Centos 7下Hadoop分布式集群搭建
一、关闭防火墙(直接用root用户)
#关闭防火墙
sudo systemctl stop firewalld.service
#关闭开机启动
sudo systemctl disable firewalld.service

二、修改每台主机的Hostname(三台主机都一样)
vim /etc/hosts
注释原有的内容,加入如下内容,ip地址为你自己的虚拟机的IP地址:

more /etc/hosts查看是否正确,需要重启后方能生效。重启命令reboot now
more /etc/hosts
reboot now
三、免密登陆
1.给3个机器生成密钥文件
由于Namenode会执行一系列脚本去控制Datanode,因此需要设置SSH免密钥登录,省去输入密码的麻烦。
ssh-keygen -t rsa -P ''

2.生成SSH KEY并将其拷贝到各个节点主机上
依次执行如下命令:
ssh-keygen
ssh-copy-id Master-huyaqiong #免密钥登录本机
ssh-copy-id Slave1-huyaqiong
ssh-copy-id Slave2-huyaqiong
3.进行免密码登陆测试

四、安装JDK
1.下载JDK,
我下载的版本为:jdk-8u191-linux-x64.rpm
2.安装
rpm -ivh jdk-8u191-linux-x64.rpm
3.配置环境变量
export JAVA_HOME=/usr/java/default
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar
4.使环境变量生效
执行如下命令:
source /etc/profile
5.选择正确的JDK版本
为防止系统里存在多个版本的JDK,需要使用alternatives选择正确的版本:
alternatives --config java
请选择/usr/java/jdk1.8.0_71/jre/bin/java对应的数字标号。
查看java版本
Java -version

五 安装hadoop
本步骤需要在每个节点下载和安装hadoop,并做简单的配置。
1.安装Hadoop
tar zxvf hadoop-2.7..tar.gz -C /usr/hadoop --strip-components
2.配置环境变量
打开~/.bashrc文件,在文件末添加如下内容:
export HADOOP_HOME=/usr/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native" export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
3.使环境变量生效
source ~/.bashrc
六. 配置hadoop
1.首先登陆到Master节点
2.创建Datanode文件目录
mkdir ~/datanode
# 远程到Datanode节点创建对应的目录
ssh Slave1-huyaqiong "mkdir ~/datanode"
ssh Slave2-huyaqiong "mkdir ~/datanode"
3.配置hdfs
首先打开/usr/hadoop/etc/hadoop /hdfs-site.xml文件,在<configuration>
</configuration>之间添加如下内容:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/hadoop/datanode</value>
</property>
4.将配置文件同步到Datanode
scp /usr/hadoop/etc/hadoop hdfs-site.xml root@172.20.20.110:/usr/hadoop/etc/hadoop
scp /usr/hadoop/etc/hadoop hdfs-site.xml root@172.20.20.249:/usr/hadoop/etc/hadoop
5.配置hadoop core
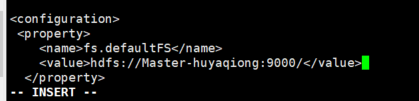
首先打开/usr/hadoop/etc/hadoop/core-site.xml文件,在<configuration> - </configuration>之间添加如下内容:
6.在hadoop中设置JAVA_HOME环境变量
首先通过如下命令在本机修改hadoop-env.sh文件中的环境变量:
sed -i -e 's/\${JAVA_HOME}/\/usr\/java\/default/' /usr/hadoop/etc/hadoop/hadoop-env.sh
7.配置文件同步到Datanode
scp /usr/hadoop/etc/hadoop/hadoop-env.sh root@172.20.20.107:/usr/hadoop/etc/hadoop/
scp /usr/hadoop/etc/hadoop/hadoop-env.sh root@172.20.20.249:/usr/hadoop/etc/hadoop/
8.创建Namenode文件目录
本步骤只需在Namenode上操作。
首先创建目录:
mkdir /root/Namenode
9.配置hdfs-site.xml
编辑usr/hadoop//etc/hadoop/hdfs-site.xml文件,增加如下的配置项:
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/hadoop/namenode</value>
</property>
10.配置map-reduce
本步骤只需在Namenode上操作,打开/ usr/hadoop/etc/hadoop/mapred-site.xml文件,新增如下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
11.配置yarn
首先打开/ usr/hadoop/etc/hadoop/yarn-site.xml文件,在<configuration> - </configuration>之间添加如下内容:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master-huyaqiong</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
12.将配置文件同步到Datanode:
scp yarn-site.xml root@172.20.20.249://usr/hadoop/etc/hadoop scp yarn-site.xml root@172.20.20.110://usr/hadoop/etc/hadoop
13.配置slave
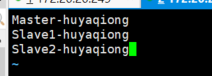
打开etc/hadoop/slaves文件,添加如下内容:
七、启动验证
分别启动hdfs和yarn服务: 运行示例进行验证
start-dfs.sh
start-yarn.sh

在Namenode上运行jps命令,应该会看到如下进程:

在Datanode上运行jps命令,应该会看到如下进程:

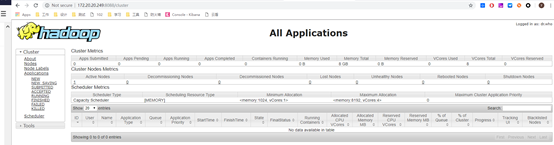
通过web界面查看:
访问http://172.20.20.249:8088/,可以看到如下图所示的页面,用来监控任务的执行情况:
Centos 7下Hadoop分布式集群搭建的更多相关文章
- [过程记录]Centos7 下 Hadoop分布式集群搭建
过程如下: 配置hosts vim /etc/hosts 格式: ip hostname ip hostname 设置免密登陆 首先:每台主机使用ssh命令连接其余主机 ssh 用户名@主机名 提示是 ...
- Hadoop分布式集群搭建
layout: "post" title: "Hadoop分布式集群搭建" date: "2017-08-17 10:23" catalog ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- Hadoop框架:单服务下伪分布式集群搭建
本文源码:GitHub·点这里 || GitEE·点这里 一.基础环境 1.环境版本 环境:centos7 hadoop版本:2.7.2 jdk版本:1.8 2.Hadoop目录结构 bin目录:存放 ...
- hadoop分布式集群搭建(2.9.1)
1.环境 操作系统:ubuntu16 jdk:1.8 hadoop:2.9.1 机器:3台,master:192.168.199.88,node1:192.168.199.89,node2:192.1 ...
- hadoop分布式集群搭建前期准备(centos7)
那玩大数据,想做个大数据的从业者,必须了解在生产环境下搭建集群哇?由于hadoop是apache上的开源项目,所以版本有些混乱,听说都在用Cloudera的cdh5来弄?后续研究这个吧,就算这样搭建不 ...
- Hadoop分布式集群搭建_1
Hadoop是一个开源的分布式系统框架 一.集群准备 1. 三台虚拟机,操作系统Centos7,三台主机名分别为k1,k2,k3,NAT模式 2.节点分布 k1: NameNode DataNode ...
- 使用Docker在本地搭建Hadoop分布式集群
学习Hadoop集群环境搭建是Hadoop入门必经之路.搭建分布式集群通常有两个办法: 要么找多台机器来部署(常常找不到机器) 或者在本地开多个虚拟机(开销很大,对宿主机器性能要求高,光是安装多个虚拟 ...
- 分布式计算(一)Ubuntu搭建Hadoop分布式集群
最近准备接触分布式计算,学习分布式计算的技术栈和架构知识.目前的分布式计算方式大致分为两种:离线计算和实时计算.在大数据全家桶中,离线计算的优秀工具当属Hadoop和Spark,而实时计算的杰出代表非 ...
随机推荐
- mobilenetV3
1.MobilenetV3是通过NAS得到的,结合了v1,v2和MnasNet的结构,包括v1的dw,v2的linear bottleneck和逆残差结构, MnasNet的se结构(接在部分line ...
- vue 之 双向绑定原理
一.实现双向绑定 详细版: 前端MVVM实现双向数据绑定的做法大致有如下三种: 1.发布者-订阅者模式(backbone.js) 思路:使用自定义的data属性在HTML代码中指明绑定.所有绑定起来的 ...
- vue2.0 之 过渡动画transtion
过渡的类名: 在进入/离开的过渡中,会有 6 个 class 切换 (v 是前缀,name = v) v-enter:定义进入过渡的开始状态.在元素被插入时生效,在下一个帧移除. v-enter-ac ...
- Centos7.5 源码编译安装PHP
安装依赖 yum -y install epel-release yum -y install gcc gcc-c++ make pcre pcre-devel zlib zlib-devel op ...
- django之表单类
一:表单类 一般我们在html中自己写的表单类似于下面的样子 <!DOCTYPE html> <html lang="en"> <head> & ...
- 查看jar包内容
查看jar包内容 查看jar包内容的基本命令: jar tf jar-file 参数解释: The t option indicates that you want to view the table ...
- java:集合输出之Iterator和ListIterator
在调用Iterator集合输出时,如果想要删除某个元素,请直接使用Iterator来判断元素是否存在然后再删除(next()当前指针内容,remove()删除当前内容 );如果在将集合丢给Iterat ...
- CSS——相对定位、绝对定位、固定定位
相对定位: position:relative 当元素被设置相对定位或是绝对定位后,将自动产生层叠,他们的层叠级别自然的高于文本流,除非设置其z-index值为负值. 并且我们发现当相对定位元素进行位 ...
- Spring配置文件出错
问题描述: Element 'xxxxxxx' cannot have character [children],because the type's content type is element- ...
- Linux内核设计与实现 总结笔记(第十六章)页高速缓存和页回写
页高速缓存是Linux内核实现磁盘缓存.磁盘告诉缓存重要源自:第一,访问磁盘的速度要远远低于访问内存. 第二,数据一旦被访问,就很有可能在短期内再次被访问到.这种短时期内集中访问同一片数据的原理称作临 ...