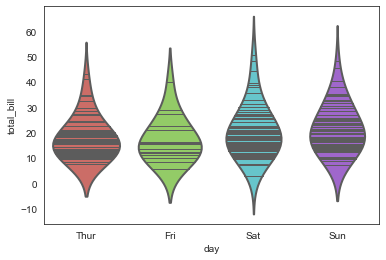
inner='stick', #内部添加细横线
bw=0.8
)
boxenplot()
sns.boxenplot(
x=None,
y=None,
hue=None,
data=None,
order=None,
hue_order=None,
orient=None,
color=None,
palette=None,
saturation=0.75,
width=0.8,
dodge=True,
k_depth='proportion',
linewidth=None,
scale='exponential',
outlier_prop=None,
ax=None,
**kwargs,
)
Docstring:
Draw an enhanced box plot for larger datasets.
This style of plot was originally named a "letter value" plot because it
shows a large number of quantiles that are defined as "letter values". It
is similar to a box plot in plotting a nonparametric representation of a
distribution in which all features correspond to actual observations. By
plotting more quantiles, it provides more information about the shape of
the distribution, particularly in the tails. For a more extensive
explanation, you can read the paper that introduced the plot:
https://vita.had.co.nz/papers/letter-value-plot.html
Input data can be passed in a variety of formats, including:
- Vectors of data represented as lists, numpy arrays, or pandas Series
objects passed directly to the ``x``, ``y``, and/or ``hue`` parameters.
- A "long-form" DataFrame, in which case the ``x``, ``y``, and ``hue``
variables will determine how the data are plotted.
- A "wide-form" DataFrame, such that each numeric column will be plotted.
- An array or list of vectors.
In most cases, it is possible to use numpy or Python objects, but pandas
objects are preferable because the associated names will be used to
annotate the axes. Additionally, you can use Categorical types for the
grouping variables to control the order of plot elements.
This function always treats one of the variables as categorical and
draws data at ordinal positions (0, 1, ... n) on the relevant axis, even
when the data has a numeric or date type.
See the :ref:`tutorial <categorical_tutorial>` for more information.
Parameters
----------
x, y, hue : names of variables in ``data`` or vector data, optional
Inputs for plotting long-form data. See examples for interpretation.
data : DataFrame, array, or list of arrays, optional
Dataset for plotting. If ``x`` and ``y`` are absent, this is
interpreted as wide-form. Otherwise it is expected to be long-form.
order, hue_order : lists of strings, optional
Order to plot the categorical levels in, otherwise the levels are
inferred from the data objects.
orient : "v" | "h", optional
Orientation of the plot (vertical or horizontal). This is usually
inferred from the dtype of the input variables, but can be used to
specify when the "categorical" variable is a numeric or when plotting
wide-form data.
color : matplotlib color, optional
Color for all of the elements, or seed for a gradient palette.
palette : palette name, list, or dict, optional
Colors to use for the different levels of the ``hue`` variable. Should
be something that can be interpreted by :func:`color_palette`, or a
dictionary mapping hue levels to matplotlib colors.
saturation : float, optional
Proportion of the original saturation to draw colors at. Large patches
often look better with slightly desaturated colors, but set this to
``1`` if you want the plot colors to perfectly match the input color
spec.
width : float, optional
Width of a full element when not using hue nesting, or width of all the
elements for one level of the major grouping variable.
dodge : bool, optional
When hue nesting is used, whether elements should be shifted along the
categorical axis.
k_depth : "proportion" | "tukey" | "trustworthy", optional
The number of boxes, and by extension number of percentiles, to draw.
All methods are detailed in Wickham's paper. Each makes different
assumptions about the number of outliers and leverages different
statistical properties.
linewidth : float, optional
Width of the gray lines that frame the plot elements.
scale : "linear" | "exponential" | "area"
Method to use for the width of the letter value boxes. All give similar
results visually. "linear" reduces the width by a constant linear
factor, "exponential" uses the proportion of data not covered, "area"
is proportional to the percentage of data covered.
outlier_prop : float, optional
Proportion of data believed to be outliers. Used in conjunction with
k_depth to determine the number of percentiles to draw. Defaults to
0.007 as a proportion of outliers. Should be in range [0, 1].
ax : matplotlib Axes, optional
Axes object to draw the plot onto, otherwise uses the current Axes.
kwargs : key, value mappings
Other keyword arguments are passed through to ``plt.plot`` and
``plt.scatter`` at draw time.
Returns
-------
ax : matplotlib Axes
Returns the Axes object with the plot drawn onto it.
See Also
--------
violinplot : A combination of boxplot and kernel density estimation.
boxplot : A traditional box-and-whisker plot with a similar API.
#单变量简易图
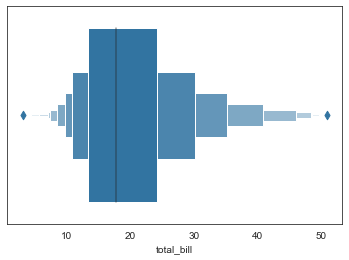
ax = sns.boxenplot(x=tip_datas['total_bill'])
#多变量箱型图
ax = sns.boxenplot(x='day', y='total_bill', data=tip_datas)

#多变量分类箱型图,hue
ax = sns.boxenplot(x='day', y='total_bill',
data=tip_datas,hue='smoker'
)
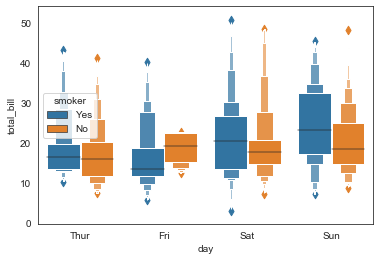
#多变量分类箱型图,hue
ax = sns.boxenplot(x='day', y='total_bill',
data=tip_datas,hue='time',
linewidth=2.5)
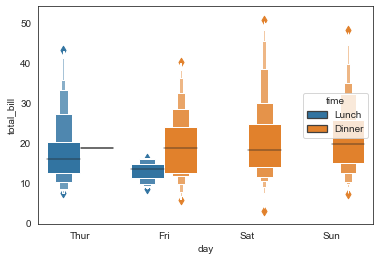
#多变量排序箱型图,order
ax = sns.boxenplot(x='time', y='tip',
data=tip_datas,order=['Dinner','Lunch']
)
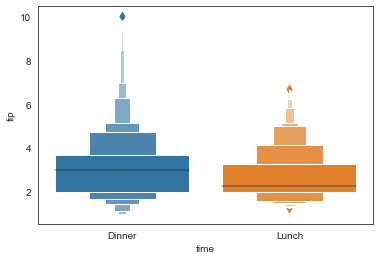
ax = sns.boxenplot(x='day', y='total_bill',
data=tip_datas)
#添加散点图
ax = sns.stripplot(x='day', y='total_bill', data=tip_datas,
size=4,jitter=True, color="gray"
)
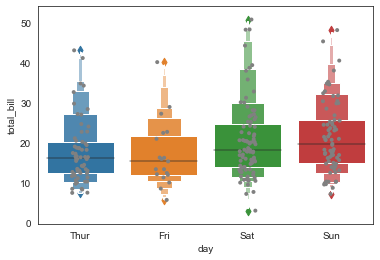
#分栏箱型图
g = sns.catplot(x="sex", y="total_bill",
hue="smoker", col="time",
data=tip_datas, kind="boxen",
height=4, aspect=.7)
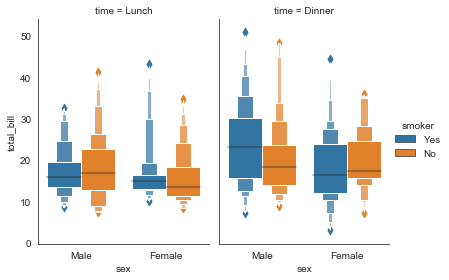
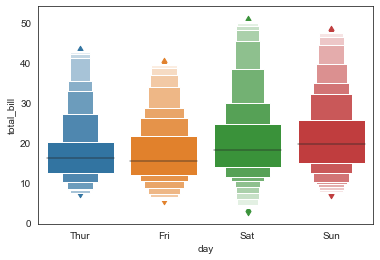
#其他参数,scale\k_depth
sns.boxenplot(x='day', y='total_bill', data=tip_datas,
width=0.8,
linewidth=12,
scale='area', #设置框大小:"linear"、"exponential"、"area"
k_depth='proportion', #设置框的数量: "proportion"、"tukey"、"trustworthy"
)
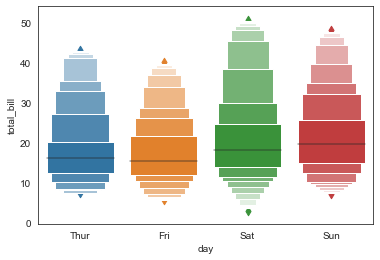
sns.boxenplot(x='day', y='total_bill', data=tip_datas,
width=0.8,
linewidth=12,
scale='linear', #设置框大小:"linear"、"exponential"、"area"
k_depth='proportion', #设置框的数量: "proportion"、"tukey"、"trustworthy"
)
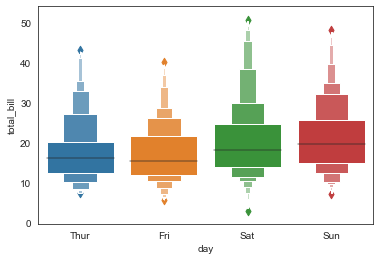
sns.boxenplot(x='day', y='total_bill', data=tip_datas,
width=0.8,
linewidth=12,
scale='exponential', #设置框大小:"linear"、"exponential"、"area"
k_depth='proportion', #设置框的数量: "proportion"、"tukey"、"trustworthy"
)
#多变量横向箱型图,orient
iris_datas = sns.load_dataset('iris', data_home='seaborn-data')
ax = sns.boxenplot(data=iris_datas, orient='h')
Seaborn分布数据可视化---箱型分布图的更多相关文章
- seaborn分布数据可视化:直方图|密度图|散点图
系统自带的数据表格(存放在github上https://github.com/mwaskom/seaborn-data),使用时通过sns.load_dataset('表名称')即可,结果为一个Dat ...
- Python图表数据可视化Seaborn:1. 风格| 分布数据可视化-直方图| 密度图| 散点图
conda install seaborn 是安装到jupyter那个环境的 1. 整体风格设置 对图表整体颜色.比例等进行风格设置,包括颜色色板等调用系统风格进行数据可视化 set() / se ...
- Python图表数据可视化Seaborn:2. 分类数据可视化-分类散点图|分布图(箱型图|小提琴图|LV图表)|统计图(柱状图|折线图)
1. 分类数据可视化 - 分类散点图 stripplot( ) / swarmplot( ) sns.stripplot(x="day",y="total_bill&qu ...
- seaborn分类数据可视化:散点图|箱型图|小提琴图|lv图|柱状图|折线图
一.散点图stripplot( ) 与swarmplot() 1.分类散点图stripplot( ) 用法stripplot(x=None, y=None, hue=None, data=None, ...
- seaborn分类数据可视化
转载:https://cloud.tencent.com/developer/article/1178368 seaborn针对分类型的数据有专门的可视化函数,这些函数可大致分为三种: 分类数据散点图 ...
- seaborn线性关系数据可视化:时间线图|热图|结构化图表可视化
一.线性关系数据可视化lmplot( ) 表示对所统计的数据做散点图,并拟合一个一元线性回归关系. lmplot(x, y, data, hue=None, col=None, row=None, p ...
- 用seaborn对数据可视化
以下用sns作为seaborn的别名 1.seaborn整体布局设置 sns.set_syle()函数设置图的风格,传入的参数可以是"darkgrid", "whiteg ...
- Python Seaborn综合指南,成为数据可视化专家
概述 Seaborn是Python流行的数据可视化库 Seaborn结合了美学和技术,这是数据科学项目中的两个关键要素 了解其Seaborn作原理以及使用它生成的不同的图表 介绍 一个精心设计的可视化 ...
- Seaborn数据可视化入门
在本节学习中,我们使用Seaborn作为数据可视化的入门工具 Seaborn的官方网址如下:http://seaborn.pydata.org 一:definition Seaborn is a Py ...
- 第六篇:R语言数据可视化之数据分布图(直方图、密度曲线、箱线图、等高线、2D密度图)
数据分布图简介 中医上讲看病四诊法为:望闻问切.而数据分析师分析数据的过程也有点相似,我们需要望:看看数据长什么样:闻:仔细分析数据是否合理:问:针对前两步工作搜集到的问题与业务方交流:切:结合业务方 ...
随机推荐
- 【Azure 环境】记录使用Notification Hub,安卓手机收不到Push通知时的错误,Error_Code 30602 or 30608
问题描述 使用Azure Notification Hub + Baidu 推送遇见的两次报错为: 1. {"request_id":2921358089,"error_ ...
- 【Azure Redis 缓存】如何使得Azure Redis可以仅从内网访问? Config 及 Timeout参数配置
问题描述 问题一:Redis服务,如何可以做到仅允许特定的子网内的服务器进行访问? 问题二:Redis服务,timeout和keepalive的设置是怎样的?是否可以配置成timeout 0? 问题三 ...
- Nebula Graph|信息图谱在携程酒店的应用
本文首发于 Nebula Graph Community 公众号 对于用户的每一次查询,都能根据其意图做到相应的场景和产品的匹配",是携程酒店技术团队的目标,但实现这个目标他们遇到了三大问题 ...
- C++ //谓词 //一元谓词 //概念:返回bool类型的仿函数称为 谓词 //如果 operator()接受一个参数,那么叫做一元谓词 //如果 operator()接受 2 个参数,那么叫做一元谓词
1 //谓词 2 //一元谓词 3 //概念:返回bool类型的仿函数称为 谓词 4 //如果 operator()接受一个参数,那么叫做一元谓词 5 //如果 operator()接受 2 个参数, ...
- Win10系统winload.efi丢失或损坏怎么办?修复步骤(以联想笔记本为例)
winload.efi是通过UEFI方式引导必要的引导文件,如果系统中丢失或是损坏将导致系统无法启动,如win10在出现这样的问题时会出现蓝屏恢复界面,那么此时该如何解决呢?此例为 GPT+UEFI ...
- 文心一言 VS 讯飞星火 VS chatgpt (210)-- 算法导论16.1 1题
一.根据递归式(16.2)为活动选择问题设计一个动态规划算法.算法应该按前文定义计算最大兼容活动集的大小 c[i,j]并生成最大集本身.假定输入的活动已按公式(16.1)排好序.比较你的算法和GREE ...
- Gavvmal
Gavvmal springboot 官方文档说明了两种方式,一种使用插件,直接生成docker镜像,但是这需要本地安装docker环境,但是无论用windows还是mac,本地安装docker都感觉 ...
- Java面经知识点图谱总结
未完待续~~~
- Seata的技术调研
引子 本文不剖析业内分布式组件,只剖析seata这一组件的技术调研.看看是否存在接入价值. 一.概述 Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务.Seata ...
- 基于RocketMQ实现分布式事务
背景 在一个微服务架构的项目中,一个业务操作可能涉及到多个服务,这些服务往往是独立部署,构成一个个独立的系统.这种分布式的系统架构往往面临着分布式事务的问题.为了保证系统数据的一致性,我们需要确保这些 ...